


Token-wise Influential Training Data Retrieval for Large Language Models
Author(s): Reza Yazdanfar
Originally published on Towards AI.
I’m working on a powerful product, nouswise, go and check it out. It’s in the beta phase, if it interests you hit me up on X.
It’s important to know which response corresponds to which data point in the training dataset, but as a matter of fact, AI models are considered as black boxes, which means we don’t know how the model generates a response.
Influence Estimation
Influence estimation aims to determine which training data points are most responsible for specific outputs generated by large language models (LLMs).
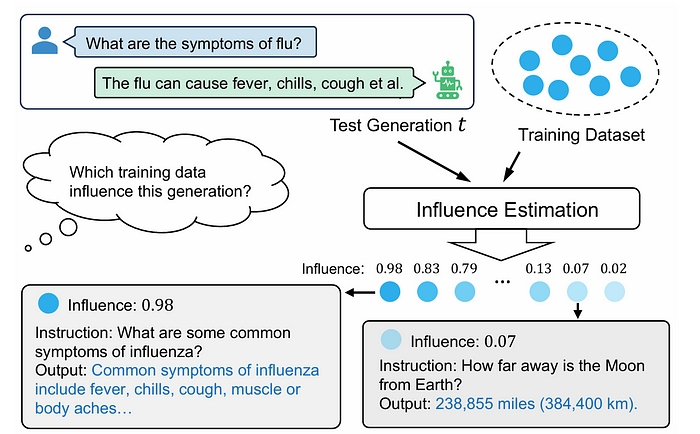
What makes others not effective?
Scalability, computation and efficiency have been avoiding the prior works to be used at scale, while this paper solves these two challenges, RapidIn.
What are the challenges?
There are several new challenges in the field of large language models:
- The new llms have been trained on massive datasets (e.g., 2 trillion tokens for llama-2)
- They’re so so big, like 70 billion parameters
- Almost all prior works have been around classification tasks
what’s the solution?
RapidIn is a framework designed to estimate the influence of training data on large language models (LLMs) by compressing gradient vectors and efficiently passing over cached gradients.
Sounds amazing, doesn’t it? but how actually it work?
It has two stages:
1) caching
This involves compressing the gradient vectors of each training data into a low-dimensional representation known as RapidGrad, significantly reducing their size to MBs or even KBs, making them suitable for storage. The caching operations are independent, allowing for multi-GPU parallelization which further speeds up the process .
Now the data is prepared for the next stage, retrieval.
2) retrieval
During retrieval, for any given test generation, its gradient vector is also converted into a RapidGrad. The influence is then estimated by computing the inner products between this RapidGrad and the cached RapidGrads of all training data points.
Let’s get into more details:
1) Caching Stage:

Layer-wise Normalization.
Problem: Influence functions are fragile and could result in inaccurate results, this could stem from the model’s weights and gradients.
Solution: Applying Layer-wise L2-nomalization to the original gradients before conversion for trained models without weight decay or other regularization.
Gradient Compression.
Problem: Directly using equations for the influence of training data could reduce the speed of calculation and not memory efficient.
Solution: Implementing a vector compression based on the count-sketch data structure, Min-Max Hash, and random projection, by mixing random shuffling and random projection to compress the gradient vector.
RandomShuffling.
Problem: Though random permutation is common to use this method, it is not a suitable choice for llms. Gradient vectors have extremely large dimensionality (for e.g. the length of 7B for lamma-2 7b), it results in hectic as it scales.
solution: Random Shuffling. It’s suitable for large vectors.

This method enables efficient vector shuffling by repeatedly applying randomized permutations to rows and columns, avoiding the creation of a complete permutation vector
Random Projection
The researchers employed Random Projection, this technique involves generating a random vector 𝜌 following the Rademacher distribution, where each element 𝜌𝑖∈{−1,1} with equal probability. The original gradient vector 𝑣 is then element-wise multiplied by 𝜌, and the resulting values are summed in groups to produce a much smaller, lower-dimensional vector called RapidGrad.
Multi-GPU Parallelization
Multi-GPU parallelization significantly enhances the efficiency and scalability of both the RapidIn’s caching and retrieval stages.
2) Retrieval Stage:

The retrieval stage in RapidIn involves estimating the influence of training data on a specific generation by leveraging pre-cached, compressed gradient representations (RapidGrads).
Once the RapidGrads for all training data have been cached, the gradient vector of a given test generation is converted into a RapidGrad in the same way as during the caching stage.
The influence is then estimated by computing inner products between this RapidGrad and the cached RapidGrads of each training data point, significantly speeding up the process by operating on low-dimensional vectors instead of the original high-dimensional ones.
This stage is further accelerated by parallelizing the influence estimation across multiple GPUs and processes, with results gathered on the CPU, enhancing both speed and scalability
Experimental Evaluation and Results
The evaluations were conducted on the alpaca dataset and compared RapidIn against five baselines: random selection, embedding similarity, BM25, influence function, and TracIn.
The experiments also showed that RapidIn can handle large models like l 70b without encountering out-of-memory issues, unlike the influence function and TracIn methods.
The experimental evaluation of RapidIn, as shown in Table 4, reveals several key insights. Random selection and BM25 both achieve poor results in the influence estimation tasks.
However, the embedding similarity method performs reasonably well. This performance is attributed to the fact that the test generation and the poisoned data share the same trigger and similar content.

Memory and Time Consumption


Qualitative Analysis

I’m working on a powerful product, nouswise, go and check it out. It’s in the beta phase, if it interests you hit me up on X.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

