



Observer Pattern vs. Pub-Sub Pattern
Last Updated on August 12, 2020 by Editorial Team
Author(s): Munish Goyal
Software Engineering, Systems
Don’t get confused with these two similar but different patterns, and know which one to use when.
This difference is important to not just generic Software Engineers, but also to Data Engineers and is the basis for the understanding event-driven architectures for data pipelines.
Let’s look at both of them individually, before we eventually list-out the differences.
Observer Pattern
“The observer pattern is a software design pattern in which an object, called the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods.” — Wikipedia definition [1]
The observer pattern allows a given object (called the subject) to be monitored by a dynamic group of “observer” objects. Whenever a value on the subject changes, it lets all the observers object know that a change has occurred, by calling their methods update() (say) method. Each observer may be responsible for different tasks whenever the core object changes; the subject doesn’t know or care what those tasks are, and the observer doesn’t typically know or care what other observers are doing.
As an example, let’s create a SubjectMixin which we can mix-in in any Python class to make it easily adhere to the Subject of Observer Pattern.

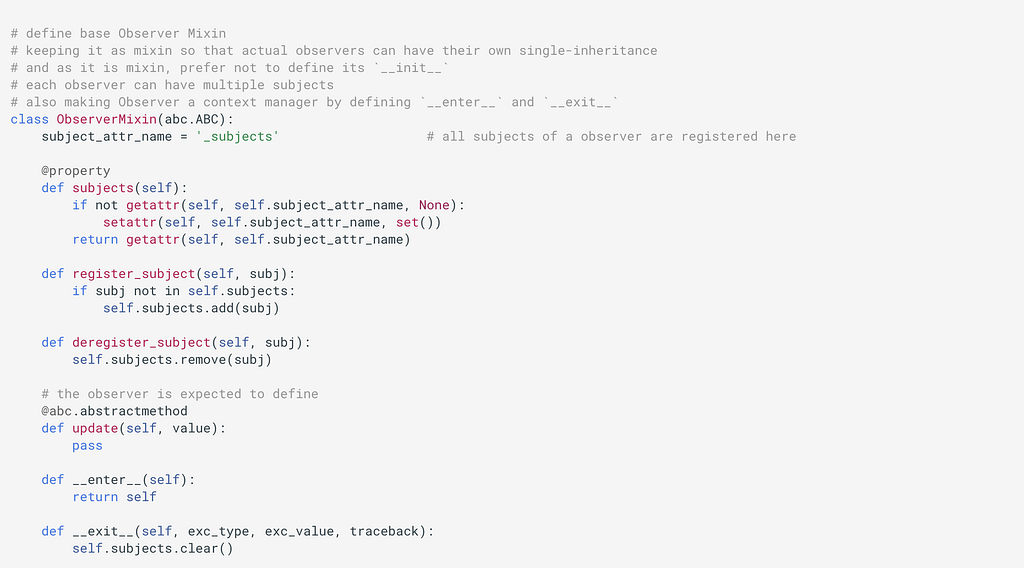
Similarly, let’s create a ObserverMixin which we can mix-in in any class to make it easily adhere to Object of Observer Pattern.
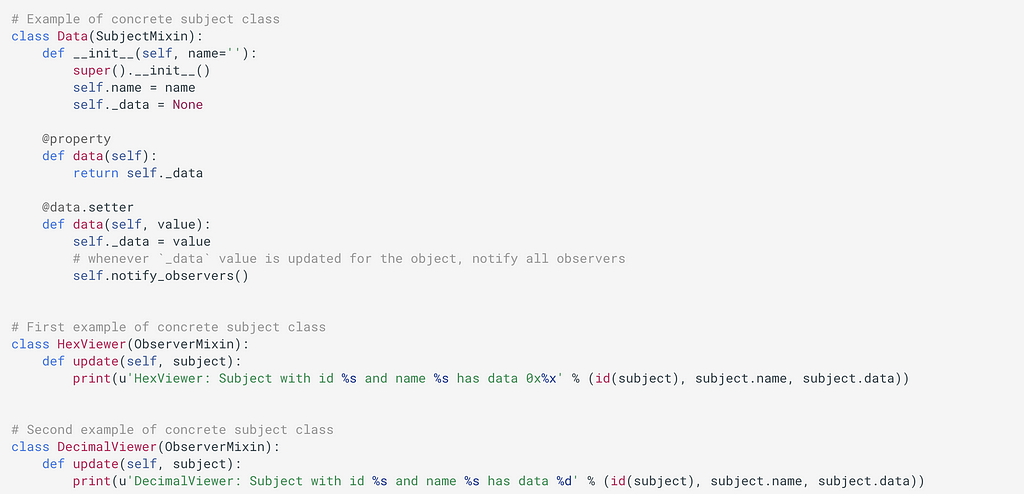
Further, let’s create a Subject named Data and two Observers named HexViewer and DecimalViewer.
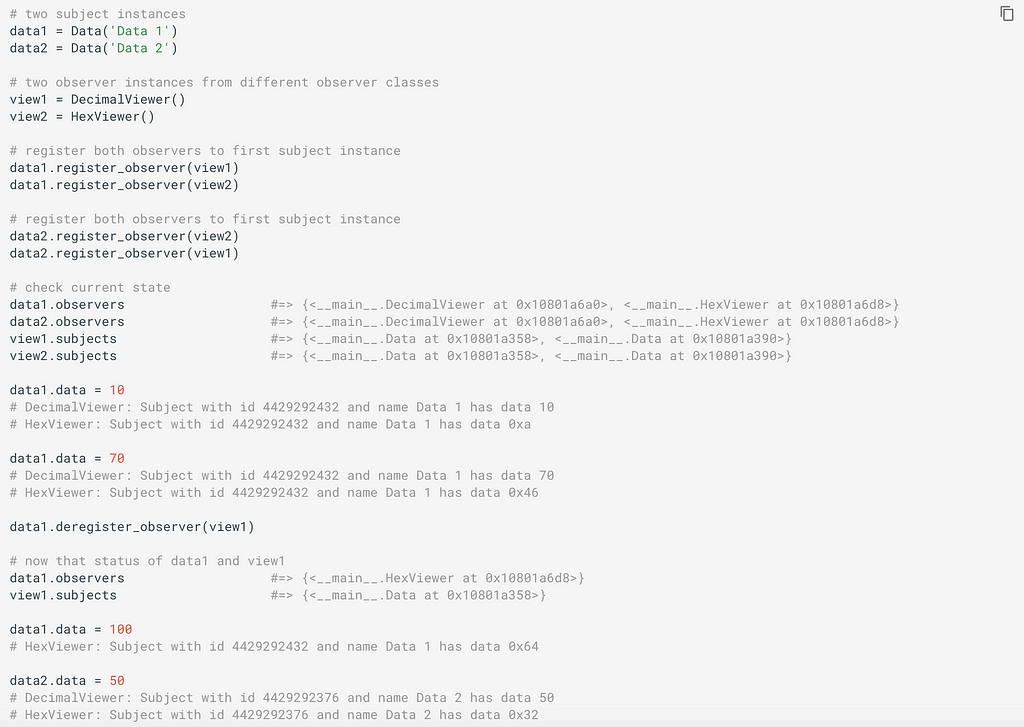
Finally, let’s see the observer pattern in action:
Publisher-Subscribe (Pub-Sub) Pattern
