



ELECTRA: Pre-Training Text Encoders as Discriminators rather than Generators
Last Updated on October 1, 2020 by Editorial Team
Author(s): Edward Ma
Natural Language Processing
What is the difference between ELECTRA and BERT?
BERT (Devlin et al., 2018) is the baseline of NLP tasks recently. There are a lot of new models released based on BERT architecture such as RoBERTA (Liu et al. 2019) and ALBERT (Lan et al., 2019). Clark et al. released ELECTRA (Clark et al., 2020) which target to reduce computation time and resource while maintaining high-quality performance. The trick is introducing the generator for Masked Langauge Model (MLM) prediction and forwarding the generator result to the discriminator
.MLM is one of the training objectives in BERT (Devlin et al., 2018). However, it is being criticized because of misaligned between the training phase and the fine-tuning phase. In short, the MLM mask token by [MASK] and model will predict the real world in order to learn the word representation. On the other hand, ELECTRA (Clark et al., 2020) contains two models which are generator and discriminator. The masked token will be sent to the generator and generating alternative inputs for discriminator (i.e. ELECTRA model). After the training phase, the generator will be thrown away while we only keep the discriminator for fine-tuning and inference.
Clark et al. named this method as replaced token detection. In the following sections, we will cover how does ELECTRA (Clark et al., 2020) works.
Input Data
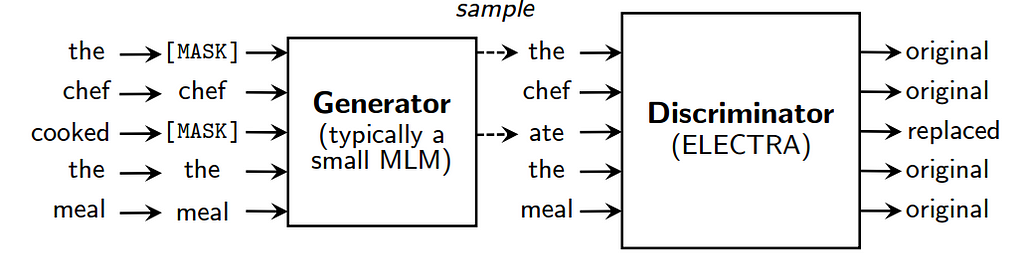
As mentioned before, there are 2 models in the training phase. Instead of feeding masked token (e.g. [MASK]) to the target model (i.e. discriminator/ ELECTRA), a small MLM is trained to predict mask token. The output of the generator which does not include any masked token becomes the input of the discriminator.
It is possible that the generator predicts the same token (i.e. “the” in the above figure”). It will keep tracking for generating a true label for the discriminator. Taking the above figure as an example, only “ate” will be marked as “replaced” while the rest of them (including “the”) are “original” labels.
You may imagine that the generator is a small-size masked language model (e.g. BERT). The objective of the generator is to generate training data for the discriminator and learning word representation (aka token embeddings). Actually, the idea of a generator is similar to the approach of data augmentation for NLP in nlpaug.
Model Setup
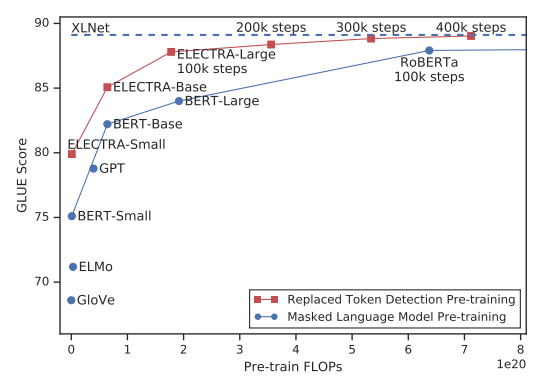
To improve the efficiency of the pre-training, Clark et al. figure out that sharing weight between generator and discriminator may not be a good way. Indeed, they only share token and positional embeddings across two models. The following figure shows that the replaced token detection approach outperforms the masked language model.
