
 Logo:
Logo:  Areas Served:
Areas Served: 
RNN: Basic Recursive Neural Network for sentiment analysis in PyTorch
Last Updated on June 10, 2024 by Editorial Team
Author(s): Greg Postalian-Yrausquin
Originally published on Towards AI.
This is a quick example to demonstrate the use of RNN to classify a set of tweets into positive or negative feedback. The idea is to give a quick high-level view of how recursive neural networks are trained for datasets that have a continuous internal structure, such as text.
In standard neural networks, each layer only depends on the layer immediately above it, which means that a network forms a linear structure which “forgets” the previous data. In recursive neural networks an adiotional feedback loop is created that introduces non linearity in the network and allows the system to “remember” previous steps (with limitations). This makes RNNs a good choice to model data like text, video or sound.
The first step in our exercise is to load the libraries and the data, then clean it into a usable dataset:
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Subset
from torch.utils.data import DataLoader
from torch.nn.modules.flatten import Flatten
import time, copy
import matplotlib.pyplot as plt
import sklearn.metrics as metrics
import torchvision as tv
from html.parser import HTMLParser
import re
import pandas as pd
from io import StringIO
maindataset = pd.read_csv("Tweets.csv")
maindataset = maindataset[['text','airline_sentiment']]
#keep only positive and negative, transform to numbers
maindataset = maindataset[(maindataset['airline_sentiment']=='positive') | (maindataset['airline_sentiment']=='negative')]
maindataset.loc[maindataset.airline_sentiment == 'positive', 'Y'] = 0
maindataset.loc[maindataset.airline_sentiment == 'negative', 'Y'] = 1
maindataset = maindataset[['text','Y']]
maindataset
Next, I apply a couple of transformations to the text that I use in most NLP tasks:
class MLStripper(HTMLParser):
def __init__(self):
super().__init__()
self.reset()
self.strict = False
self.convert_charrefs= True
self.text = StringIO()
def handle_data(self, d):
self.text.write(d)
def get_data(self):
return self.text.getvalue()
def strip_tags(html):
s = MLStripper()
s.feed(html)
return s.get_data()
def preprepare(eingang):
ausgang = strip_tags(eingang)
ausgang = eingang.lower()
ausgang = ausgang.replace(u'\xa0', u' ')
ausgang = re.sub(r'^\s*$',' ',str(ausgang))
ausgang = ausgang.replace('|', ' ')
ausgang = ausgang.replace('ï', ' ')
ausgang = ausgang.replace('»', ' ')
ausgang = ausgang.replace('¿', '. ')
ausgang = ausgang.replace('', ' ')
ausgang = ausgang.replace('"', ' ')
ausgang = ausgang.replace("'", " ")
ausgang = ausgang.replace('?', ' ')
ausgang = ausgang.replace('!', ' ')
ausgang = ausgang.replace(',', ' ')
ausgang = ausgang.replace(';', ' ')
ausgang = ausgang.replace('.', ' ')
ausgang = ausgang.replace("(", " ")
ausgang = ausgang.replace(")", " ")
ausgang = ausgang.replace("{", " ")
ausgang = ausgang.replace("}", " ")
ausgang = ausgang.replace("[", " ")
ausgang = ausgang.replace("]", " ")
ausgang = ausgang.replace("~", " ")
ausgang = ausgang.replace("@", " ")
ausgang = ausgang.replace("#", " ")
ausgang = ausgang.replace("$", " ")
ausgang = ausgang.replace("%", " ")
ausgang = ausgang.replace("^", " ")
ausgang = ausgang.replace("&", " ")
ausgang = ausgang.replace("*", " ")
ausgang = ausgang.replace("<", " ")
ausgang = ausgang.replace(">", " ")
ausgang = ausgang.replace("/", " ")
ausgang = ausgang.replace("\\", " ")
ausgang = ausgang.replace("`", " ")
ausgang = ausgang.replace("+", " ")
ausgang = ausgang.replace("=", " ")
ausgang = ausgang.replace("_", " ")
ausgang = ausgang.replace("-", " ")
ausgang = ausgang.replace(':', ' ')
ausgang = ausgang.replace('\n', ' ').replace('\r', ' ')
ausgang = ausgang.replace(" +", " ")
ausgang = ausgang.replace(" +", " ")
ausgang = ausgang.replace('?', ' ')
ausgang = re.sub('[^a-zA-Z]', ' ', ausgang)
ausgang = re.sub(' +', ' ', ausgang)
ausgang = re.sub('\ +', ' ', ausgang)
ausgang = re.sub(r'\s([?.!"](?:\s|$))', r'\1', ausgang)
return ausgang
maindataset["NLPtext"] = maindataset["text"]
maindataset["NLPtext"] = maindataset["NLPtext"].str.lower()
maindataset["NLPtext"] = maindataset["NLPtext"].apply(lambda x: preprepare(str(x)))
maindataset["Y"] = maindataset["Y"].astype(int)
maindataset
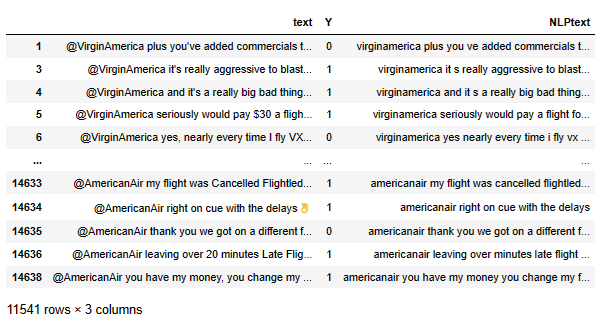
At this point the clean text is in a state that is adequate for machine learning.
