



The Azure ML Algorithm Cheat Sheet
Last Updated on August 12, 2020 by Editorial Team
Author(s): Lawrence Alaso Krukrubo
Cloud Computing, Machine Learning
Understanding how to choose the best ML models
A common question often asked in Data Science is:-
Which machine learning algorithm should I use?
While there is no Magic-Algorithm that solves all business problems with zero errors, the algorithm you select should depend on two distinct parts of your Data Science scenario…
- What do you want to do with your data?: Specifically, what is the business question you want to answer by learning from your past data?
- What are the requirements of your Data Science scenario?: Specifically, what is the accuracy, training time, linearity, number of parameters, and number of features your solution supports?
The ML Algorithm cheat sheet helps you choose the best machine learning algorithm for your predictive analytics solution. Your decision is driven by both the nature of your data and the goal you want to achieve with your data.
The Machine Learning Algorithm Cheat-sheet was designed by Microsoft Azure Machine Learning (AML), to specifically answer this question:-
What do you want to do with your data?
The Data Science Methodology:
I must state here that we need to have a solid understanding of the iterative system of methods that guide Data Scientists on the ideal approach to solving problems using the Data Science Methodology. Otherwise, we may never fully understand the essence of the ML Algorithm Cheat-sheet.
The Azure Machine Learning Algorithm Cheat-sheet:
The AML cheat-sheet is designed to serve as a starting point, as we try to choose the right model for predictive or descriptive analysis. It is based on the fact that there is simply no substitute for understanding the principles of each algorithm and the system that generated your data.
The AML Algorithm cheat-sheet can be downloaded here.
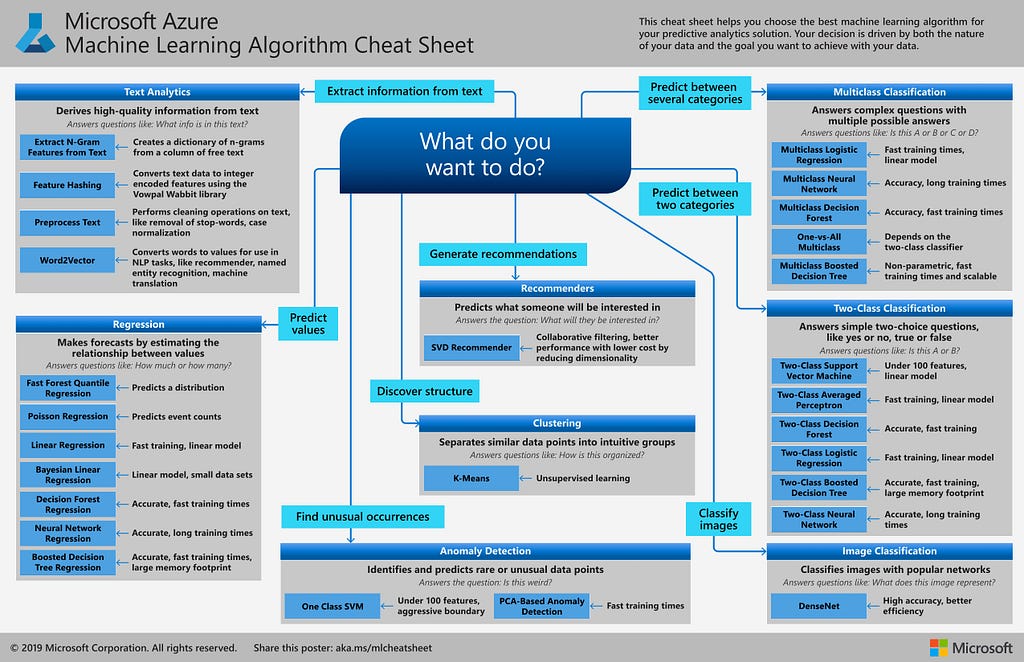
Overview of the AML Algorithm Cheat-sheet:
The Cheat-sheet covers a broad library of algorithms from classification, recommender systems, clustering, anomaly detection, regression, and text analytics families.
