


")
Tabular Learning — Gradient Boosting vs Deep Learning( Critical Review)
Last Updated on July 26, 2023 by Editorial Team
Author(s): Raghuvansh Tahlan
Originally published on Towards AI.
Thanks to technological advancements and affordable computing, complex systems are being developed to analyse the exponentially growing data and generate actionable insights. Neural Networks, the core of these complex systems, have shown exceptional performance on Homogeneous (text and image) data. However, it wasn’t until recently that Neural Networks were utilised for Heterogeneous Tabular data, the oldest and most common form of data. The competitive performance of tree-based models on tabular data may have also been a factor in Neural networks’ underutilization. With various models proposed, we try to categorise them and provide some basic understanding for some of them claiming to be state-of-the-art. This work attempts to answer the availability of established benchmarks and whether it’s time to leap from Tree-based to Neural Network-based models for Tabular data.
Introduction
Tabular data comprises samples (rows) of fixed-length vectors (columns as features) that can be stored in flat files such as text, CSV, TSV etc. It was the only form of data collected before the digital age making it the oldest and most common in real-world applications. A recent survey by Kaggle(2017) reported that relational data, a subdivision of Structured or Tabular data, is the most popular form of data in the industry is used daily by at least 65% of the total 14,000 data scientists[16]. It is ubiquitous in numerous critical and demanding fields ranging from bioinformatics, e-commerce, medicine, banking, finance to others that are based on relational databases. Some problems include customer churn prediction, medical diagnosis, risk analysis, fraud detection, user and product recommendation, etc.
Neural Networks vs Gradient Boosting Models
Deep learning solutions have been widely adopted for tasks involving homogeneous data such as images, speech and text. Their excellent performance could be attributed be their unique structures designed to model the particular data patterns, such as CNN capturing spatial locality and RNN modelling sequential dependency. While deep learning for tabular is not uncharted territory, it remains under-explored with some focus in recent years. Despite the theoretical advantages over Gradient boosting trees, variants of ”Shallow” tree-based ensemble methods still dominate deep learning models in most applications. This inferior performance could be due to the different statistical properties of the datasets or the lack of prior knowledge about the dataset structure. While it requires many pixels to change an object, a small change to input in the case of tabular data may change the label or prediction. The most popular advantage of tree-based models, among others, such as faster training with fewer hyperparameters, is their interpretability and explainability, which is an essential concern in many real-world applications. However, they aren’t suitable for continual training on streaming data, unsupervised pre-training and training with other modalities such as images and text, which has led to an increasing interest in tabular-deep learning in recent years.
Additionally, Neural Networks are flexible and offer many benefits, such as alleviating the need for manual categorical encoding and feature engineering, an essential aspect of tree-based learning. These reasons have led to several deep learning based solutions for tabular data while new ones continue to be developed. While some of them (AutoInt[14], FT-Transformer[4], TabNet[1], TabTransformer[6], etc.) claim to outperform tree-based models, they use different datasets and metrics for evaluation due to a lack of established benchmarks (such as ImageNet for Computer Vision and GLUE for NLP), which makes it hard to rank the algorithms or investigate whether they generally outperform tree-based algorithms[4]. While they can push the state-of-the-art, they have, in some instances, are still not widely adopted due to software engineering and implementation challenges. One could quickly train a popular tree-based model (CatBoost, LightGBM, XGBoost, etc.) in one line, for, eg.
Model = Model = CatBoost().f it(X, y)
which is not the case for popular tabular-deep learning based models. Libraries like fasta.ai ( Making neural networks uncool again ), Deep Tables ( Deep Learning Toolkit for Tabular data) and PyTorch Tabular, which aim to make deep learning easy to use, give some hope for the future.
