



Importance of Choosing the Correct Hyper-parameters While Defining a Model
Last Updated on July 25, 2023 by Editorial Team
Author(s): Saikat Biswas
Originally published on Towards AI.
Hyper-parameter Optimization U+007C Towards AI
Often considered the trickiest part of optimizing a machine learning algorithm. Correct hyperparameter tuning can save a lot of time and help deploy the ML model faster
We all machine learning aficionados must have participated in hackathons to test our skills in Machine Learning sometime or the other. Well, Some problem statement that we need to solve could be related to regression and some could be on classification. Let’s suppose, we are in one, and we have done all the hard work of pre-processing the data, worked hard on generating new features, applied them to our data to get the base model.
So, now that we have our base model, we want to test the model on unseen data and we do that. We see an accuracy (could be something else based on the problem statement) that we feel is okayish. But, we can still try to improve the performance of the model by tuning the parameters. Familiar with this feeling?
How we do that? Parameters and Hyperparameters. I’m sure we must have heard these terms a lot in Machine Learning, more so, in Deep Learning. Let’s see what do these terms mean.
Model parameters are the properties of the training data that are learnt during training by the classifier or other ML models. For example, in the case of some NLP task: word frequency, sentence length, noun or verb distribution per sentence, the number of specific character n-grams per word, lexical diversity, etc. Model parameters differ for each experiment and depend on the type of data and task at hand.
Model hyperparameters, on the other hand, are common for similar models and cannot be learnt during training but are set beforehand. A typical set of hyperparameters for NN(Neural Network) include the number and size of the hidden layers, weight initialization scheme, learning rate and its decay, dropout and gradient clipping threshold, etc.
In other words, Parameters are those that are learnt by the machine like weights and Biases. Hyperparameters are those which we supply to the neural network, for example- number of hidden layers, input features, Learning rate, Activation functions etc.
Hyperparameters are the knobs that we can tune when building our machine / deep learning model. Simple..!!!
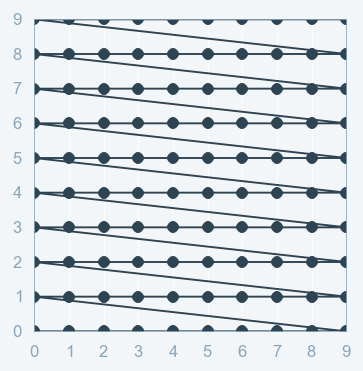
Now, Let’s see the types of Hyperparameter tuning that we have in place, in general, for Machine Learning Algorithms. We will see them one by one.
Grid Search(GS):– As the name indicates, Grid-searching is the process of scanning the data to configure optimal parameters for a given model in the grid. What this means is that the parameters search is done in the entire grid of the selected data.
This is kind of important as the entire performance of the model is dependent on the hyperparameters specified. Let’s see a basic code snippet of performing Grid Search on a Model for Hyperparameter tuning.
#Example of Grid Search
# Load the dataset
x, y = load_dataset()# Create model for KerasClassifier
def create_model(hparams1=dvalue, hparams2=dvalue, ... hparamsn=dvalue): ...model = KerasClassifier(build_fn=create_model) # Define the range
hparams1 = [2, 4, ...]
hparams2 = ['elu', 'relu', ...]
...
hparamsn = [1, 2, 3, 4, ...]# Prepare the Grid
param_grid = dict(hparams1=hparams1,
hparams2=hparams2,
...
hparamsn=hparamsn)# GridSearch in action
grid = GridSearchCV(estimator=model,
param_grid=param_grid,
n_jobs=,
cv=,
verbose=)
grid_result = grid.fit(x, y)# Show the results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
One point to remember while performing Grid Search is that the more parameters we have, the more time and space will be taken by the parameters to perform the search. This is where the Curse of Dimensionality comes to picture too. This means the more dimensions we add, the more the search will explode in time complexity(by an exponential factor ), ultimately making this strategy unfeasible.
Point to Note:- Don’t use Grid Search if there are more than 3 or 4 dimensions to search as more the number of dimensions the search has to perform, the search dimension would explode and will take a lot of time to perform the entire search which can get very Computationally expensive.
