



AWS Redshift ETL using Pandas API
Last Updated on January 28, 2021 by Editorial Team
Author(s): Vivek Chaudhary
Cloud Computing
The Objective of this blog is to perform a simple ETL exercise with AWS Redshift Database. Oracle Database tables are used as the source dataset, perform simple transformations using Pandas methods on the dataset and write the dataset into AWS Redshift table.
- Import prerequisites and connection with source Oracle:
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine(‘oracle://scott:scott@oracle’, echo=False)
2. Extract Datasets from Oracle Database:
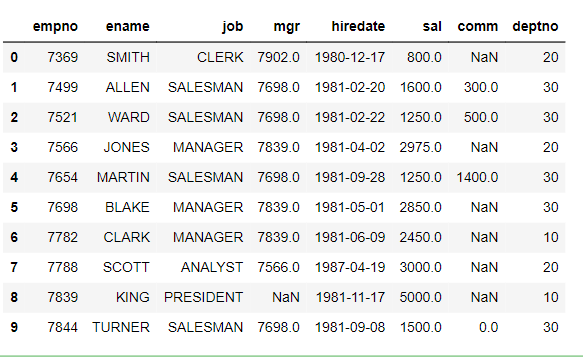
#Employee Dataset
emp_df=pd.read_sql_query(‘select * from emp’,engine)
emp_df.head(10)
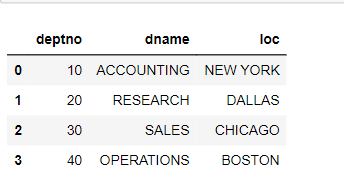
#Department Dataset
dept_df=pd.read_sql_query(‘select * from dept’,engine)
dept_df.head(10)
3. Transform Dataset
Create AWS Redshift Target Table using the below script:
create table emp (
empno integer,
ename varchar(20),
sal integer,
comm float,
deptno integer,
dname varchar(20)
);
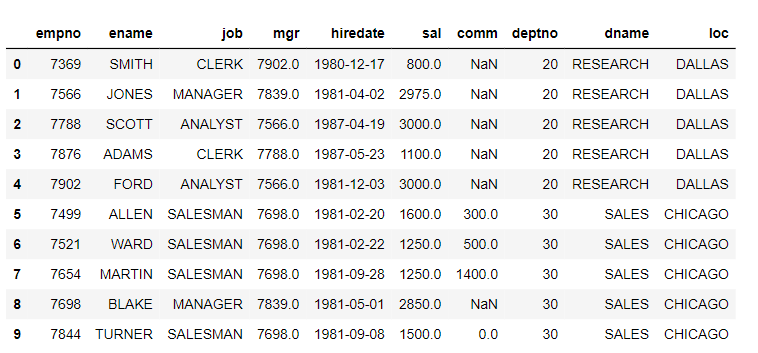
Join the EMP and DEPT datasets:
joined_df=pd.merge(emp_df,dept_df,left_on=’deptno’,right_on=’deptno’,how=’inner’)
joined_df.head(10)
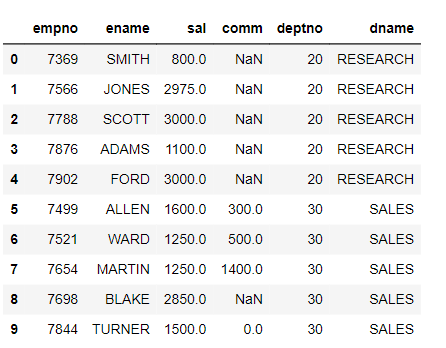
Drop the the columns that are not present in target:
joined_df.drop(columns=['job','mgr','hiredate','loc'],inplace=True)
joined_df.head(10)
4. Create Redshift connection and insert data
#create connection object