Methodology
As earlier mentioned, tabular data contains rows as samples and columns as features. These features could be correlated or independent, may or may not have a relationship and don’t follow any positional order. They can either be continuous (numeric) or discrete (categorical) but are challenging in their ways. While numeric attributes could be multi-modal or may not follow any known distribution, discrete features are qualitative. They can take value from a limited unique set of values and may not follow any particular order, as David M. Lane described in his definition[9]. Feature processing or engineering is essential in traditional machine learning models that use domain knowledge to extract predictive features and convert categorical features into numeric ones. Single-Dimensional (One-hot encoding, Target encoding, Binary encoding or leave one out encoding) or Multi-Dimensional encoding techniques can be applied such that no artificial ordering is induced within the categories or features. When the different values of a categorical feature (cardinality) become significant, it may increase overall size due to sparse feature vectors.
Transformation Models
Deep Neural Networks (DNNs) in general and Convolution Neural Networks (CNNs) inspired by visual neuroscience have shown exceptional performance in Computer Visions tasks. Still, they are unsuitable for use on tabular data due to a lack of spatial relationships between features. As features in tabular or structured data are considered mutually independent, any change in their order should not affect the data.
DeepInsight and IGTD
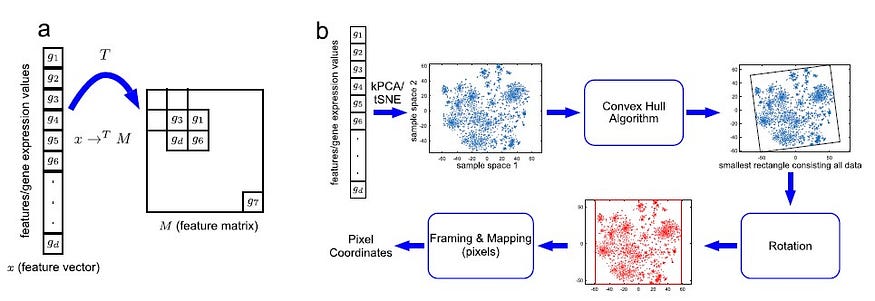
Recent algorithms such as Deep Insight[12] and IGTD[17] ( Image Generator for Tabular Data ) propose rearranging these features in 2-D space to represent relationships and convert tabular data into images for predictive modelling using CNNs[12, 17]. This transformation would eliminate feature engineering because CNNs can extract features from images via hidden layers. Both the algorithms propose rearranging the features to create the spatial relationship; however, their methodologies aren’t similar. Deep Insight uses non-linear dimensionality reduction techniques such as t-SNE or kernel principal component analysis (k-PCA) to obtain a 2-D plane and convex hull algorithm to find the smallest rectangle containing all the points[12, 17]. The generated image from the rectangle is then rotated to align it horizontally or vertically and passed through CNN for classification[12, 17]. Visual representation of the process is also available in figure 1. IGTD also aims to keep similar features together in the image representation but minimises the difference between feature distance ranking and pixel distance ranking[17]. Authors also reported that while Deep Insight is faster to generate images from the same dataset, IGTD creates a more compact image representation, reducing memory consumption and shorter training time for CNNs. IGTD also seems robust against different hyper-parameters[17].