Every machine learning algorithm has its own style or inductive bias. So, for a specific problem, several algorithms may be appropriate, and one algorithm may be a better fit than others.
But it’s not always possible to know beforehand which is the best fit. Therefore, In cases like these, several algorithms are listed together in the Cheat-sheet. An appropriate strategy would be to compare the performance of related algorithms and choose the best-befitting to the requirements of the business problem and data science scenario.
Bear in mind that the machine learning process is a highly iterative process.
AML Algorithm Cheat-sheet Applications:
1. Text Analytics:
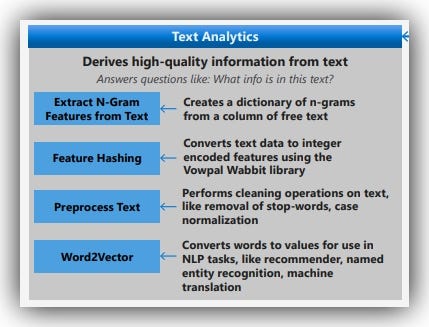
If the solution requires extracting information from text, then text analytics can help derive high-quality information, to answer questions like:-
What information is in this text?
Text-based algorithms listed in the AML Cheat-sheet include the following:
- Extract N-Gram Features from Text: This helps to featurize unstructured text data, creating a dictionary of n-grams from a column of free text.
- Feature Hashing: Used to transform a stream of English text into a set of integer features that can be passed to a learning algorithm to train a text analytics model.
- Preprocess Text: Used to clean and simplify texts. It supports common text processing operations such as stop-words-removal, lemmatization, case-normalization, identification, and removal of emails and URLs.
- Word2Vector: Converts words to values for use in NLP tasks, like recommender, named entity recognition, machine translation.
2. Regression:

We may need to make predictions on future continuous values such as the rate-of-infections and so on… These can help us answer questions like:-
How much or how many?
Regression algorithms listed in the AML Cheat-sheet include the following:
- Fast Forest Quantile Regression: -> Predicts a distribution.
- Poisson Regression: -> Predicts event counts.
- Linear Regression: -> Fast training linear model.
- Bayesian Linear Regression: -> Linear model, small data sets
- Decision Forest Regression: -> Accurate, fast training times
- Neural Network Regression: -> Accurate, long training times
- Boosted Decision Tree Regression: -> Accurate, fast training times, large memory footprint
3. Recommenders:

Well, just like Netflix and Medium, we can generate recommendations for our users or clients, by using algorithms that perform remarkably well on content and collaborative filtering tasks. These algorithms can help answer questions like:-
What will they be interested in?
The Recommender algorithm listed in the AML Cheat-sheet includes:-
- SVD Recommender: -> The SVD Recommender is based on the Single Value Decomposition (SVD) algorithm. It can generate two different kinds of predictions:
The SVD Recommender also has the following features:- Collaborative filtering, better performance with lower cost by reducing the dimensionality.
4. Clustering:
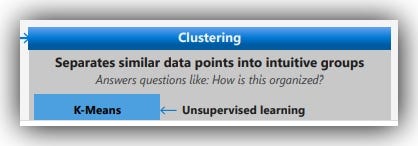
If we want to seek out the hidden structures in our data and to separate similar data points into intuitive groups, then we can use clustering algorithms to answer questions like:-
How is this organized?
The Clustering algorithm listed in the AML Cheat-sheet include:-
- K-Means: -> K-means is one of the simplest and the best known unsupervised learning algorithms. You can use the algorithm for a variety of machine learning tasks, such as:
- Detecting abnormal data
- Clustering text documents
- Analyzing datasets before we use other classification or regression methods.