conn=create_engine(‘postgresql+psycopg2://<dbuser>:<dbpassword>@<cluster_endpoint_URL>:5439/<dbname>’)
joined_df.to_sql(‘emp’, conn, index=False, if_exists=’append’)
Verify the data in the Redshift table.
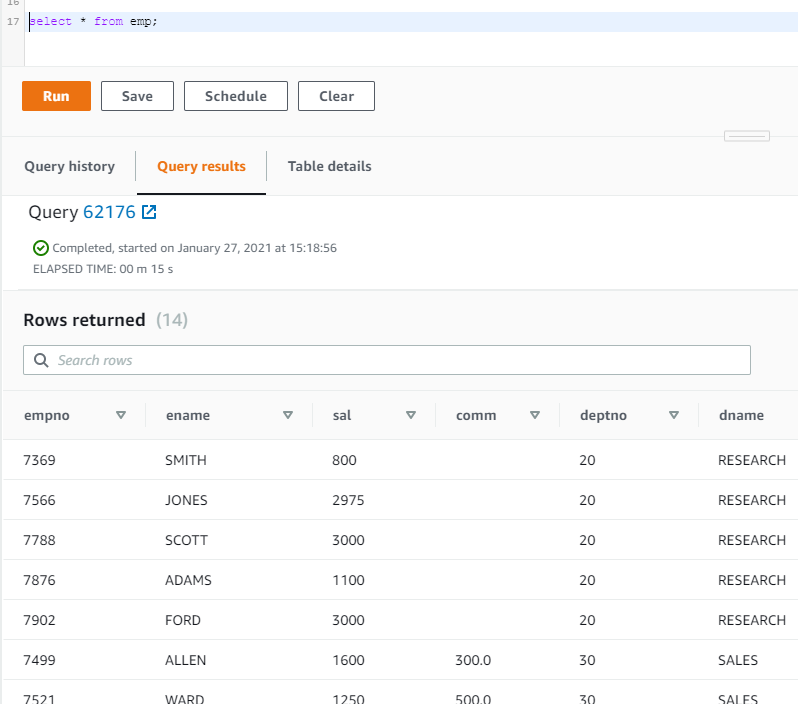
Querying the “emp” table from AWS console, we can also set up SQLWorkbench on local system to query Redshift tables.
DML operation is successful.
5. Connectivity issue I faced
OperationalError: (psycopg2.OperationalError) could not connect to server: Connection timed out (0x0000274C/10060) Is the server running on host “redshift_cluster_name.unique_here.region.redshift.amazonaws.com” (<IP address>) and accepting TCP/IP connections on port 5439?
Issue Description
The issue was that the inbound rule in the Security Group specified a security group as the source. Changing it to a CIDR that included my IP address fixed the issue.
How to Fix?
Go to Cluster Properties → Network Security
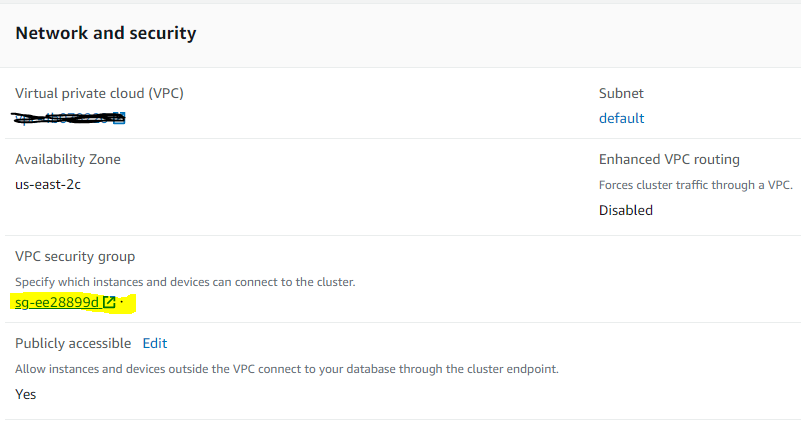
GO to VPC Security Group → Inbound rules →Edit inbound rules and Add both below rules → Click Save Rules.
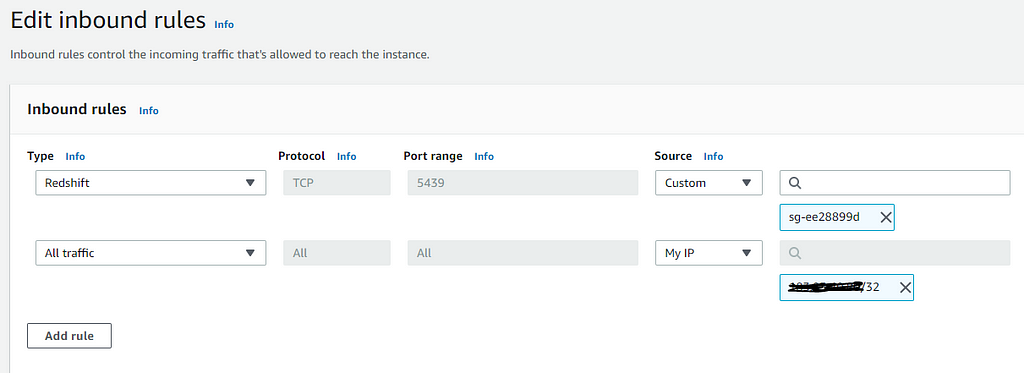
And we are ready to go. In absence of the second rule, there might be a situation where one may face connectivity issues with AWS Redshift DB. So follow the above steps to avoid/resolve the issue.
Thanks to all for reading my blog. Do share your views or feedback.
AWS Redshift ETL using Pandas API was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts


Recent Posts




")


Comments are closed.