



Methods, Challenges, and Hazards of Collecting Tweets
Last Updated on January 10, 2021 by Editorial Team
Author(s): Stephen DeFerrari
500 million tweets are sent a day, properly using them in your project goes beyond just writing an API request
Disclaimer: This article is only for educational purposes. We do not encourage anyone to scrape websites, especially those web properties that may have terms and conditions against such actions.
After finishing a sentiment analysis project on Covid vaccine-related tweets, I was left feeling like I was only seeing a small part of the picture. I had built the project using tweets somebody else graciously collected and posted on Kaggle. The criteria for collection was having the hashtag “#CovidVaccine” with retweets filtered out.
Using somebody else’s data was convenient but a lot of tweets must have been missing with such strict criteria. Worse still, a lot of the tweets I did have seemed to be cut off; ending with “…” mid-sentence. I set out to do my own collecting to see if I could do any better. What I had expected to be a simple process of tweaking a few parameters and rewriting some code turned into an ordeal of figuring out 3 questions:
- How am I going to actually collect any tweets?
- How exactly does my query affect my project’s results?
- How useful is Twitter for capturing “national conversations”?
This article is broken down into 3 sections, each one dedicated to one of these questions. Think of this article as part tutorial, part experiment, and part musing. All the code will be in Python but if that isn’t your language of choice, there are still lessons here for anyone interested in using tweets for their next project. Feel free to skip around to portions that interest you most; I won’t mind too much.
Section 1: Different Methods of Collecting Tweets
Tweets can be collected either with or without Twitter’s API. I am going to cover each method and give you their pros and cons.
Twitter API Collection via Tweepy
Tweepy is a Python library that allows for easy access to Twitter’s API. Before you write your first line of code you’ll need to apply for a developer account. Don’t be intimidated, it’s free (for basic access, more on that later), and you should be accepted within a few hours of applying.
After being accepted, you’ll need to create your own project to generate the keys, tokens, and secrets (passwords) needed to access the API. You can find them in the “keys and tokens” section of your project.
Once you have them, start your code by importing Tweepy and Pandas and saving your keys, tokens, and secrets as variables. Then authenticate your account’s credentials so we can start accessing the API!
When we’re successfully authenticated, we can use Tweepy’s Cursor object to search and collect tweets based on specific criteria. For this example, we’re going to collect 100 English tweets between 2020–12–25 and 2020–12–26 that contain the hashtag “#vaccine”. Tweepy also supports more complex searches including using geocodes. For those interested, I highly recommend reading Tweepy’s documentation for a better idea of what’s possible along with Twitter’s own search operators documentation.
tweets = tw.Cursor(api.search,
q="#vaccine",
tweet_mode='extended',
lang="en",
since="2020-12-25",
until="2020-12-28").items(100)
This will return a new object which contains all 100 tweets, but accessing the tweets’ texts isn’t as simple as iterating through and running “print.” Each tweet inside tweets contains a host of information including when it was posted, its text, location, etc. We need to ask the right questions to get what we want from them. Below is a function I’ve written to retrieve each tweet’s user name, location, full text, and tell me if it’s a retweet or not.
You may have noticed earlier that the Cursor object had tweet_mode set to “extended”. This is related to Twitter’s 2017 decision to up the character limit of tweets from 140 to 280. Without it, we’ll end up with tweets longer than 140 cut off with “…”, the issue I ran into with the original dataset.
Simply setting our search to extended and asking for the full_text attribute still isn’t perfect due to retweets getting cut off. This is where the “try”- statement at the bottom of the function comes in. Asking for the full text of the original tweet instead works. Tweepy’s documentation covers this issue in more detail.
With full_text_rt()set up, all we need to do now is a list comprehension on the tweets object. Run each tweet through the function and then convert the list of lists into a Pandas dataframe.
final_tweet_list = [full_text_rt(tweet) for tweet in tweets]
tweets_df = pd.DataFrame(data=final_tweet_list,
columns=['user', "location", "text", "retweet"])
And there you have it, a dataframe with all of the information collected from Twitter’s API via Tweepy.