SuperTML
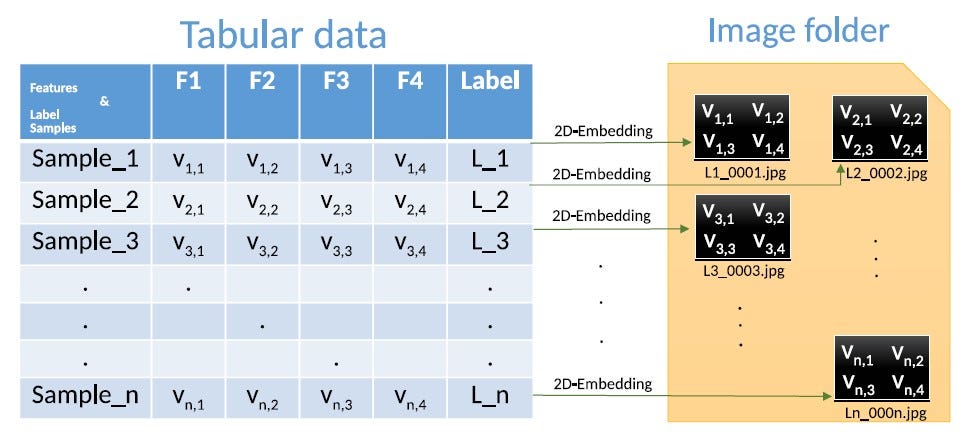
Another methodology SuperTML[16] (Super Tabular data Machine Learning), also proposes to convert tabular/structured data into images but is inspired by Super Characters[15], which converts text into images and use CNN to perform image classification on the resulting problem[16]. An example of SuperTML and Super Characters is present in figures 3 and 2. Both SuperTML and Super Characters convert each sample’s contents ( row of text or features) into a two-dimensional matrix or image where each pixel is represented as each feature of the sample[16, 15]. Then CNNs pre-trained on larger datasets are applied to the resulting images for the image classification problem to achieve higher accuracy. While Deep Insight or IGTD algorithms may fail when there is no or little spatial relationship between features or are independent, SuperTML has not reported any such limitations. Although the algorithms mentioned above (IGTD, Deep Insight, SuperTML) performed well on the datasets they appeared with, they should not be recommended until they have been evaluated on a range of datasets.

Hybrid Models
Hybrid models fuse both neural networks and tree-based models to get the best of both worlds — neural networks for their automatic feature engineering and tree-based models for their remarkable performance on tabular data. These models have been made differentiable to be utilised in end-to-end training pipelines and take advantage of gradient optimisation.
NODE
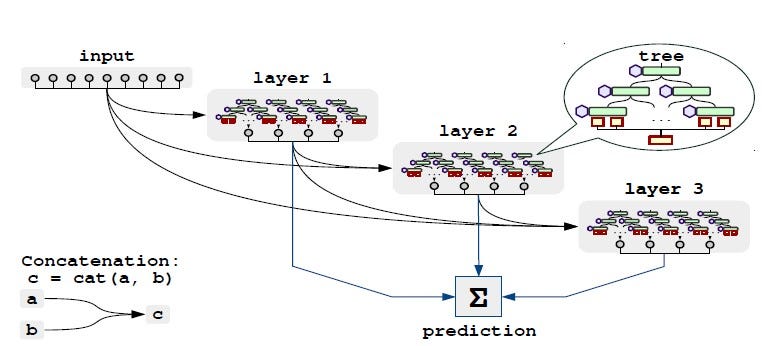
Based on the successful Gradient boosting model CatBoost authors proposed NODE — an ensemble of fully differentiable decision trees that uses entmax transformation and soft splits. Along with proper implementation, it outperformed tree-based models on some datasets mentioned in the research paper, which led to its adoption in the industry[11]. An illustration of NODE architecture is present in figure 4.
Wide&Deep, DeepFM and DNN2LR
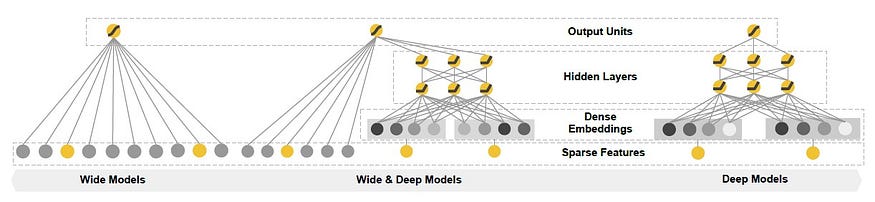
Cheng et al, in 2016, proposed Wide&Deep[2] — a linear model that utilises the hand-crafted logical expression for features along with n-dimensional categorical embedding and combines them with non-linear layers[2]. Architectures of Wide, Deep and Wide&Deep models are illustrated in figure 5. To replace the need for manual feature engineering, Guo et al in DeepFM proposed replacing them with learned Factorisation Machines, efficient in learning associations within high dimensional sparse data[5]. Liu et al in DNN2LR presented an automatic feature crossing method capable of achieving higher performance with Logistic Regression than complex neural networks[10].
