



BERT for QuestionAnswering
Last Updated on January 6, 2023 by Editorial Team
Author(s): Shweta Baranwal
Natural Language Processing
A few months back, I wrote a medium article on BERT, which talked about its functionality and use-case and its implementation through Transformers. In this article, we will look at how we can use BERT for answering our questions based on the given context using Transformers from Hugging Face.
Suppose the question asked is: Who wrote the fictionalized “Chopin?” and you are given with the context: Possibly the first venture into fictional treatments of Chopin’s life was a fanciful operatic version of some of its events. Chopin was written by Giacomo Orefice and produced in Milan in 1901. All the music is derived from that of Chopin. Then the answer expected by BERT is Giacomo Orefice.
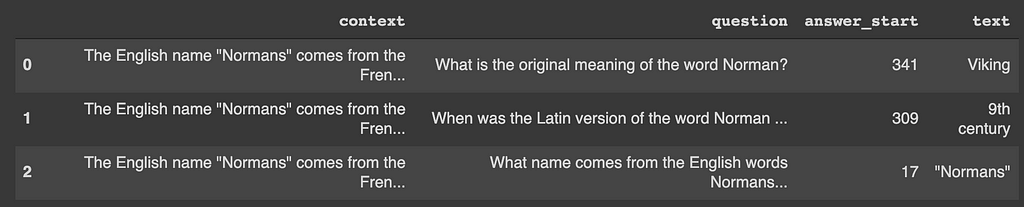
The Stanford Question Answering Dataset can be downloaded from here for fine-tuning BERT: https://rajpurkar.github.io/SQuAD-explorer/. The dataset is in JSON format and requires transformation into a pandas data frame. Once converted, we need three columns. question, context and text . The answer_start column gives the character level start position of the answer in the context whereas we need token level start position of the answer as input goes at the token level into the model. For example: if the context is “Her name is Alex.” and the answer is “Alex,” then answer_start will have value 12, whereas we need to start position as 4. The text column has the answer text in it, and we will be using this column to get the start position of the answer in context.
Input and Output vectors
The question and context are concatenated into one tokenized vector separated by [SEP] token (token id: 102) and fed into the BERT along with token type ids vector where we assign 0 till the question vector then 1 for the context vector. This is similar to the tokenization of two texts where the first text is a question and the second text is context. The tokenizer used is the pre-trained Bert tokenizer from bert-base-uncased. The output vector is the start and end position of the answer from the input tokenized vector.
To get the start and end position of the answer, tokenize the text and look for the text token ids vector in the input token vector and note the start and end index of the input token vector where it matches from the text token ids vector.
Below is the code for torch Dataloader, which outputs the input token vector, token type, ids, and the start and end position of the answer.
Model
The model used is the pre-trained Bert model from bert-base-uncased followed by the linear dense layer of shape (hidden_size, 2). The inputs are question-context concatenated token ids vector and token type ids vector, and the outputs are start and end position of the answer from input token ids. The loss function used is nn.CrossEntropyLoss(). The total loss is the sum of the loss for the start and end positions of the answer.
Training
The max sequence length of the token id used is 512, and the batch size of 8 and ran for 2 epochs on Google colab GPU.
Evaluation
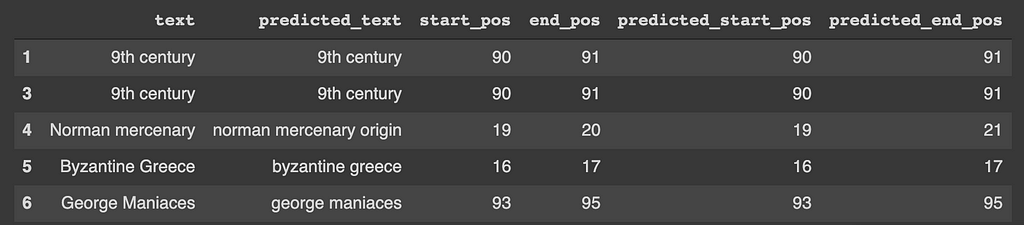
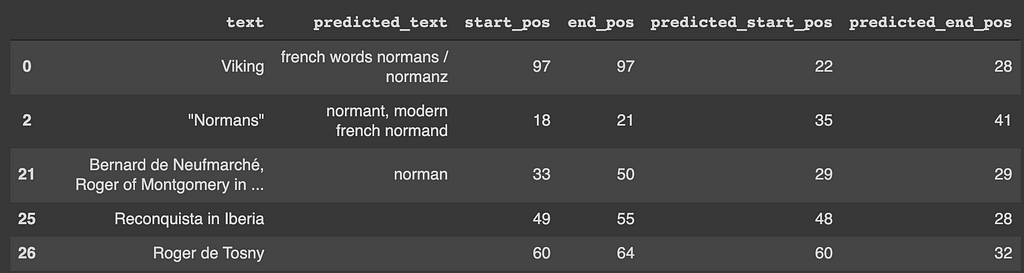
The dev dataset from the SQuAD is converted into pandas df and ran through the trained model. The predicted start and end positions are used to get predicted answer text from input token ids vector and compared against the text (the actual answer) column of the data.
If the predicted start and end position lies within the actual start and end position, that is considered a success. The dev dataset sample used had 454 data points, out of which 349 lie within the actual range of answers giving the validation accuracy of the model around 77%.
Code Git repo
ShwetaBaranwal/BERT-for-QuestionAnswering
References
BERT – transformers 3.3.0 documentation
BERT for QuestionAnswering was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