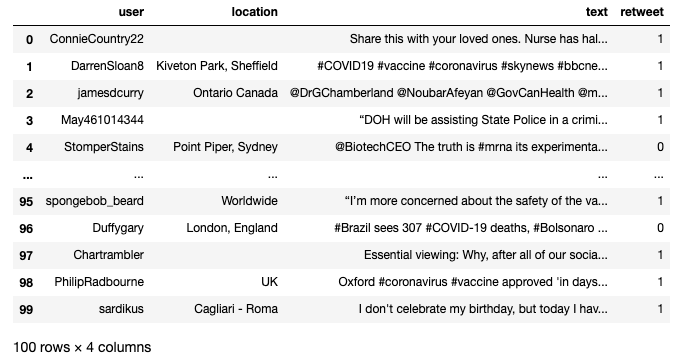
Non-API Collection via Twint
As smooth as the Tweepy process is, we can only get so far using a free Twitter developer account. Our searches can only go back 7 days and we get 50 requests a month. For those who don’t want to shell out between $99 and $1,899 a month for premium access, there is Twint.
Twint is an OSINT (Open Source Intelligence) focused Twitter scraper that allows us to get around the API’s limitations by collecting tweets via Twitter’s own search feature.
We can use Twint via the command line but I’m going to show you how to do it from a notebook. Twint uses asyncio, which has a history of not playing nice with notebooks, so we need to make sure we have nest-asyncio installed, imported, and applied before we do anything.
import nest_asyncio nest_asyncio.apply()
Actually importing Twint, running it, and converting its results into a dataframe can all be done in a single cell, thanks to Twint’s Pandas compatibility.
With far less struggle (but a little more processing time), we should now have our own dataframe with tweets scraped with Twint.
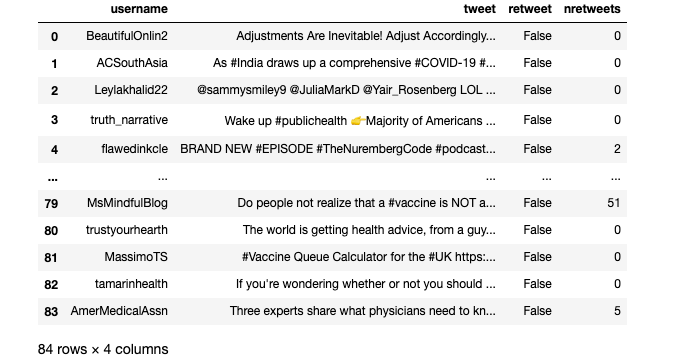
Comparing Tweepy and Twint
As simple and as free as Twint is, it has its downsides. You may have noticed that we didn’t have locations in the Twint dataframe when we did have them in the Tweepy one. Due to Twint’s method of scraping via Twitter’s search function, collecting locations is actually a lot harder and more time consuming for it to do, and Twint is already slow compared to Tweepy.
You may have also noticed that while we requested 100 tweets, my dataframe only came back with 84. If you ran that code on your end you may very well have ended up with anywhere from 80 to 120 tweets despite using identical search criteria. Again, due to Twint’s scraping method, it has problems with consistency.
And then there is the issue of retweets. Despite setting c.Filter_Retweets to false, not a single retweet was returned. This is another problem inherited from using Twitter’s search function and one that Twint’s devs aren’t keen on fixing due to the library’s focus on OSINT collection.
Comparing documentation and tutorials, Tweepy and the API are a lot easier to understand and learn than Twint. Whereas I learned Tweepy by reading its documentation and guides found online, I learned Twint by navigating its “Issues” section on Github where the devs are very active in helping people troubleshoot problems.
Rather than choosing one over the other, it’s better to think of how they can be used together. With Tweepy and the API, you have the consistency and robustness you need to experiment and calibrate your queries to suit your needs. With Twint you have the ability to collect a large number of tweets without the API’s limitations.
One idea is to pull your initial bank of tweets from Tweepy, set up your processing pipeline, and create a minimum viable product. If you’re not satisfied go over your search criteria and try again. If the results work for you, then use Twint to pull a larger bank of tweets using the criteria you perfected on Tweepy and run them through the same pipeline to get your final product.
Section 2: The Challenges of Writing the “Right” Query
Now that we have established how to collect tweets, we need to see how our query changes our results. In the examples used in the last section I searched for tweets containing the “#vaccine” hashtag, but what if I instead dropped the hashtag and searched for tweets just containing “vaccine”? My Tweepy searches also included retweets while my Twint ones did not; how meaningful is that difference?
