


")
Leveling Up Your Travel Agent Skills Through NLP (Part I)
Last Updated on January 7, 2023 by Editorial Team
Author(s): Navish
Natural Language Processing
A Beginners Guide to NLP Preprocessing & Topic Modelling with a Use Case
Have you seen the movie Arrival? It stars Amy Adams, as a Linguist, where aliens have “arrived” at Earth and she is chosen (by the US Govt.) to help decode the aliens’ language. Amongst many other potent themes that the movie takes us through, I absolutely love how it depicts language as one of the fundamental underpinnings that shape a civilization.
Why am I bringing up this movie? Because when I undertook my first jab at dealing with unsupervised machine learning via Natural Language Processing, I was quite frustrated with the lack of direction you feel with it. During this period, I happened to re-watch this movie (one of my all-time favorites), which made a highly positive association in my mind with my current Data Science project.
Q: Umm… What Are You Talking About?
Let’s backtrack a bit — in Fall 2020, I was taking a project-oriented Data Science bootcamp. So far, we had been dealing with supervised learning, which has specific targets and directions to help you see if you are headed somewhere sensible because you know, it’s “supervised”. We had now ventured into the land of unsupervised learning, with a focus on Natural Language Processing.
As part of the project for learning this module, I decided to create a travel preference-based recommendation system, using NLP Topic Modeling. Specifically, I focused on a single destination — Yosemite National Park and used reviews left by users for the park on Trip Advisor.
Q: Why Does This Project Matter?
If you’re a travel aficionado like me, you would be able to completely relate here — Figuring out HOW you should spend your time at your travel destination is a laborious undertaking! It’s very easy to get a huge list of “Must-see things” for any place you are planning to visit. But, many additional hours of research is required to understand which must-see points fit in with your personal preferences.
Do you want to be able to take ‘panoramic photographs?’ Or is ‘shuttle bus’ accessibility important to you? Perhaps you would like to couple these with an ‘easy hike’?
My aim for this project is to provide an ability for travellers to get a rank order list of “Must-see Places,” based on the sort of soft preferences mentioned above.
Broadly speaking, the project consists of 4 parts — acquiring data, NLP preprocessing, topic modeling, and making a recommendation system. The article here focuses on the middle two primarily but mentions all 4.
Q: Okay, What Data Are You Using for this Data Science Project?
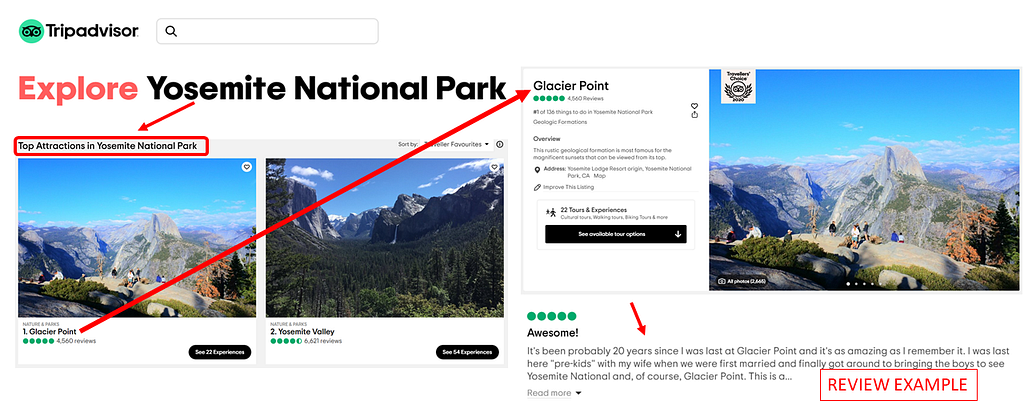
The screenshot above sums it up in a nutshell. I acquired 10,000+ reviews by scrapping Trip Advisor’s page for Yosemite National Park. They have a list of ‘Top Attractions’ under ‘Things to Do’. Each attraction has reviews posted against it, which is what I scrapped from their site. Web scraping is a laborious process to get going correctly. But, this isn’t an article on learning how to scrape, so I am going to move on from here. If you are curious, my jupyter notebook and functions module shows how I went about it.
Q: Do We Really Need to Preprocess?
Yes! But, keep in mind — NLP Preprocessing is like staring into an abyss.
Okay, honestly, it’s an iterative and not-so-complex process. But it sure did not feel like that when I started.