The publisher-subscriber pattern can be considered as an improvized (asynchronous and loosely-coupled) version of the observer pattern. In the pub-sub pattern, senders of messages (called publishers) do not send messages directly to specific receivers (called subscribers). There is an intermediate component, called broker, (or message broker, event bus), to which data is sent by publisher and from where data is received by subscribers. It filters all incoming messages and distributes them accordingly. The popular methods of message filtering are topic-based and content-based.
This means that the publisher and subscriber don’t know even about the existence of one another, and so are just loosely-coupled.
You might like to check Data Streaming with Apache Kafka to appreciate the beauty of the pub-sub mechanism which helps you in making your architecture horizontally-scalable, fault-tolerant, and allows your data transportation at low-latencies.
Difference between Observer and Pub-Sub Pattern
We now understand what individually both of these patterns are. Let’s list their differences:
- In the observer pattern, the source of data itself (the Subject) knows who all are its observers. So, there is no intermediate broker between Subject and Observers. Whereas in pub-sub, the publishers and subscribers are loosely coupled, they are unaware of even the existence of each other. They simply communicate through a broker.
- Similar to what we could see in the previous example, the observer pattern is mostly implemented synchronously, i.e. the Subject calls the appropriate method of all its observers when an event occurs. Whereas, the pub-subs pattern is mostly implemented asynchronously (using a message queue), such as Apache Kafka.
- The observer pattern is generally implemented in a single-application scope. On the other hand, the publisher-subscriber pattern is mostly used as a cross-application pattern (such as how Kafka is used as Heart of event-driven architecture) and is generally used to decouple data/event streams and systems.
References:
[1] Observer Pattern, Wikipedia
Observer Pattern vs. Pub-Sub Pattern was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts




Recent Posts




")