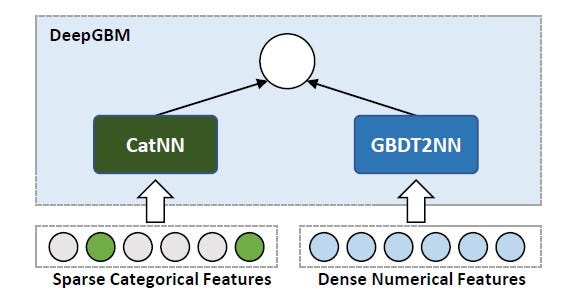
DeepGBM
DeepGBM[8] proposed by Ke et al is partially differentiable with a strong learning capacity that combines two neural networks, CatNN for handling sparse categorical features and GBDT2NN for dense numerical features[8]. Its superior performance over Gradient boosting trees on online prediction is commendable; however, it lacks explainability and possesses some data-related issues. The architecture of DeepGBM model is illustrated in figure 6.
Transformer Based Models
Due to the ubiquitous success of various transformers (based on attention mechanism) on homogeneous data, several authors have advocated their use for tabular learning.
TabNet
TabNet[1] is one of the first deep tabular learning models based on attention mechanisms aimed at offering exceptional performance and interpretability[1]. Like a tree-based model where each decision step is processed in a hierarchical order, it utilises a sub-network at each decision step that uses sequential attention feature selection[1]. The final prediction is an aggregate of the output of all decision steps. It can also utilise unlabelled data via self-supervised learning for improved predictive quality[1]. The architecture of TabNet’ encoder, decoder and feature transformer is illustrated in figure 7.

Tab-Transformer
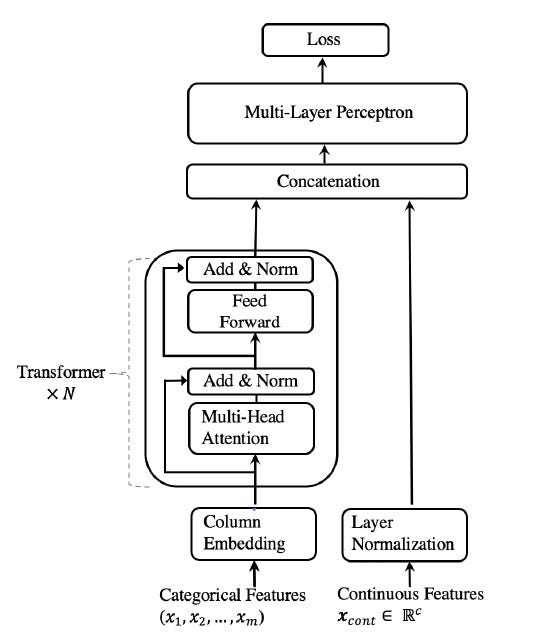
TabTransformer[6], similar to Tab-Net also proposes both supervised and self-supervised methodology[6]. It uses Multi-layer perceptrons, input to which is the combination of numerical features and categorical features mapped to contextual embedding self-attention mechanism[6]. Unsupervised pre-training (on unlabelled data) uses multi-head attention based transformers to create contextual embedding robust to missing and noisy data[6]. The architecture of the TabTransformer model is illustrated in figure 8.