So, you know how language contains text data, right? Computers aren’t a fan of that. They want numbers. To help computers understand and make sense out of the text, it somehow needs to be converted into a numerical representation.
The simplest way to do that is to take every word individually in your text data and make a column for it in a giant table. If just one word is used per column, it’s known as a unigram token. But you can also take each pair of words that occur together and make columns out of that. These would be known as bi-gram tokens. We can tokenize in umpteen ways — 3+ words that occur together, sentences, etc. Then, each trip advisor review (known as ‘documents’ in NLP) makes up the rows here. This resulting table is known as a Bag of Words.
For values in the table, we can fill in the frequency of occurrence for each token (column) against each row (document). If the token does not occur in that review, you fill in a zero.
This is the simplest text to numbers conversion process that exists and is known as a Count Vector.
You can probably start seeing some issues here. If every single unique token has a column — we can quickly get a LOT of columns. Plus, different tenses of a word and punctuations can proliferate this even more. For example: “running” vs “run” vs “ran”. A computer will treat these as three distinct words. In fact, it will even treat “run.” differently from “run!” because of the punctuations at the end. Certain words add no meaning towards understanding the overall text itself, like “and”, “we”, “the” etc.
Hence, we preprocess the text to reduce the number of possible columns (aka dimensions).
Q: So, What Are the Preprocessing Steps?
This is where it gets tricky — what sort of preprocessing steps makes sense and what does not make sense? There sure are a huge variety to choose from!
In my case, I did three things broadly:
Noise Removal using Regex and String functions to convert all characters to lowercase, remove emails/website links, separate words joined with punctuations (eg: difficult/strenuous to difficult strenuous), and remove all characters except alphabets & whitespace (eg: digits, punctuations, emojis).
Word Lemmatization is about converting words to their base form. Eg: “running” and “runs” to “run.” This was done using Spacy. Spacy lemmatization also changes all pronouns to ‘-PRON-‘ when lemmatizing, which was subsequently filtered out.
Stop Word Removal involves getting rid of common words that do not add much meaning but are necessary for grammatical structure in the text. I used a starter list of stop words from NLTK but also curated a custom list of additional words.
The preprocessing must be based on your corpus (all documents collectively are known as the corpus in NLP).
The corpus here was made up of user written reviews. Hence, given more time, I could have taken additional preprocessing steps, such as:
Spelling corrections — These reviews are written by everyday users, possibly in a hurry. Hence, it would be prudent to check for spelling errors and correct them.
Word Normalization — Again, since this is text written on an internet forum by everyday users, some words might be represented in short form lingo, like 2mrw vs tomorrow.
Compound Term Extraction for Names — A unigram word tokenizer splits sentences into words separated by spaces. So, “Yosemite National Park” will be treated as “Yosemite”, “National”, and “Park”. It's better to link all names in the following manner “Yosemite_National_Park” so that they do not get split.
(POS) Filtering — One of the other common & potent forms of preprocessing is filtering words based on specific parts of speech (POS). Meaning, do I want to get rid of all proper nouns, verbs, adjectives, etc.? POS filtering is dictated more by the overall objectives. My objective was to apply topic modeling (more on that in a minute) to capture the reasons for recommending or not recommending a given attraction and then use these topics to build a recommendation system.
<Spacy picture of POS on a travel review>
Based on the above image, it was important for me to keep descriptive text because that is what I wanted to capture for my topics and recommendations. Hence, I did not filter for verbs, adjectives, and common nouns. But, I did make a custom list of stopwords to remove specific descriptive words from my corpus and also got rid of names of places.
I arrived at the above decisions through an iterative cycle of preprocessing and topic modeling. In my opinion, it is very hard to get all the preprocessing done correctly at the first attempt. You need to topic model, look at the results, come back to preprocessing, and repeat cyclically.
All of this can be quite overwhelming when you start off with NLP and each use case can be quite different, with no definite indication that you are headed in the right direction. It needs time, effort, and intuition to get there.
You’re with me this far? Awesome!
Let’s take a look at what I mean by this iterative process, talk more about topic modeling itself, and how I made the recommendation system in Part II of this article. Stay tuned!
In the meanwhile, feel free to check out my Github repo for this project. You can reach me on Linkedin for any discussions.
Leveling Up Your Travel Agent Skills Through NLP (Part I) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

