


")
The Fundamentals of Neural Architecture Search (NAS)
Last Updated on July 21, 2020 by Editorial Team
Author(s): Arjun Ghosh
Machine Learning
Neural Architecture Search (NAS) has become a popular subject in the area of machine-learning science. Commercial services such as Google’s AutoML and open-source libraries such as Auto-Keras [1] make NAS accessible to the broader machine learning environment. We explore the ideas and approaches of NAS in this blog post to help readers to understand the field better and find possibilities of real-time applications.
What is Neural Architecture Search (NAS)?
Modern deep neural networks sometimes contain several layers of numerous types [2]. Skip connections [2] and sub-modules [3] are also being used to promote model convergence. There is no limit to the space of possible model architectures. Most of the deep neural network structures are currently created based on human experience, require a long and tedious trial and error process. NAS tries to detect effective architectures for a specific deep learning problem without human intervention.
Generally, NAS can be categorized into three dimensions- search space, a search strategy, and a performance estimation strategy [4].
Search Space:
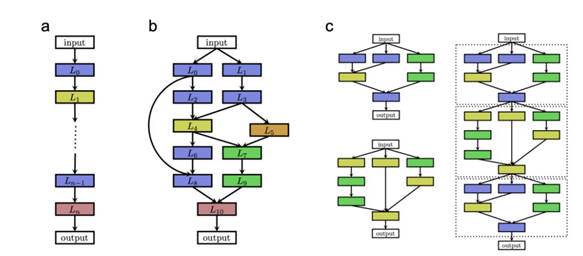
The search space determines which neural architectures to be assessed. Better search space may reduce the complexity of searching for suitable neural architectures. In general, not only a constrained but also flexible search space is needed. Constraints eliminate non-intuitive neural architecture to create a finite space for searching. The search space contains every architecture design (often an infinite number) that can be originated from the NAS approaches. It may involve all sets of layer configurations stacked on each other (Figure 2a) or more complicated architectures that include skipping connections (Figure 2b). To reduce the search space dimension, it may also involve sub-modules design. Later sub-modules are stacked together to generate model architecture (Figure 2c).
Performance Estimation Strategy:
It will provide a number that reflects the efficiency of all architectures in the search space. It is usually the accuracy of a model architecture when a reference dataset is trained over a predefined number of epochs followed by testing. The performance estimation technique can also often consider some factors such as the computational difficulty of training or inference. In any case, it’s computationally expensive to assess the performance of architecture.
Search Strategy:
NAS actually relies on search strategies. It should identify promising architectures for estimating performance and avoid testing of bad architectures. Throughout the following article, we discuss numerous search strategies, including random and grid search, gradient-based strategies, evolutionary algorithms, and reinforcement learning strategies.
A grid search is to follow the systematic search. In contrast, random search, randomly pick architectures from the search space and then test the accuracy of corresponding architecture through performance estimation strategy. These are both feasible for minimal search areas, especially when the issue at hand involves the tuning of a small number of hyper-parameters (with random search usually superior to grid search).
As an optimization issue, NAS can be easily formulated through a gradient-based search [5]. Typically, the NAS optimization target to maximize validation accuracy. As NAS used discrete search space, it is challenging to achieve gradients. Therefore, it requires a transformation of a discrete architectural space into a continuous space and architectures derived from their continuous representations. The NAS can get gradients from the optimization target based on the transformed continuous space. Theoretical foundations for gradient search on the NAS are unusual. It is also difficult to certify that the global optimum converges. However, this method shows excellent search effectiveness in practical applications.
Evolutionary algorithms are motivated by bio evolution. Model architecture applies to individuals who can produce offspring (other architecture) or die and be excluded from the population. An evolutionary NAS algorithm (NASNet architecture [6]) derived through the following process (Figure 3).
I. Random architectures create an initial population of N models. Every individual’s output (i.e. architecture) is assessed according to the performance evaluation strategy.
II. Individuals with maximum performance are chosen as parents. A copy of the respective parents could be made for the new generation of architectures with induced “mutation”, or they might come from parental combinations. The performance evaluation strategy evaluates the offspring’s performance. Operations like adding or removing the layer, adding or removing a connection, changing the layer size or another hyper-parameter may be included in the list of possible mutations.
III. N architectures are selected to remove, which could be the worst individuals or older individuals in the population. The offspring substitute the removed architectures and restarts the cycle.
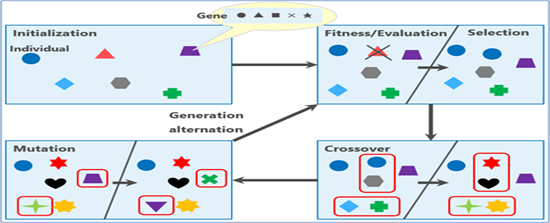
Evolutionary algorithms reveal capable outcomes and have generated state of the art models [7].
NAS methods based on reinforcement learning [8] gained popularity in recent years. A network controller, typically a recurrent neural network (RNN), may be used to sample from the search field with a specific probability distribution. The sampled architecture is formed and evaluated using a strategy for performance evaluation. The resultant performance is used as a reward to update the properties of the controller network (Figure 4). This cycle is iterated before a timeout or convergence occurs.
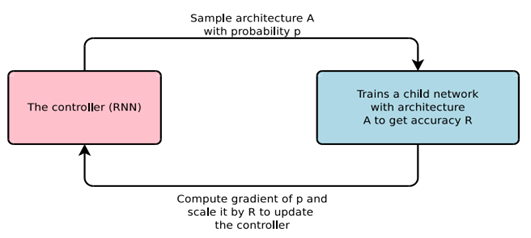
Reinforcement learning able to build network architectures that surpass the hand-made model based on popular benchmark datasets, similar to evolutionary algorithms.
Conclusion:
NAS has successfully established deeper neural network architectures that surpass the accuracy of architectures constructed manually. The state-of-the-art architectures generated by NAS have been developed using evolutionary algorithms and reinforcement learning, specifically in the field of the image classification task. It is expensive because hundreds or thousands of specific deep neural networks need to be trained and tested before the NAS produces successful results. NAS methods are too expensive for most realistic applications. Therefore, further research is required to make the NAS more generic.
References:
[1] H. Jin, Q. Song and X. Hu, Auto-Keras: Efficient Neural Architecture Search with Network Morphism, arXiv, 2018.
[2] K. He, X. Zhang, S. Ren and J. Sun, Deep Residual Learning for Image Recognition, arXiv, 2015.
[3] C. Szegedy et al., Going Deeper with Convolutions, arXiv, 2014.
[4] T. Elsken, J.H. Metzen and F. Hutter, Neural Architecture Search: A Survey, Journal of Machine Learning Research, 2019.
[5] H. Liu, K. Simonyan and Y. Yang, DARTS: Differentiable Architecture Search, arXiv, 2019.
[6] B. Zoph, V. Vasudevan, J. Shlens and Q.V. Le, Learning Transferable Architectures for Scalable Image Recognition, Proceedings Conference on Computer Vision and Pattern Recognition, 2018.
[7] E. Real et al., Large-scale evolution of image classifiers, Proceedings of the 34th International Conference on Machine Learning, 2017.
[8] B. Zoph and Q.V. Le, Neural architecture search with reinforcement learning, arXiv 2016.
The Fundamentals of Neural Architecture Search (NAS) was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