Rather than sit and wonder, let’s do an experiment where we run four different search results based on whether we use the hashtag or not, and whether we use retweets or not through the same VADER sentiment analysis pipeline and analyze the differences. The pipeline will result in a new column for each tweet with the classification of either “positive”, “neutral”, or “negative” based on the suggested thresholds from VADER’s documentation.
Here are the 3 functions we will be using:
With the functions in place, all we need to do is import the sentiment analyzer and run our search results through it. Here is my full code block for getting the sentiments for 500 tweets posted between 2020–12–25 and 2020–12–16 that contained the word “vaccine” with retweets filtered out. I’m using “vaccine” here rather than the longer “Covid vaccine” to include users who used “corona” instead of “Covid” in their tweets. Additionally, the term “vaccine” in conversation has become nearly ubiquitous with referring to the vaccine for Covid-19.
I ran this code 3 more times, adjusting only the “search_words” variable and dataframe names to cover hashtags vs no hashtags and retweets vs no retweets. Afterward, I took the resulting sentiment columns and imported them into Tableau, turning them into percentage pie charts.
Let’s start with comparing “vaccine” and “#vaccine” without retweets:
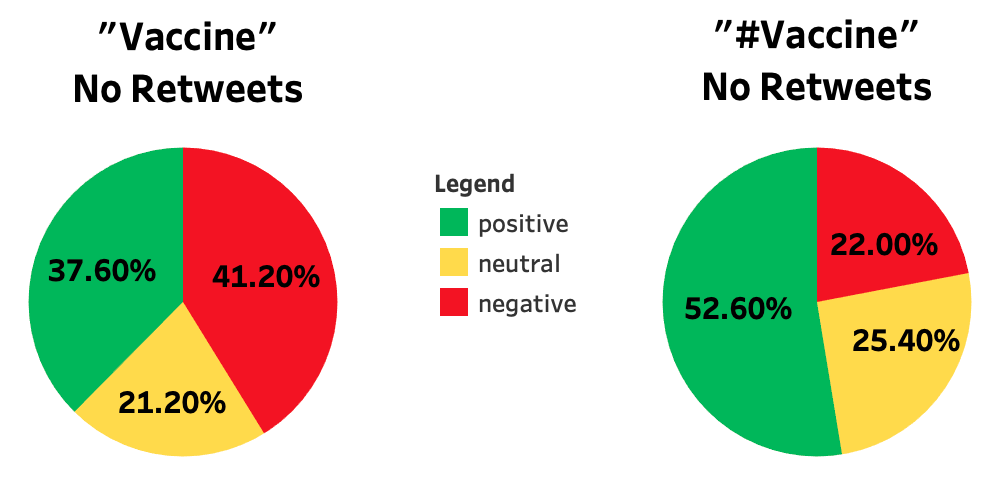
These graphs paint two very different pictures. If we stuck with just using “#vaccine” for our search, we would conclude that a majority of people are feeling positive about the prospect of getting vaccinated, something the “vaccine” search directly disputes with results that instead tell us vaccine rollouts have been met with a lot of negativity and uncertainty on Twitter.
Why the gap in results? It’s important to understand how often people actually use hashtags in their tweets. A 2010 paper titled “Language Matters in Twitter: A Large Scale Study”[1] by researchers from Google and the Palo Alto Research Center found that only 14% of English language tweets contained hashtags. A little bit rosier, brand engagement company Mention in a 2018[2] report concluded that 40% of tweets contained hashtags. We may have been drawing from a much smaller and different pool of tweets when we restricted ourselves to just hash-tagged tweets.