5. Anomaly Detection:
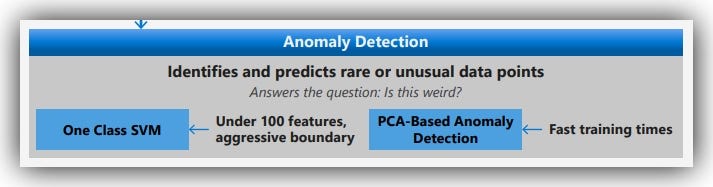
This technique is useful as we try to identify and predict rare or unusual data points. For example in IoT data, we could use anomaly-detection to detect and raise an alarm as we analyze the logs-data of a machine. This could be used to identify strange IP addresses or unusually high attempts to access the system or any other anomaly that could pose a serious threat.
Anomaly detection can be used to answer questions like:-
Is this weird, is this abnormal?
The Anomaly detection algorithm listed in the AML Cheat-sheet include:-
- PCA-Based Anomaly Detection: -> For example, to detect fraudulent transactions, you often don’t have enough examples of fraud to train on. But you might have many examples of good transactions.
The PCA-Based Anomaly Detection module solves the problem by analyzing available features to determine what constitutes a “normal” class. The module then applies distance metrics to identify cases that represent anomalies.
This approach lets you train a model by using existing imbalanced data. PCA records fast training times.
- Train Anomaly Detection model: -> This takes as input, a set of parameters for an anomaly detection model, and an unlabeled dataset. It returns a trained anomaly detection model, together with a set of labels for the training data.
6. Multi-Class Classification:

Often, we may need to pick the right answers from complex questions with multiple possible answers. For tasks like these, we need a Multi-class classification algorithm. This can help us answer questions like:-
Is this A or B or C or D?
Multi-class algorithms listed in the AML Cheat-sheet include the following:
- Multi-Class Logistic Regression: -> Logistic regression is a well-known method in statistics that is used to predict the probability of an outcome, and is popular for classification tasks. The algorithm predicts the probability of occurrence of an event by fitting data to a logistic function.
Usually a Binary-Classifier, but in Multi-class logistic regression, the algorithm is used to predict multiple outcomes.
Features: Fast training times, linear model.
- Multi-class Neural Network: -> A neural network is a set of interconnected layers. The inputs are the first layer and are connected to an output layer by an acyclic graph comprised of weighted edges and nodes.
Between the input and output layers, you can insert multiple hidden layers. Most predictive tasks can be accomplished easily with only one or a few hidden layers. However, recent research has shown that deep neural networks (DNN) with many layers can be effective in complex tasks such as image or speech recognition, with successive layers used to model increasing levels of semantic depth.
Features: Accuracy, long training times.
- Multiclass Decision Forest: -> The decision forest algorithm is an ensemble learning method for classification.
Decision trees, in general, are non-parametric models, meaning they support data with varied distributions. In each tree, a sequence of simple tests is run for each class, increasing the levels of a tree structure until a leaf node (decision) is reached.
Features: Accuracy, fast training times.
- One-vs-All Multiclass: -> This algorithm implements the one-versus-all method, in which a binary model is created for each of the multiple output classes. In essence, it creates an ensemble of individual models and then merges the results, to create a single model that predicts all classes.
Any binary classifier can be used as the basis for a one-versus-all model
Features: Depends on the two-class classifier.
- Multiclass Boosted Decision Tree: -> This algorithm creates a machine learning model that is based on the boosted decision trees algorithm.
A boosted decision tree is an ensemble learning method in which the second tree corrects for the errors of the first tree, the third tree corrects for the errors of the first and second trees, and so forth. Predictions are based on the ensemble of trees together.
Features: Non-parametric, fast training times, and scalable.
7. Binary Classification:
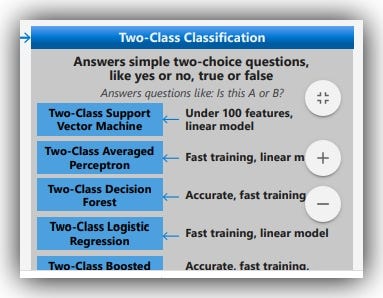
Binary classification tasks are the most common classification tasks. These often involve a yes or no, true or false, type of response. Binary classification algorithms help us to answer questions like:-
Is this A or B?
