



Modern NLP: A Detailed Overview. Part 3: BERT
Last Updated on August 1, 2023 by Editorial Team
Author(s): Abhijit Roy
Originally published on Towards AI.
In my previous articles about transformers and GPTs, we have done a systematic analysis of the timeline and development of NLP. We have seen how the domain moved from sequence-to-sequence modeling to transformers and soon toward a generalized learning approach. In this article, we will talk about another and one of the most impactful works published by Google, BERT (Bi-directional Encoder Representation from Transformers)
BERT undoubtedly brought some major improvements in the NLP domain. Though BERT authors did not propose a very noble architecture, still similar to the GPT work from OpenAI, utilized the modern concepts of NLP like transformers, pretraining, and transfer learning flawlessly to establish superb performance.
Prerequisite
Before we dive into understanding BERT, we need to understand in order to create the model, the authors have used or referenced several concepts and improvements from several other preceding works. We need to have a very good understanding of those concepts to understand the concepts used in BERT finally. The dependencies are Transformers, Semi-supervised Sequence Learning, ULMFit, OpenAI GPT, and ELMo. So, I have discussed all the required topics other than ELMo, I will suggest going through those articles and then coming back to continue the journey for a better understanding, given, the concepts are not known. As for ELMo, no worries, we will start by understanding this concept.
Deep contextualized word representations
This paper was released by Allen-AI in the year 2018. Till then, pre-trained word embeddings like Bag of Words, Word2Vec, and Glove have already gained popularity and have been proven to improve the performance of training models significantly. But, considering the success the only drawback was, the word embeddings obtained from these modelings are based on a generalized approach, not context-specific ones. In simpler words, a word can be used in different contexts in a sentence, the meaning shifts based on the sentence, but the representation or the embedding remains the same. For example, consider these two sentences,
The business deal went well.
Please deal with the issue immediately.
The word “deal” is used in both sentences, but the meanings are different depending on usage, hence both should not be represented by the same embeddings. This is where ELMo comes in.
The authors of ELMo suggest that word embedding should express two things:
(i) The complex characteristics of the word usage in semantic sense and
(ii) how the words are used in varying linguistic contexts.
ELMo addresses both these issues, and produces embeddings or representations of a word, as a function of the entire input sentence. The authors claim that the proposed method can be easily adapted in other models as well and have done so, improvements could be noted.
Architecture: The authors have used a two-layered Bidirectional LSTM to demo the concept. It has been observed that the bi-directionality of the model, i.e, its ability to discover the words both preceding and succeeding it, gives the model an upper hand over the basic single directional LSTM, in a way to understand the context of the full sentence, thus improving the quality of the embedding.
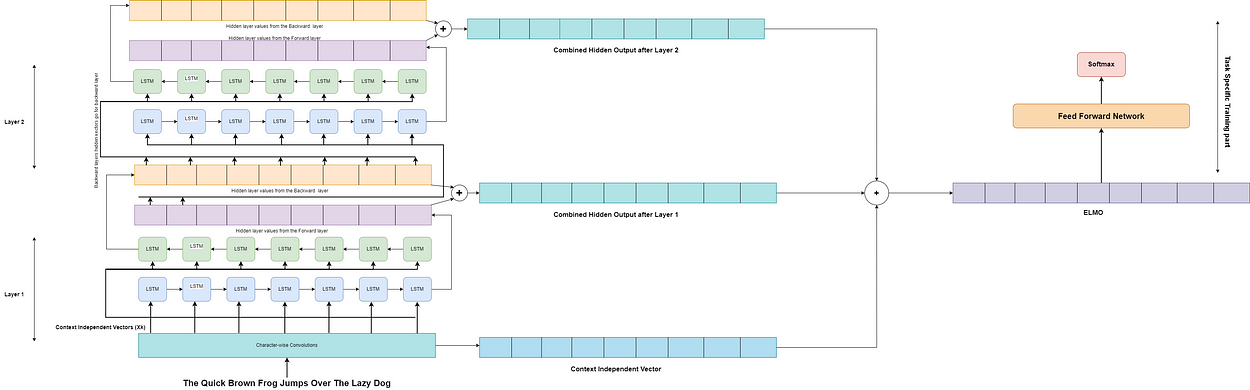
Approach: The authors first pass the sentence through a character-convolutional layer, to create a context-independent vector (Xk), we often do this in LSTM learning problems. The context vector (Xk), for each step k, is passed through 2 LSTM layers. After the first layer (Layer 1) of LSTM, there are 2 intermediate hidden vectors produced(Hk-forward, Hk-backward), one for the forward sequence and another for the backward sequence. The two intermediates are summed to create a final intermediate vector(Hk-final-layer-1) that represents knowledge of the word’s surroundings approaching from both sides. Then, the hidden state vectors are again passed through the second layer (Layer 2) of the LSTM model to create another final intermediate vector(Hk-final-layer-2) for each step or word k. The second intermediate vector has a better scope of information of the context, compared to the first LSTM layer.