The next is to create, train, validation, and test datasets and convert the text into numbers. To do that, an index is assigned to each word.
maindataset = maindataset.sample(frac=1)
df = maindataset['NLPtext'].to_numpy()
#distribute the datasets (predictor part, sentences)
train_sentences = df[:7000]
val_sentences = df[7000:9000]
test_sentences = df[9000:11000]
# dictionary to vectorize the sentences
def add_words_to_dict(word_dictionary, word_list, sentences):
for sentence in sentences:
for word in sentence.split(" "):
if word in word_dictionary:
continue
else:
word_list.append(word)
word_dictionary[word] = len(word_list)-1
_dict = {}
_list = []
add_words_to_dict(_dict, _list, train_sentences)
add_words_to_dict(_dict, _list, val_sentences)
add_words_to_dict(_dict, _list, test_sentences)
target = maindataset['Y'].to_numpy()
#needs to follow the same structure, the target 1 or 0
train_target = target[:7000]
val_target = target[7000:9000]
test_target = target[9000:11000]
Next, let’s convert the datasets into tensors. The sentences are converted to values of 1 and 0 based on the word positions using the indexes created in the dictionary:
# creating the tensors tensor:
def create_input_tensor(sentence, word_dictionary):
words = sentence.split(" ")
tensor = torch.zeros(len(words), 1, len(word_dictionary)+1)
for idx in range(len(words)):
word = words[idx]
tensor[idx][0][word_dictionary[word]] = 1
return tensor.squeeze()
train_tensors = [create_input_tensor(sentence, _dict) for sentence in train_sentences]
val_tensors = [create_input_tensor(sentence, _dict) for sentence in val_sentences]
test_tensors = [create_input_tensor(sentence, _dict) for sentence in test_sentences]
for i in range(3):
print(train_sentences[i], " ", train_tensors[i])

We see that for each sentence, we have one tensor. This is what we are going to use for training.
Since the data is of different sizes, we need to transform it, padding the missing values with zeros to convert all tensors to the same size.
maxsize = 0
for tns in train_tensors:
if (tns.size()[0] > maxsize):
maxsize = tns.size()[0]
for tns in val_tensors:
if (tns.size()[0] > maxsize):
maxsize = tns.size()[0]
for tns in test_tensors:
if (tns.size()[0] > maxsize):
maxsize = tns.size()[0]
#pad the tensors to maxsize
train_tensors = [nn.functional.pad(tns, (0, 0, 0, maxsize - tns.size()[0]), mode='constant', value=0) for tns in train_tensors]
val_tensors = [nn.functional.pad(tns, (0, 0, 0, maxsize - tns.size()[0]), mode='constant', value=0) for tns in val_tensors]
test_tensors = [nn.functional.pad(tns, (0, 0, 0, maxsize - tns.size()[0]), mode='constant', value=0) for tns in test_tensors]
The following textDataSet object wraps the data into three datasets, including in each one the predictor and target parts; then the data loader is created, which handles the distribution of the data in batches, ready for the training cycle
class TextDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.dataset = X
self.labels = y
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
text = self.dataset[idx]
label = self.labels[idx]
return text, label
dataset_train = TextDataset(train_tensors, train_target)
dataset_val = TextDataset(val_tensors, val_target)
dataset_test = TextDataset(test_tensors, test_target)
insize = dataset_train.__getitem__(0)[0].size()[1]
batch_size = 100
dataloaders = {'train': DataLoader(dataset_train, batch_size=batch_size),
'val': DataLoader(dataset_val, batch_size=batch_size),
'test': DataLoader(dataset_test, shuffle=True, batch_size=batch_size)}
dataset_sizes = {'train': len(dataset_train),
'val': len(dataset_val),
'test': len(dataset_test)}
This is the core of the process, the definition and creation of the neural network and the training cycle:
#definition of the neural network. As you can see there is only an RNN definition that
#includes 2 layers and one linear layer.