What about retweets? Let’s compare these results if we instead allow retweets to be included in our searches:
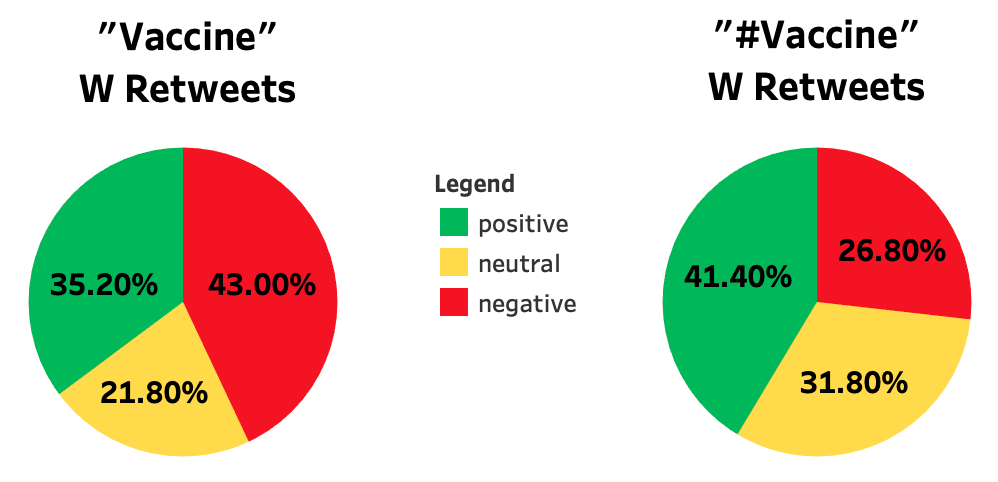
What’s interesting is that in both searches a majority of the tweets were retweets, but the results are strikingly similar to the results we got excluding retweets. The largest difference is the 11 point drop in positivity in the hash-tagged search, but it still left positive with the largest percentage of tweets.
If we recall, one of our issues with Twint was that it doesn’t scrape retweets. With these results, we might feel a lot safer using Twint to scrape tweets that contain “vaccine” since the sentiment ratio would be similar enough to a search containing retweets.
Section 3: Analytic Hazards of Using Tweets
Before you fire up your notebooks and begin your next project it’s important to know how representative Twitter is of the general population, after all, we still have one last question to answer: how useful is Twitter for capturing “national conversations”?

Selection bias should always be on our minds when we collect information from and about people. Understanding what biases exist when using Twitter might not help us mitigate them, but it can flag concerns for us to think about when drawing conclusions from our results.
According to a 2019 Pew Research study, only 22% of Americans actually use Twitter [3]. So we’re working with almost a quarter of the population, but how uniform is that usage? It turns out not uniform at all, another Pew study focused exclusively on Twitter usage[4] found that 10% of American Twitter users were responsible for 80% of tweets in the United States.
The same study found that American Twitter users were generally more likely to be younger, more educated, and more likely to be Democrats than the general public. When zooming in on the top 10% of American Twitter users, researchers found a much higher willingness to post about politics, with 69% of prolific tweeters saying they post about politics, compared to 39% of overall American Twitter users. While the gender divide was mostly evenly split among the bottom 90% of American Twitter users, women made up the majority of prolific tweeters.
Putting all of this together we can see that the American tweets collected are coming from a population that is much smaller and less representative than we might have thought.
These studies apply only to American Twitter users. Remember, our queries were for English language tweets, a language spoken by people all around the world, and who knows what biases exist in other countries regarding Twitter usage!
Conclusion
I hope this article leaves you more knowledgeable about using Twitter data for your next project. In review, we learned the following:
- How to collect tweets using Tweepy and Twitter’s API as well as using Twint
- The importance of testing multiple queries and comparing results
- The biases you may encounter when using tweets based on usage statistics
Twitter, like any source of data, has its pros and cons, but don’t let the negatives keep you from experimenting. My advice is if you have an idea for a project or an interesting query, use the code I provided today and see what results you get. Just remember the importance of experimenting, what to watch out for when drawing conclusions, and one final tip: not everyone takes Twitter seriously.
has any picture summed up Twitter as well as this one pic.twitter.com/zoK9XfLw1I
— Ryan (@NoMagRyan) January 30, 2018
References:
[1] E. Chi, G. Convertino, and L. Hong, Language Matters in Twitter: A Large Scale Study (2010), Fifth International AAAI Conference on Weblogs and Social Media
[2] Mention, 2018 Twitter Engagement Report (2018)
[3] A. Perron, M. Anderson, Social Media Usage Survey (2019), Pew Research Center
[4] A. Hughes, S. Wojcik, Sizing Up Twitter Users (2019), Pew Research Center
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