Finally, (Hk-final-layer-1),(Hk-final-layer-2), and (Xk) are added to create the final ELMo embedding, which is used for task-specific applications. The authors have established the LSTM model can have more layers and is very easy to add to any model for specific tasks. This kind of approach is called a Feature-Based approach, as compared to the approaches like OpenAI which are Fine-Tuning-Based approaches.
The embedding vector equation is given as:

Paper link: https://arxiv.org/pdf/1802.05365.pdf
Important Conclusion: Bi-directional LSTM models can be used to generate context-based embeddings.
Then, Finally, we come to BERT.

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT was introduced in 2019, by Jacob Devlin and his colleagues from Google. Before we jump into the thorough discussion of BERT architecture and working, let's make some things clear, so that we don’t land into the same confusion I did, while I was exploring these topics.
In the NLP world, there are usually two types of models or tasks broadly, auto-regressive models and auto-encoding models.
Auto-regressive models are the ones, that, on feeding a sentence, or a starting word token, generate words related to the input, for example, GPTs. They are best for tasks like Text generation, translation, and summarization.
The other type of model is the auto-encoding model, which, is responsible for the tasks that involve the understanding of the entire sentence context in order to achieve some tasks better like, classifications, question-answers, entailments, and Name Entity Recognitions, that is, finding a particular entity in a text. In our current Google searches, we see this application from time to time, where, on web pages, the lines matching our search query get highlighted.
Now, don’t get me wrong, I am not saying, regressive models can’t be used for encoding tasks and vice versa, I am just saying the models are more suitable in their own domain.
BERT is designed as an Auto-Encoding model, so whereas models like GPT use the decoder portion of the transformer, the BERT model consists of only the Encoder portion of the transformer. The question is, WHY?
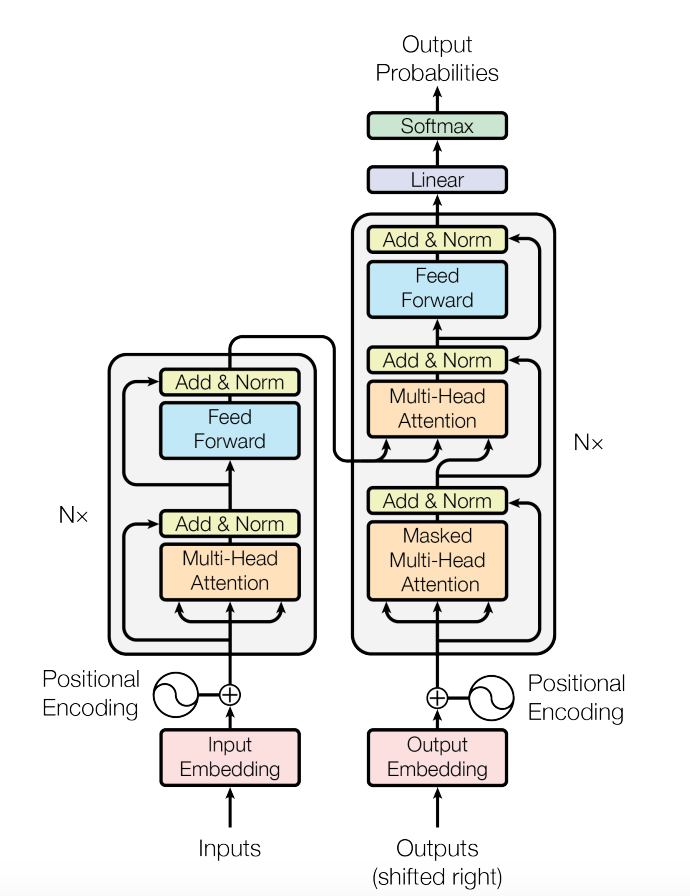
If we see the architecture, the Decoder takes in the output, or on the first step, takes the start token, applies self-attention, and produces the probabilities of the next word, so, it only sees the previous tokens or words or has knowledge of only previous contexts, so it is best for regressive models, as they are basically trained to produce words. But the encoder is the part that sees the entire sentence together, and hence has the entire context and can produce better inferences, which is suitable for auto-encoding tasks.
