



Sentiment Analysis with Logistic Regression
Last Updated on February 8, 2021 by Editorial Team
Author(s): Buse Yaren Tekin
Natural Language Processing
📌 Logistic Regression is a classification that serves to solve the binary classification problem. The result is usually defined as 0 or 1 in the models with a double situation.
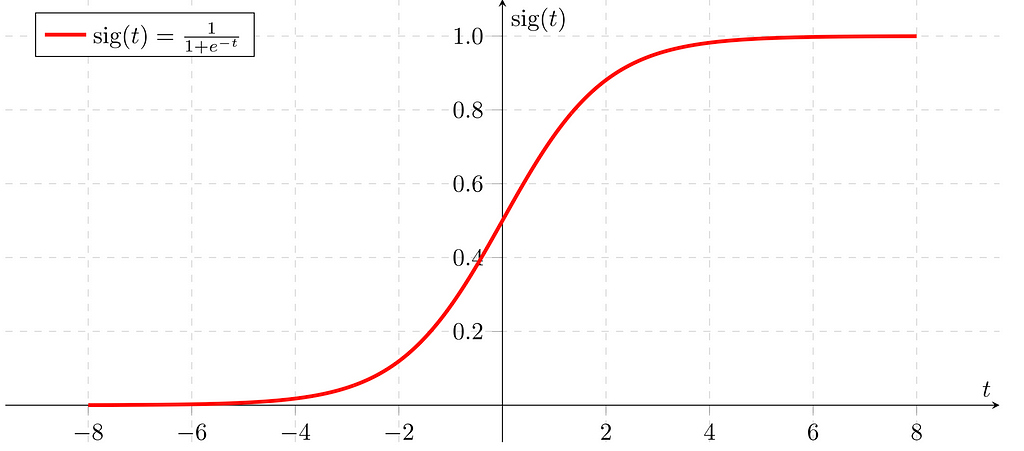
🩸Estimation is made by applying binary classification with Logistic Regression on the data allocated to training and test data in a data set below. First of all, Standardization for pre-processing will be applied, then training data will be trained with fit( ) and then it will be used to estimate test data with the predict( ) method.

What is Sentiment Analysis with Logistic Regression?
Sensitivity Analysis is a method used to judge someone’s feelings or make sense of their feelings according to a certain thing. It is basically a text processing process and aims to determine the class that the given text wants to express emotionally.
✨ It is the name given to mining ideas over the frequency (frequencies) of words such as word number, noun, adjective, adverb or verb while deriving ideas for the purpose from the texts. (Word2vec, TF / IDF)
✨ In frequency-based idea mining, first of all, noun word groups are found and classified according to their length, usage requirements, and positive-negative polarity.
💣 The dataset I use in this project is ‘sentiment140’ data provided free of charge via Twitter API. Below I will inform you about the content and feature classes.
📌 The data set created using the Twitter API includes 1.600.000 tweets.

target: Tweet polarity (0-negative, 2-neutral, 4-positive)
ids: Tweet id
date: Date of the tweet
flag: Query. If there is no query, it is NO_QUERY.
user: User who posted
text: Tweet text (content)
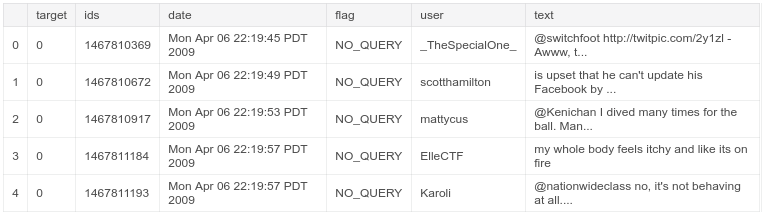
Obtaining the Data Set with Pandas 🐼

✔️ The reason for writing the encoding field used in the read_csv( ) command is that the data is converted into ASCII based 1 byte Latin alphabet characters.
✔️ There are 3 types of classes to be used in sentiment analysis: negative, neutral and positive. The key-value values in the Dataframe, for which the target property is specified, as 0, 2 and 4 tags below, are reduced to two in logistic regression. Because it works with binary classification logic, the neutral class is ignored.
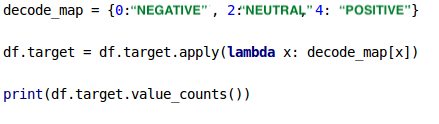
The sum of positive and negative classes in the data set is 800000 + 800000.

