



Transform your Data in Style with Kafka Connect
Last Updated on January 6, 2023 by Editorial Team
Author(s): Akash Agrawal
Software Engineering
Let us write the simplest yet powerful Single Message Transformation
Do what’s not done before, write what’s not written before.
Kafka turned out to be a game-changer for our organization’s resiliency and performance metrics. Fulfilling the promise of being loosely coupled, highly available, fault-tolerant, and most importantly easy to adapt; Kafka became the default choice for app to app communication leaving behind Restful API, wherever possible.
I was using Kafka along with Kafka Connect for consuming data from several applications. For the most part, the structure and formatting of data(records) in Kafka closely matched my needs. If not, I would use Kafka inbuilt Transformation which would easily allow me to tweak the data a bit. If still unsatisfied, I would request the sourcing team to tweak the structuring of data for my needs. It was imminent that this piggybacking on another team will soon run its course and I will have to look for an inbuilt tool for my specific needs. Enter, Custom Transformation !!
Only problem, you need to know Java; which I don’t; and the only available documentation tries to talk about everything without really explaining anything.

Educating myself on basic Java was quick but figuring out kafka methods and components required to do my transformation job was not. I was surprised to see the lack of documentation and independent articles. So in this article, let’s write a hypothetical yet relatable custom Kafka transformation that will allow you to convert the Kafka message to a specific structure. To make it simple and easy to follow, let’s have:
- Schemas disabled
- No run-time configuration
- Value only transformation(i.e. no Key transformation)
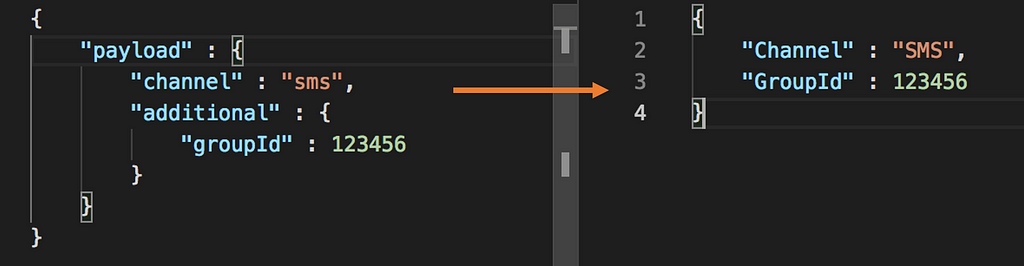
1. Kafka Connect Inbuilt Transformation as Base Structure
Apache Kafka has the source code available for its inbuilt transformation which is a really really good place to start exploring and checking out the best example. We would replicate the same code structure. Have a directory structure as you see in the Apache Kafka source code with a java file at the end that will contain your custom transformation code, in my case CustomTransform.java. The code is also available on Github.
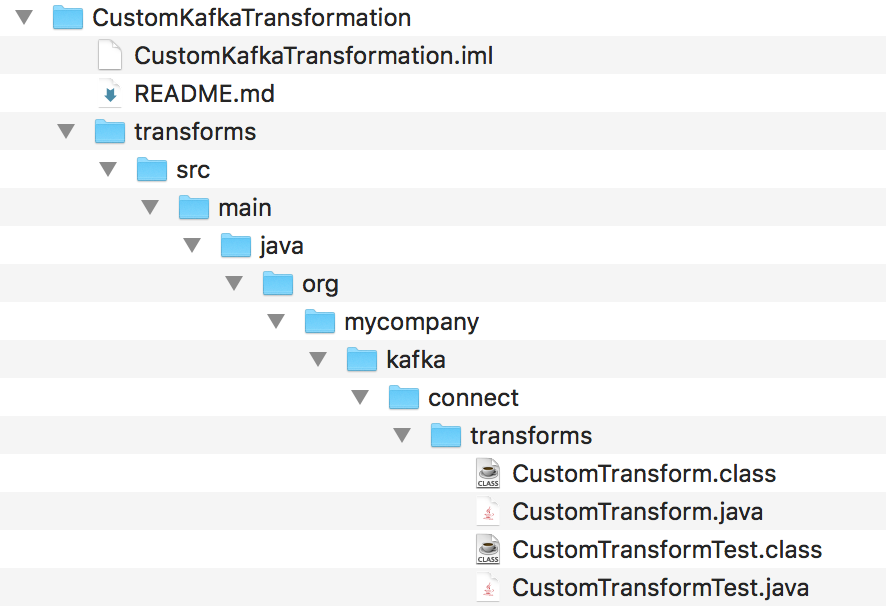
2. Define CustomTransform.java
Conceptually, the flow is that your custom transformation receives records from an upstream system; for a source connector, it would be from your source system or app whereas for sink connector it would be from Kafka broker. Your transform would then convert it to a ConnectRecord and then pass that record through the apply() function of the transformation that has been configured, expecting a record back.
The above shows everything (class, methods, imports) that you would need to build this simple transformation. The apply() method is the real juice which we will write next but else all is good to go. Before we go to apply() do notice key assumptions made to make this program simple:
- our config() returns an empty CONFIG_DEF object. This is simplified because we have assumed “No run time configuration”.
- No mention of operatingSchema(record) or applyWithSchema(record). This contrasts with Kafka standard transformation layout (eg Flatten) since we have assumed “Schemas disabled”.
- No mention of class Key and class Value. This is also simplified because we have pre-decided to be doing “Value only transformation”.
I hope this clears up the significance of each method and class in the standard Kafka transformation and this approach of bottom-up will allow grasping each class incrementally.
3. Implement apply() method
Apply is the core of the transformation. This can do anything and everything with your data in Kafka Key or Value, with our without schema.
We captured the original JSON payload in originalRecord and then iterated through them to construct updatedValue. Needless to mention you can do all sorts of things within apply(), as already visible in the code of existing Kafka transformations.
4. Don’t forget unit testing
A code that can not be tested is flawed, so let's not forget about them. As shown in Image 2, I have my test file CustomTransformTest.java in the same folder as my transformation.
Its a simple test where in the test method testSampleData() we are populating the original payload, passing it to the apply() method, and then ensuring via assert() that the transformed response is as expected.
5. Compile and Validate
$ pwd
~/CustomKafkaTransformation/transforms/src/main/java
$ javac org/mycompany/kafka/connect/transforms/CustomTransform.java
$ javac org/mycompany/kafka/connect/transforms/CustomTransformTest.java
$ java org.junit.runner.JUnitCore org.mycompany.kafka.connect.transforms.CustomTransformTest
JUnit version 4.10
.Inside method :: originalRecord :: {payload={additional={groupId=12345}, channel=sms}}
Inside method :: originalRecord :: {Channel=SMS, GroupId=12345}
Time: 0.016
OK (1 test)
If you see any error with the above, do ensure your CLASSPATH has the path of all the Kafka related JARs as well as JUnit.
And your custom transformation is READY!! Now all that remains is building JAR and mentioning the path of JAR in plugin.path property in your Kafka worker configuration file.
Conclusion
Custom Transformations are powerful and a lot can be done on individual message levels with dynamic configurations and as needs evolve. Hope this simple walkthrough allows you to write all sorts of intricate business needs!
Transform your Data in Style with Kafka Connect was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts




Recent Posts




")