Inclusion of ELMo to support feature-based embedding: The authors of the BERT paper argued that, in the case of certain tasks, only a left-to-right learning approach is a very high price to pay, as the knowledge of the context after the word is lost. BERT introduced bi-directional learning, that is it will learn the word from left-to-right and right-to-left as well using self attention. The authors also focused on the two types of learning approaches devised so far, Feature Based learning approach like ELMo and Fine-tuning based learning like OpenAI’s GPT. BERT brought the best of both worlds together. As we already learned, Bi-LSTM-based ELMo is easy to integrate into a model. So, taking advantage of the encoder, to receive the entire sentence as input at once, BERT added ELMo, to generate high-quality context-dependent Embedding for the words, which enriched the performance.
Pre-training and GPT: The authors also realized that pre-training contributes majorly to the performance of the model and is highly necessary. So, it was decided to use GPT’s pre-training and fine-tuning technique at the end to achieve completely what fine-tuning-based approaches had to offer. The issue was, GPT training is suited only for left-to-right or forward predicting models, but BERT had bi-directional data. There was another issue that, if a normal language modeling task is used to pre-train, the model might try to bypass the learning and leak data from the right-to-left model to left-to-right and vice versa. To eradicate the issues, the authors introduced an MLM or Masked Language Modelling task the primary pretraining task, which basically means randomly a word is masked in the text, and the model has to predict the masked word.
Architecture and Training:
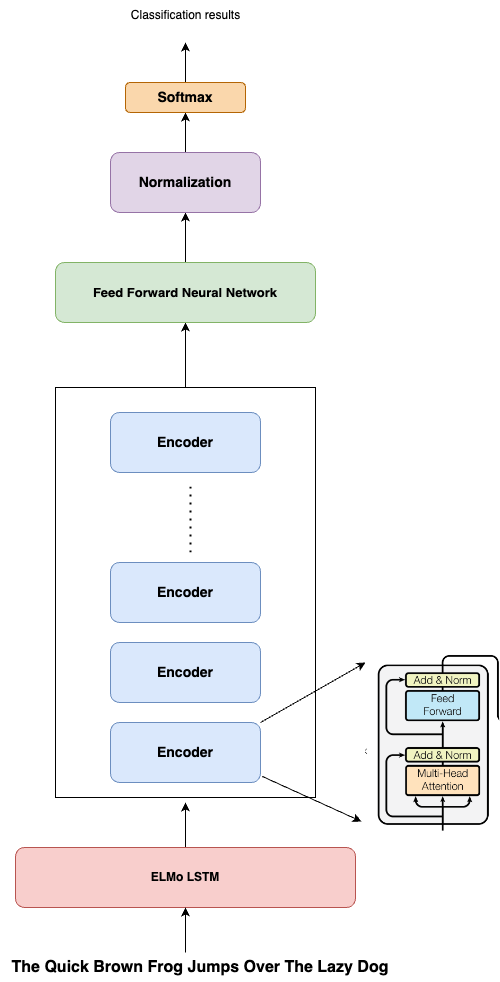
BERT uses an encoder-based architecture of the transformer as given by Vaswani et al., without much change. BERT has released two models BERT-Base and BERT-Large. BERT-Base contains 12 encoder layers, a hidden layer vector of size 768, and 12 self-attention heads in each block, resulting in approximately 110 million parameters, whereas BERT-Large has 24 encoder layers, each with 16 attention heads handling 1024 sized vector resulting in a total of 340 million parameters.