Stop Words ✋🏻
The process of converting data into what the computer understands is called preprocessing. One of the main forms of preprocessing is filtering out unnecessary data. Words not used in NLP are called ‘stop words’.
Stop words are common words that a search engine is programmed to ignore both in indexes for search and when retrieving.


Reading Words with NLTK (Stemming)
📌 The regular expression library (re) needs to be introduced prior to the stemming process. Then, with split( ), the words in the sentences will be divided into parts and with the sub( ) command, the regular patterns we call regular expression will be searched for the number of iterations given.
Stop Words Filtering with NLTK 🥅
Stop words should be removed with data clean by searching regular expressions in the patterns given below. Certain regular expression patterns are searched in the string provided with the Substring module used by the Regular expression library. The patterns of the sub-sequences are searched with the given repl value.


Data Preprocessing
- Remove URLs to remove unwanted URLs like http, https, or something like these in text.
- { , . : ; } Remove punctuation marks such as.
- Tokenization: Separating and classifying parts of a string of input characters. It is to separate each word in the sentence.
- In the text, a, most and, etc. Remove words such as stop words as they are. Because these words do not contain useful information.


According to Regex rules, tweets are converted to lowercase with lower( ) as shown below. The process will be carried out in this way. Then, the operation in the function I showed in one line above is done in the stripped and tokens variables below. Words form sentences by combining them with join( ) with spaces between them. In the Negations variable, it is searched with regex rules by correcting the negative cases as a note instead of the word n’t in the substring search.

Splitting the Data Set into Training and Test Data
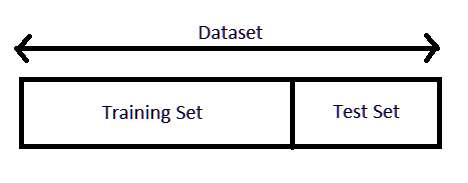
The data in this example were fragmented according to the random_state ratio and the specified criteria (TRAIN_SIZE = 0.75) and the size of the training data was determined to be 1200000 (75% of the data set). After these data were trained, the test set was determined as 400000 (25% of the data set) to be tested.

Target Class (Tweet Polarity)
Below are some users’ tweets. For example, let’s examine the tweet of the user with the id 1994986495.
I am so bored. I don’t feel today. I don’t know why…
As you can see, the target class is specified as 0 because it is a tweet with negative content.

If we need to examine the tweet of the user with the id 1960159696;
What Beautiful Friday!’ Happy Friday Yaa!!!
Since the content is a positive tweet when detected, it is specified as target class 4.

The target class of the data, that is, sentiment data, has been created. Apart from this, by defining negative and positive data without decode_map, these data can also be analyzed.

It has been very useful for me. I hope it was very productive for you as well. Have a nice day 😇
References
- https://de.wikipedia.org/wiki/Datei:Sigmoid-function-2.svg
- https://www.geeksforgeeks.org/python-stemming-words-with-nltk/
- https://www.geeksforgeeks.org/removing-stop-words-nltk-python/
- https://kavita-ganesan.com/news-classifier-with-logistic-regression-in-python/
- https://www.kaggle.com/kazanova/sentiment140
- https://machinelearningmastery.com/logistic-regression-for-machine-learning/
- Conference Paper: Using logistic regression method to classify tweets into the selected topics, Liza Wikarsa, Rinaldo Turang,October 2016.
Sentiment Analysis with Logistic Regression was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