Binary-classifier algorithms listed in the AML Cheat-sheet include the following:
- Two-Class Support Vector Machine: -> Support vector machines (SVMs) are a well-researched class of supervised learning methods. This particular implementation is suited to the prediction of two possible outcomes, based on either continuous or categorical variables.
Features: Under 100 features, linear model.
- Two-Class Averaged Perceptron: -> The averaged perceptron method is an early and simple version of a neural network. In this approach, inputs are classified into several possible outputs based on a linear function, and then combined with a set of weights that are derived from the feature vector — hence the name “perceptron.”
Features: Fast training, linear model.
- Two-Class Decision Forest: -> Decision forests are fast, supervised ensemble models. This algorithm is a good choice if you want to predict a target with a maximum of two outcomes. Generally, ensemble models provide better coverage and accuracy than single decision trees.
Features: Accurate, fast training.
- Two-Class Logistic Regression: -> Logistic regression is a well-known statistical technique that is used for modeling many kinds of problems. This algorithm is a supervised learning method; therefore, you must provide a dataset that already contains the outcomes to train the model. In this method, the classification algorithm is optimized for dichotomous or binary variables only.
Features: Fast training, linear model.
- Two-Class Boosted Decision Tree: -> This method creates a machine learning model that is based on the boosted decision trees algorithm.
Features: Accurate, fast training, large memory footprint.
- Two-Class Neural Network: -> This algorithm is used to create a neural network model that can be used to predict a target that has only two values.
Classification using neural networks is a supervised learning method, and therefore requires a tagged dataset, which includes a label column. For example, you could use this neural network model to predict binary outcomes such as whether or not a patient has a certain disease, or whether a machine is likely to fail within a specified window of time.
Features: Accurate, long training times.
8. Image Classification:
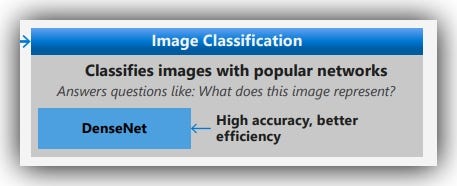
If the analysis requires extracting information from images, then computer vision algorithms can help us to derive high-quality information, to answer questions like:-
What does this image represent?
The computer vision algorithms listed in the AML Cheat-sheet include:-
- DenseNet and ResNet: -> These classification algorithms are supervised learning methods that require a labeled dataset. You can train the model by providing a labeled image directory as inputs. The trained model can then be used to predict values for new unseen input examples.
Features: High accuracy, better efficiency.
Summary:

The Azure Machine Learning Algorithm Cheat Sheet helps you with the first consideration: What do you want to do with your data? On the Machine Learning Algorithm Cheat Sheet, look for a task you want to do, and then find an Azure Machine Learning designer algorithm for the predictive analytics solution.
The Azure Machine Learning experience is quite intuitive and easy to grasp. The Azure Machine Learning designer is a drag-and-drop visual interface that makes it engaging and fun to build ML pipelines, assemble algorithms and run iterative ML jobs, build, train and deploy models all within the Azure portal. Once deployed, your models can be consumed by authorized, external, third-party applications in real-time.
Next Steps:
After deciding on the right model to choose for the business problem, using the Azure Machine Learning Cheat-sheet, the next step is to answer the second question:-
- What are the requirements of your Data Science scenario?: Specifically, what is the accuracy, training time, linearity, number of parameters, and number of features your solution supports?
To get the best possible outcome for these metrics, kindly go through the details at the Azure Machine Learning site.
Cheers!!
About Me:
Lawrence is a Data Specialist at Tech Layer, passionate about fair and explainable AI and Data Science. I hold both the Data Science Professional and Advanced Data Science Professional certifications from IBM. After earning the IBM Data Science Explainability badge, my mission is to promote Fairness and Explainability in AI… I love to code up my functions from scratch as much as possible. I love to learn and experiment…And I have a bunch of Data and AI certifications and I’ve written several highly recommended articles.
Feel free to connect with me on:-
The Azure ML Algorithm Cheat Sheet was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")