BERT is also trained in a 2 step approach: Pre-training followed by Fine Tuning. In BERT’s case, Pre-training is done using two tasks:
- Masked Language Modeling: In this case, randomly, 15% of words in the text are masked and the model has to use the context of the sentence to predict the word.
- Next Sentence Prediction: As BERT targets to be used for tasks like question answers and entailments, it is important for BERT to learn to analyze the context for longer sequences. So, in this case, the model is passed sentence and told to predict the next sentence. In order to train, the authors have considered 50% of cases where the sentence appearing next is the real next sentence (IsNextSequence), and in 50% of others, it's not (IsNotNextSequence). A SoftMax layer is added to the top of the model to provide a probability between these two cases.
For the input, if it's a single sentence, a [CLS] token is added in the front, which denotes the classification task as the authors explain. For tasks like sentence similarity and question answering, the authors have put a separator [SEP] token in the middle to differentiate the sentences, then we will put the context embedding vectors of the sentence, to the side they belong to. For the pre-training corpus authors used the BooksCorpus (800M words) and English Wikipedia (2,500M words). For Wikipedia, we extract only the text passages and ignore lists, tables, and headers.
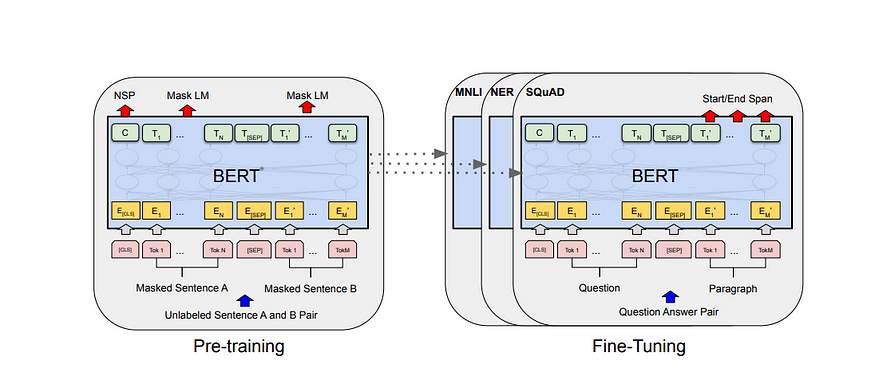
Fine-Tuning BERT to a specific target task happens very easily, as we have seen in the case of the other Fine-tuning based learning approaches. For tasks like question answers and similarity, sentences are concatenated using a separator. The token embeddings for the sentences are added with segmentation embeddings to determine which sentence the word belongs to which sentence and a positional embedding, as shown in the original transformer paper, to indicate the positions of the word in the sentence.
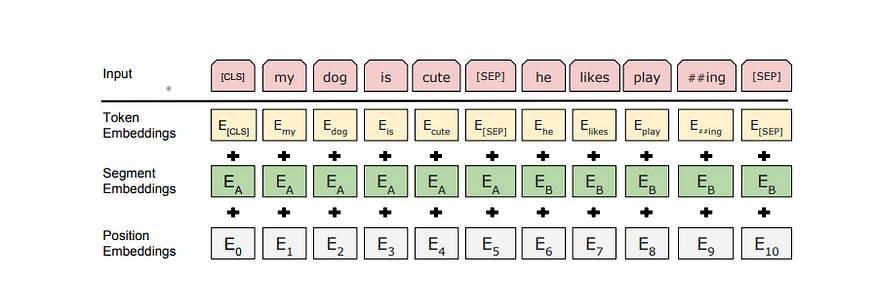
The above image shows the creation of the final token embeddings for learning.
Paper link: https://arxiv.org/pdf/1810.04805.pdf
This is all about how a BERT model works. Now, we will briefly see two works that have been done based on BERT, which has been immensely used and successful.
RoBERTa: A Robustly Optimized BERT Pretraining Approach
In 2019, a team led by Yinhan Liu from Meta AI research published this work on improving the performance of BERT using a robustly optimized training approach. They used BERT-Large to test the assumptions.
The authors made the following changes:
- The BERT, while training, added a segmentation encoding to the token embedding to understand which sentence the words belonged to. RoBERTa removed the encoding and instead added a tokenizer. Separator character to separate the sentences.
