



Underfitting & Overfitting — The Thwarts of Machine Learning Models’Accuracy
Last Updated on June 9, 2020 by Editorial Team
Author(s): Saniya Parveez
Machine Learning
Underfitting & Overfitting — The Thwarts of Machine Learning Models’Accuracy
Introduction
The Data Scientists remain spellbound and never bother to think about time spent when the Machine Learning model’s accuracy becomes apparent. More important, though, is the fact that Data Scientists assure that the model’s accuracy should never suffer from the transgressions of overfitting and Underfitting. It is essential to make a trade-off between getting a good accurate model and a balance to not develop a complicated model. The key to success is in reconciling what ‘s possible and what ‘s practical to achieve the best accuracy at minimum complication because it leads to model Generalization.
The goal of the Machine learning algorithm is to make accurate predictions for new, never-before-seen data. Supervised learning often requires human effort to build the training set, but afterward automates and often speeds up an otherwise laborious or infeasible task. And, In Unsupervised learning, the learning algorithm is just shown the input data and asked to extract knowledge from this data. So, building an accurate model is always a tedious job because it depends on other facts, also like training data, test data, pre-processing steps, multicollinearity, Regularization, or suitable parameters for the algorithms (e.g., Lasso Regularization, Ridge Regression, etc.).
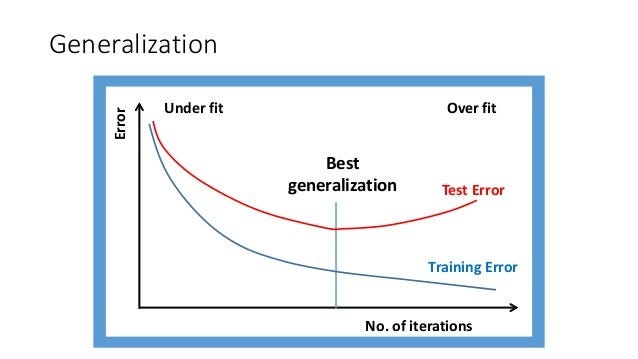
Generalization
In principle, Data Scientist builds a model on the training data, and that should be able to make an accurate prediction on new, unseen data that has the same characteristics as the training dataset. It became a matter of blissful if a model makes accurate predictions on unseen data. In the Data Science filed, it is applauded and said that mode can Generalize from the training set to the test set.
Everyone wants to build a model that can generalize accurately as possible.
Underfitting
The algorithm expects multiple variables or features for the training for better prediction. Let’s take an example of a model that takes a very simple feature like “Everybody who owns a house buys a car.”
Here, the model has limited variables, so the model is not able to capture all the aspects of the variability in the data. The model will do badly even on the training set. Hence, choosing too simple a model is called underfitting.
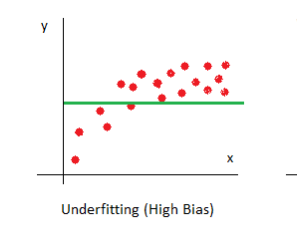
Here, the model shows low variance but high bias.
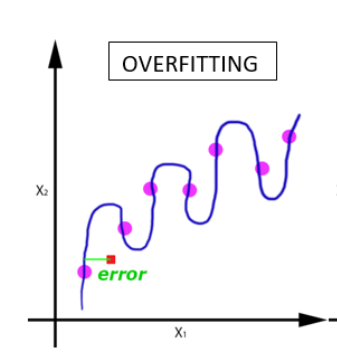
Overfitting
Building a model that is too complex for the amount of information that is provided to the model is called overfitting.
Overfitting occurs when a model is fit too closely to the particularities of the training set and obtain a model that works well on the training set but is not able to generalize to new data. The overfitted model works very well on the training dataset, but it doesn’t work accurately on the test dataset.
A statistical model is said to be overfitted when we train it with a lot of data. When a model gets trained with so much data, it starts learning from the noise and inaccurate data entire in our data set.
Overfitting, Generalization, and Underfitting together
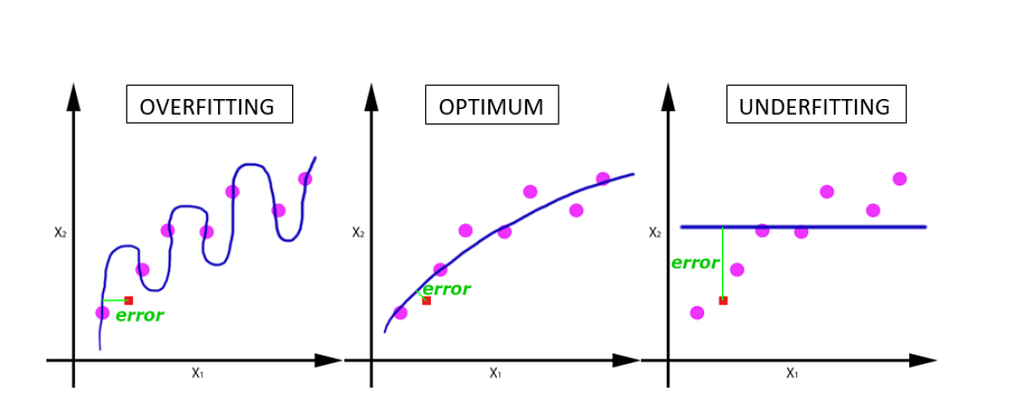
Relationship of Model Complexity to Dataset Size
It’s important to note that model complexity is intimately tied to the variation of inputs contained in the training dataset. Usually, collecting more data points will yield more variety, so larger datasets allow building more complex models. However, simply duplicating the same data points or collecting very similar data will not help.
Conclusion
Machine learning is about extracting knowledge from data. It is a research field at the intersection of statistics, artificial intelligence, and computer science and is also known as predictive analytics or statistical learning. It is crucial to baseline the model by evaluating the performance; otherwise, overfitting or Underfitting may occur. Sometimes model may capture noise from data, and then this can make the model overfitted.
Overfitting and Underfitting are a curse for the prediction. They lead to poor predictions on the new dataset.
Underfitting & Overfitting — The Thwarts of Machine Learning Models’Accuracy was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

