


What we Know About Mixtral 8x7B: Mistral New Open Source LLM
Last Updated on December 21, 2023 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Mistral AI is one of the most innovative companies pushing the boundaries of open-source LLMs. Mistral’s first release: Mistral 7B has become one of the most adopted open-source LLMs in the market. A few days ago, they dropped a torrent link with Mixtral 8x7B, their second release, which is quite intriguing.
What makes Mixtral 8x7B so interesting is the fact that it explores a new architecture paradigm that contrasts with the monolithic approach followed by most LLMs. The model is based on a mixture-of-experts approach, which, although not new, hasn’t been proven in the LLM space at scale.
There is not a lot published about Mixtral 8x7B, but below I outlined some details that might be relevant:
The Architecture
Mixtral 8x7B is based on a sparse mixture-of-experts (SMoE) architecture, blending sparse modeling techniques with the mixture-of-experts framework.
In deep learning theory, sparse models are increasingly recognized for their potential. Unlike traditional dense models, where every component interacts with every input, sparse models use a method known as conditional computation. This technique allows Mistral to direct specific inputs to designated experts within its vast network. This approach has several advantages. One of the most notable is the ability to expand the model’s size without proportionally increasing its computational demands. This scalability is not only efficient but also environmentally sustainable, crucial for achieving high performance in AI models. Furthermore, sparsity in neural networks leads to a natural segmentation, which is beneficial in multitasking and continual learning scenarios. Dense models often struggle with these tasks, facing issues like negative interference or catastrophic forgetting, where learning too many tasks at once or in sequence can lead to decreased performance on earlier tasks.
The SMoE component of Mistral consists of multiple experts, each being a straightforward feed-forward neural network. These experts are managed by a trainable gating network. The gating network’s role is pivotal: it determines which combination of experts should be engaged for each specific input. This selection process is sparse, meaning only a few experts are chosen for any given input. Mistral’s entire network, including the experts and the gating system, is refined through back-propagation, a fundamental method in training neural networks. This integrated training approach ensures that all parts of Mistral work in harmony, optimizing its performance in processing and analyzing data.
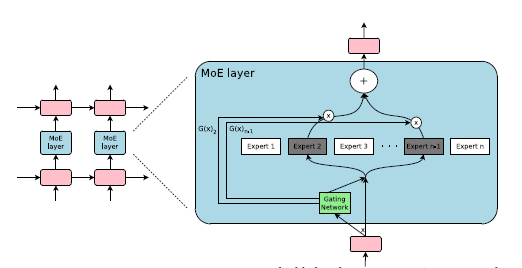
Mixtral 8x7B
Mixtral 8x7B is based on a SMoE architecture. This model, notable for its open-weight architecture, is freely accessible under the Apache 2.0 license. In the field of AI benchmarks, Mistral has demonstrated strong capabilities, surpassing the Llama 2 70B model in most assessments while offering six times faster inference. It stands out as the most efficient open-weight model available under a permissive license, excelling in cost-performance evaluations. Quite notably, Mistral competes with or exceeds the performance of GPT3.5 in standard benchmarks.
Mistral’s capabilities are multi-faceted. It efficiently handles extensive contexts, managing up to 32,000 tokens with ease. Its linguistic proficiency spans multiple languages, including English, French, Italian, German, and Spanish. In the domain of code generation, Mistral shows remarkable strength. Furthermore, when fine-tuned as an instruction-following model, it achieves an impressive score of 8.3 on the MT-Bench.
Mixtral 8x7B some network relies on a decoder-only model. Its architecture is distinguished by a feedforward block that selects from eight distinct groups of parameters. For each token at every layer, a specialized router network selects two of these groups, referred to as “experts”, to process the token. Their outputs are then combined additively. This innovative technique allows Mistral to increase its parameter count while maintaining control over cost and latency. In essence, Mistral boasts a total of 45 billion parameters but utilizes only 12 billion per token. As a result, it processes inputs and generates outputs with the same efficiency and cost as a model with only 12 billion parameters.
Mistral’s training is conducted on data sourced from the open web, with a simultaneous focus on developing both its experts and router networks. This approach underpins its advanced capabilities and efficiency, positioning Mistral at the forefront of open models with sparse architectures in the AI landscape.
Together with the base release, Mistral released Mixtral 8x7B Instruct, an instruction-following model optimized with supervised fine-tuning and direct preference optimization (DPO).
The Performance
Mistral evaluated Mistral 8x7B across different benchmarks in which the model matched the performance of far larger models such as LLaMA 2 70B and GPT 3.5.
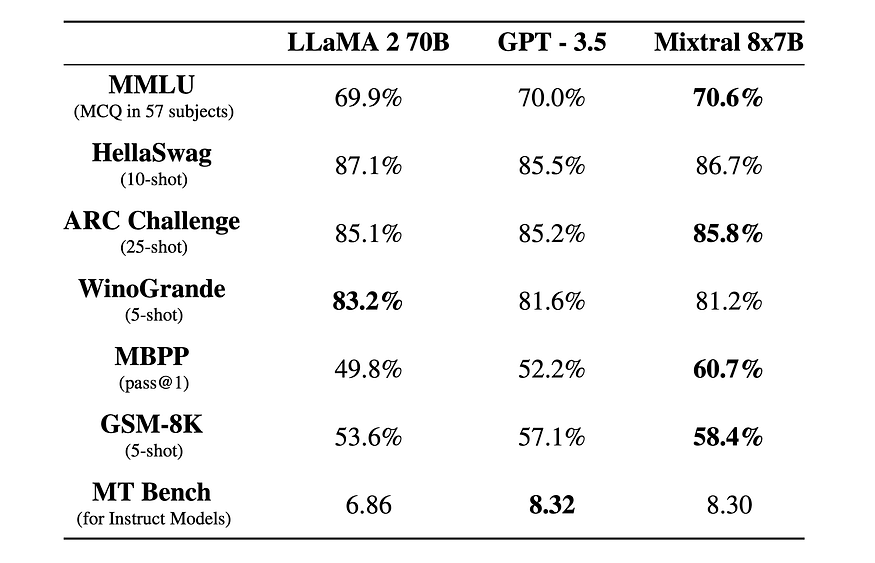
The following charts breakdown the performance vs the inference budget across several key capabilities:

Using Mixtral 8x7B
Mixtral 8x7B was just released and, as a result, hasn’t been productized on many platforms. The premier way to use the model is through the newly announced Mistral platform:
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
api_key = os.environ["MISTRAL_API_KEY"]
model = "mistral-small"
client = MistralClient(api_key=api_key)
messages = [
ChatMessage(role="user", content="What is the best French cheese?")
]
# No streaming
chat_response = client.chat(
model=model,
messages=messages,
)
# With streaming
for chunk in client.chat_stream(model=model, messages=messages):
print(chunk)
Additionally, we can use the model via Hugging Face:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mixtral-8x7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Mixtral 8x7B represents an interesting step in the evolution of open-source LLMs. Hopefully, more details about the model will be unveiled in the next few weeks.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts




Popular posts

 for 2021")



Updates

Recent Posts