- BERT was initially trained on 16GB data, while RoBERTa introduced its own novel dataset combining the dataset from
(1) BERT (16GB),
(2) CC-NEWS, which we collected from the English portion of the CommonCrawl News database (76 GB),
(3) OPENWEBTEXT, an open-source recreation of WebText where the text is web content extracted from URLs shared on Reddit with at least three upvotes. (38 GB)
(4) STORIES, a dataset containing a subset of CommonCrawl data filtered to match the story-like style of Winograd schemas. (31GB)
Resulting in a total size of 160GB. The authors claim that a bigger dataset helped the model get a more compact and comprehensive pre-trained weight. - BERT uses an MLM or masked language modeling technique, but the masking is done while pre-processing, so basically, there is a pattern of the masking, and it becomes static, which the learning model can detect, decaying the generalized performance. Instead, RoBERTa introduced dynamic masking done at runtime. So, the input sequence is trained for 40 epochs with 10 different masking patterns, so each of the masking patterns appears 4 times, bringing variation and preventing the model from learning the masking pattern.
- The authors of RoBERTa found that the Next Sentence Prediction objective of BERT in pre-training slightly hurts the performance of the model in downstream tasks, as it affects the model’s ability to learn long-range dependencies. So, that pre-training target is removed.
- From previous works, it was established that speed and performance optimization can be increased if the learning rate and mini-batch sizes are increased properly. Originally BERT trained for 1 million steps using a batch of 256 sequences. Keeping the amount of memory requirements fixed, authors of RoBERTa, discovered the model can train on either train for 125k steps on a 2K sequence batch or 31k steps on an 8K batch. After some ablations, the authors decided on an 8K batch size.
- RoBERTa introduced a modification in the input representation as well. BERT originally used a character-level BPE or byte-pair encoding of 30K vocabulary, while RoBERTa increased it to a vocabulary of 50K byte-level word units.
We have listed all the points of improvement of RoBERTa over BERT, which has been used extensively by later works to improve the performance of BERT.
Paper link: https://arxiv.org/pdf/1907.11692.pdf
Next, we will see one last and so far the most used variant of BERT: DistilBERT.
DistilBERT, a distilled version of BERT: smaller, faster, cheaper, and lighter
This work was published by hugging face in 2020 with the aim of reducing the BERT architecture and time consumed to train the model. The authors observed that the training data and the model size were exponentially increasing with each work, as a requisite for state-of-the-art performance, which made it extremely difficult to train and use such models under memory constraints. To solve this issue, DistilBERT was introduced which, through the method of knowledge distillation training, claimed to reduce, the size of the BERT model by 40%, and its training time by 60% while retaining 97% of its performance.
Knowledge Distillation is a method where 2 different models are used, one is known as the Teacher model, and another is called the Student model.
Knowledge distillation [Bucila et al., 2006, Hinton et al., 2015] is a compression technique in which a compact model — the student — is trained to reproduce the behaviour of a larger model — the teacher — or an ensemble of models.
So, DistilBERT becomes the student model and BERT becomes the teacher. As we know, in the case of supervised learning, a well-trained model predicts if an instance belongs to a class with a very high probability and if not with a very low value. Sometimes the values are neither too high nor too low. Such cases are used by the student to optimize, as the easy cases are already out leaving distilled samples to learn from.
DistilBERT model is very similar to BERT, only the number of encoder layers is factored by 2. So, DistilBERT has 6 encoder layers. The student model is initialized with BERT’s pre-trained weights only as they are very similar in architecture. For each two-layer in BERT, the authors have selected one layer’s weight for each layer of DistilBERT.
DistilBERT trains on the same corpus as the original BERT model: a concatenation of English Wikipedia and Toronto Book Corpus. The loss function is a summation of the Distill Loss, a Cosine Embedding Loss function that tries to reduce the distance between the hidden vectors produced by the teacher and student, and the actual Masked Language modeling loss, which was used in the original BERT paper.
Paper link: https://arxiv.org/pdf/1910.01108.pdf
Conclusion
In this article, we have tried to learn all about BERT and its improvements. In the later parts of this series, we will see more developments in this domain.
Till then, Happy Reading!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