#dropout and regularization are introduced to reduce overfitting
class RNNClassifier(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.RNN = nn.RNN(input_size, hidden_size, num_layers = 2, dropout = 0.2)
self.fc = nn.Linear(hidden_size, output_size)
pass
def forward(self, input):
output, hn = self.RNN(input)
output = self.fc(output)
return output, hn
model = RNNClassifier(insize,8,2)
#model training
import copy
model.train()
num_epochs=15
learning_rate = 0.007
regularization = 0.001
#loss function
criterion = nn.CrossEntropyLoss()
#determine gradient values
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=regularization)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
best_epoch = 0
phases = ['train', 'val']
training_curves = {}
epoch_loss = 1
epoch_acc = 0
for phase in phases:
training_curves[phase+'_loss'] = []
training_curves[phase+'_acc'] = []
for epoch in range(num_epochs):
print(f'\nEpoch {epoch+1}/{num_epochs}')
print('-' * 10)
for phase in phases:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs
labels = labels
# zero the parameter gradients
optimizer.zero_grad()
# forward
with torch.set_grad_enabled(phase == 'train'):
loss = 0
output, hidden = model(inputs)
output = torch.mean(output,1)
_, predictions = torch.max(output, 1)
loss = criterion(output, labels.type(torch.LongTensor))
# backward + update weights only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(predictions == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
training_curves[phase+'_loss'].append(epoch_loss)
training_curves[phase+'_acc'].append(epoch_acc)
print(f'Epoch {epoch+1}, {phase:5} Loss: {epoch_loss:.7f} Acc: {epoch_acc:.7f} ')
# deep copy the model if it's the best accuracy (based on validation)
if phase == 'val' and epoch_acc >= best_acc:
best_epoch = epoch
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print(f'Best val Acc: {best_acc:5f} at epoch {best_epoch}')
# load best model weights
model.load_state_dict(best_model_wts)

At this point the model is trained. The next steps are there to test the model over the test, unseen dataset
# Utility functions for plotting results
def plot_training_curves(training_curves,
phases=['train', 'val', 'test'],
metrics=['loss','acc']):
epochs = list(range(len(training_curves['train_loss'])))
for metric in metrics:
plt.figure()
plt.title(f'Training curves - {metric}')
for phase in phases:
key = phase+'_'+metric
if key in training_curves:
if metric == 'acc':
plt.plot(epochs, [item.detach().cpu() for item in training_curves[key]])
else:
plt.plot(epochs, training_curves[key])
plt.xlabel('epoch')
plt.legend(labels=phases)
def classify_predictions(model, dataloader):
model.eval()
all_labels = torch.tensor([])
all_scores = torch.tensor([])
all_preds = torch.tensor([])
for inputs, labels in dataloader:
inputs = inputs
labels = labels
output, hidden = model(inputs)
output = torch.softmax(output,dim=0)
output = torch.mean(output,1)
_, preds = torch.max(output, 1)
scores = output[:,1]
all_labels = torch.cat((all_labels, labels), 0)
all_scores = torch.cat((all_scores, scores), 0)
all_preds = torch.cat((all_preds, preds), 0)
return all_preds.detach().cpu(), all_labels.detach().cpu(), all_scores.detach().cpu()
def plot_cm(model, dataloaders, phase='test'):
class_labels = ["positive", "negative"]
preds, labels, scores = classify_predictions(model, dataloaders[phase])
cm = metrics.confusion_matrix(labels, preds)
disp = metrics.ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=class_labels)
ax = disp.plot().ax_
ax.set_title('Confusion Matrix -- counts')
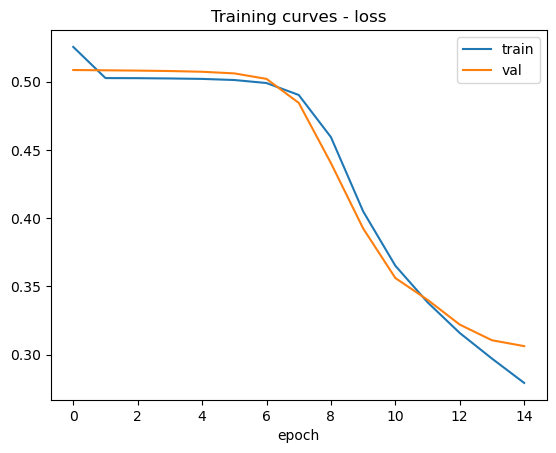
plot_training_curves(training_curves, phases=['train', 'val', 'test'])
These are the training curves:

And finally, the confusion matrix

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts