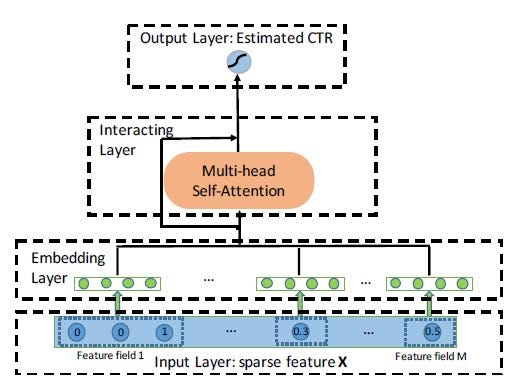
AutoInt
AutoInt[14], initially proposed for click-through rate (CTR) prediction, based on the self-attention mechanism, can learn higher-order feature interactions and their relevance[14]. It uses multiple layers of the multi-head self-attention neural network with residual connections to model feature interaction in low-dimensional space where both categorical and numerical features are mapped[14]. The architecture of the AutoInt model is illustrated in figure 9.
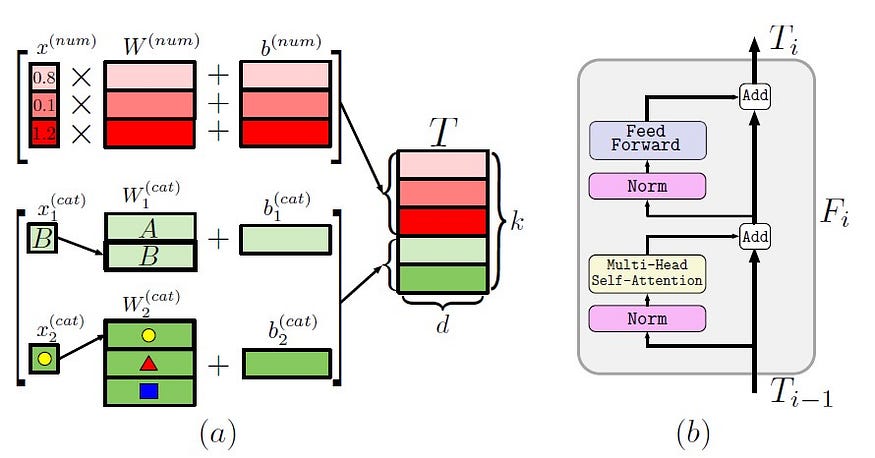
FT-Transformer
FT-Transformer[4] (Feature Tokenizer + Transformer) is similar to AutoInt with some key differences which account for its relative superior performance. It’s identical to AutoInt in transforming all features into embeddings which acts as input for the transformer layer[4]. Additionally, the embedding layer of FT-Transformer also uses feature biases, and the final representation of [CLS] token is used in the PreNorm variant of Transformer for inference mechanism[4]. However, it is found slow and computationally expensive compared to other Deep learning methodologies due to the overhead introduced, which is more prominently visible in larger datasets[4]. The architecture of the FT-Transformer model is illustrated in figure 10.
Regularisation and Modifications
Several practitioners have also proposed regularisation techniques on the existing Neural Networks to improve their performance. They believe that basic architectures such as Multi-layer perceptrons can be tuned to perform at par with Gradient boosting algorithms and even outperform them in some circumstances.
Regularisation Learning Networks (RLN)
In one of the early studies, Ira Shavitt and Eran Segal introduced Regularization Learning Networks (RLNs) fine-tuned using Counterfactual Loss[13]. The resulting sparse network is interpretable, revealing essential features[13]. However, the paper only deals with numerical features, making them less viable for general use.
Regularisation Cocktail
Kadra et al proposed a “regularisation cocktail”, an optimisation paradigm for selecting a subset of regularisation techniques and their subsidiary hyperparameters[7]. The method seems effective but uses significant resources to find optimal parameters and hyperparameters.
MLP+
James Fiedler, too felt that existing networks are under-utilised, and some modifications could make simple architecture like Multi-layer perceptrons competitive to other models and Gradient boosting trees[3]. He coined ”MLP+ block”, the combination of Leaky Gates, MLP sub-block, skip layer and weighted average[3]. The leaky gate combines an element-wise linear transformation and a LeakyReLU, which helps in interpretation and feature selection[3]. Ghost batch norm (GBN) inspired from TabNet is used in place of Batch Normalisation to improve generalisation and increase training speed[3]. The architecture of the original MLP block and modified MLP block called MLP+ is illustrated in figure 11 with modifications marked in grey background.

Conclusion
The survey explains tabular data, its popularity and its extensive use in the industry. It acknowledges the superiority of tree-based models over deep learning-based solutions for tabular data and reasons the advantages of deep learning-based solutions have to offer. The most notable benefits are their use with different modalities of data in end-to-end learning and alleviating the need for feature engineering. We discussed models that utilise CNNs and benefit from transfer learning by converting tabular data into images — then talked through hybrid models, which combine tree-based models and neural networks to create differentiable architectures. Building on attention-based architectures’ success for homogeneous data (text and images), some attention-based models for heterogeneous tabular data were proposed. We also considered some regularisation techniques that could improve existing models’ performance. Tabular data is now starting to get the attention it deserves. Still, the lack of established benchmarks has led to different models being evaluated on various datasets, leading to inaccurate comparison. We’ve also seen some models underperforming on new datasets. With no deep learning based model consistently outperforming other models including Gradient boosting models, tree-based models still act as an effective baseline model with high interpretability essential in real-world use-cases. There is yet to be a conclusive model.
References
[1] Sercan O. Arik and Tomas Pfister. TabNet: Attentive interpretable tabular learning, 2020.
[2] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah. Wide deep learning for recommender systems, 2016.
[3] James Fiedler. Simple modifications to improve tabular neural networks, 2021.
[4] Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data, 2021.
[5] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: A factorization-machine based neural network for ctr prediction, 2017.
[6] Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. Tabtransformer: Tabular data modelling using contextual embeddings, 2020.
[7] Arlind Kadra, Marius Lindauer, Frank Hutter, and Josif Grabocka. Welltuned simple nets excel on tabular datasets, 2021.
[8] Guolin Ke, Zhenhui Xu, Jia Zhang, Jiang Bian, and Tie-Yan Liu. Deepgbm: A deep learning framework distilled by gbdt for online prediction tasks. In KDD ’19 Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery Data Mining, August 2019.
[9] David M. Lane. Introduction to statistics, 2003.
[10] Zhaocheng Liu, Qiang Liu, Haoli Zhang, and Yuntian Chen. Dnn2lr: Interpretation-inspired feature crossing for real-world tabular data, 2021.
[11] Sergei Popov, Stanislav Morozov, and Artem Babenko. Neural oblivious decision ensembles for deep learning on tabular data, 2019.
[12] Alok Sharma, Edwin Vans, Daichi Shigemizu, Keith Boroevich, and Tatsuhiko Tsunoda. DeepInsight: A methodology to transform non-image data to an image for convolution neural network architecture. Scientific Reports, 9, 08 2019.
[13] Ira Shavitt and Eran Segal. Regularization learning networks: Deep learning for tabular datasets, 2018.
[14] Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. AutoInt. Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Nov 2019.
[15] Baohua Sun, Lin Yang, Patrick Dong, Wenhan Zhang, Jason Dong, and Charles Young. Super characters: A conversion from sentiment classification to image classification, 2018.
[16] Baohua Sun, Lin Yang, Wenhan Zhang, Michael Lin, Patrick Dong, Charles Young, and Jason Dong. SuperTML: Two-dimensional word embedding for the precognition on structured tabular data, 2019.
[17] Yitan Zhu, Thomas Brettin, Fangfang Xia, Alexander Partin, Maulik Shukla, Hyunseung Yoo, Yvonne Evrard, James Doroshow, and Rick Stevens. Converting tabular data into images for deep learning with convolutional neural networks. Scientific Reports, 11, 05 2021.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