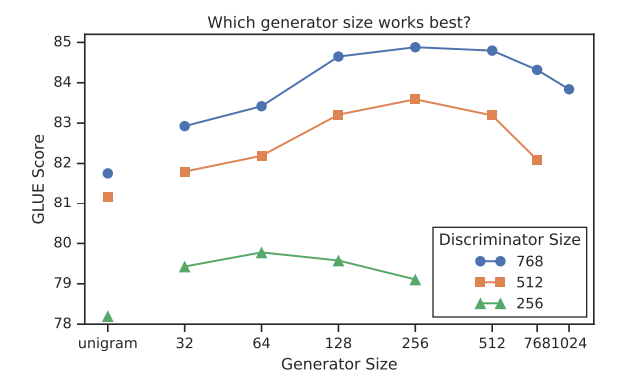
Secondly, the smaller size of the generator provides a better result. Small size generator not only leads a better result but also reducing overall training time.
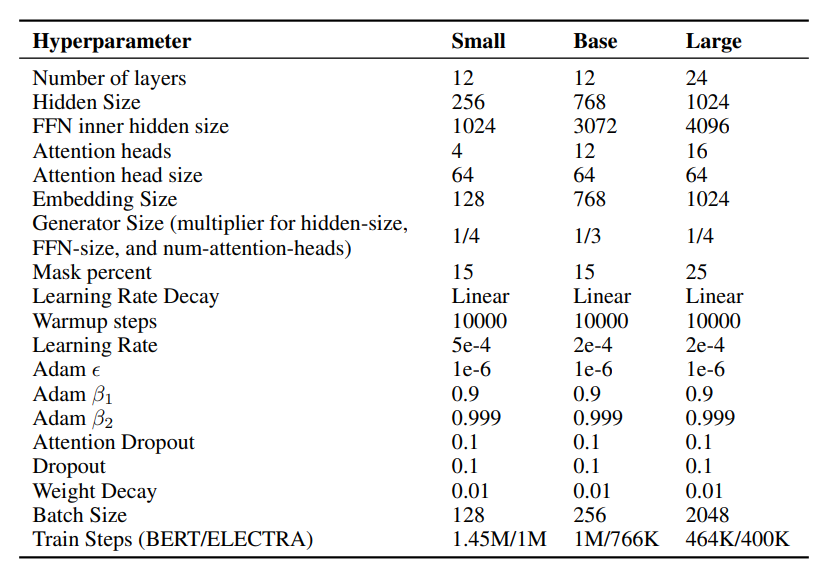
Tuning Hyperparameters
Clark et al. did a lot on fine-tuning hyperparameters. It includes the model’s hidden size, learning rate, and batch size. Here are the best hyperparameters for different sizes of ELECTRA models.
Take Away
- Generative Adversarial Network (GAN): The approach is similar to GAN which intends to generate fake data to fool or attack models (to understand more about the adversarial attack, you may check out here and here). However, the generator from training ELECTRA is different. First of all, the correct token which is generated by the generator considers as “real” instead of “fake”. Also, the generator is trained to maximum likelihood rather than fool the discriminator.
- The major challenge of adopting BERT in production is resource allocation. 1 G memory is almost the minimum requirement for the BERT model in production. Can foresee that there are more and more new NLP models focusing on reducing the size of the model and inference time.
About Me
I am a Data Scientist in the Bay Area. Focusing on state-of-the-art work in Data Science, Artificial Intelligence, especially in NLP and platform related. Feel free to connect with me on LinkedIn or follow me on Medium or Github.
Extension Reading
- Introduction to BERT, RoBERTA and ALBERT
- Data Augmentation for NLP (nlpaug)
- Adversarial Attack in NLP (1, 2)
Reference
- J. Devlin, M. W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. 2018
- Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019.
- Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma and R. Soricut. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. 2019
- K. Clark, M. Luong, Q. V. Le, C. D. Manning. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. 2020
ELECTRA: Pre-Training Text Encoders as Discriminators rather than Generators was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