Random Search(RS): Another type of Hyperparameter tuning is called Random Search. Random Search does its job of selecting the parameters randomly. It is similar to Grid Search, but it is known to yield better results than Grid Search. The drawback of random search is, it yields high variance during computing. Since the selection of parameters is completely random; and since no intelligence is used to sample these combinations, luck plays its part.
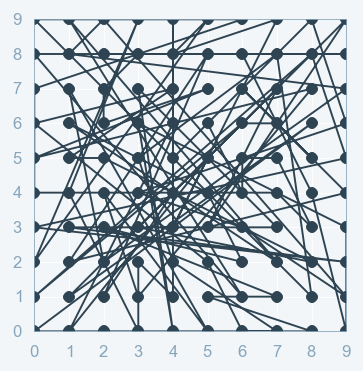
It is good at testing a wide range of values and normally it reaches a very good combination very fast, but the problem is that it doesn’t guarantee to give the best parameters combination.
## Example of Random Search
# Load the dataset
X, Y = load_dataset()# Create model for KerasClassifier
def create_model(hparams1=dvalue, hparams2=dvalue, ... hparamsn=dvalue): ...model = KerasClassifier(build_fn=create_model) # Specify parameters and distributions to sample from
hparams1 = randint(1, 100)
hparams2 = ['elu', 'relu', ...]
...
hparamsn = uniform(0, 1)# Prepare the Dict for the Search
param_dist = dict(hparams1=hparams1,
hparams2=hparams2,
...
hparamsn=hparamsn)# Search in action!
n_iter_search = 16 # Number of parameter settings that are sampled.
random_search = RandomizedSearchCV(estimator=model,
param_distributions=param_dist,
n_iter=n_iter_search,
n_jobs=,
cv=,
verbose=)
random_search.fit(X, Y)# Show the results
print("Best: %f using %s" % (random_search.best_score_, random_search.best_params_))
means = random_search.cv_results_['mean_test_score']
stds = random_search.cv_results_['std_test_score']
params = random_search.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
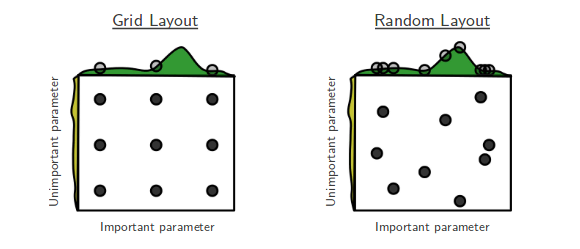
The above image compares the two approaches by searching the best configuration on two hyperparameters space.
But, unfortunately, both Grid Search and Random Search share a common downside which is “Each new guess is independent of the previous run!” which means both GS and RS do not take into account the previous computation of the Hyperparameter search.
Hence, there is a need for a New type of Hyperparameter search that is both effective and drives the search and experimentation effectively by using the past as a resource to improve the next runs. Welcome Bayesian Optimization.
Bayesian Optimization: Bayesian Optimization attempts to find the global optimum in a minimum number of steps. The next set of hyperparameters are selected based on a model of the objective function called a surrogate. To understand Bayesian Optimization clearly, first, we need to understand the concept of a Surrogate function. The Surrogate function, also called response surface is the probability representation of the objective function using previous evaluations. A Surrogate function is a bit easier to optimize than the objective function.
Bayesian optimization works by constructing a posterior(distribution of possible unobserved values conditional on the observed values) distribution of functions (Gaussian Process) that best describes the function you want to optimize. As the number of observations grows, the posterior distribution improves, and the algorithm becomes more certain of which regions in parameter space are worth exploring and which are not.
A Gaussian Process is a stochastic process (a collection of random variables indexed by time or space), such that every finite collection of those random variables has a multivariate normal distribution, i.e. every finite linear combination of them is normally distributed. In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions.
The Gaussian Process falls under the class of algorithms called Sequential Model-Based Optimization (SMBO). Sequential model-based optimization (SMBO) methods (SMBO) are a formalization of Bayesian optimization. The sequential refers to running trials one after another, each time trying better hyperparameters by applying Bayesian reasoning and updating a probability model (surrogate). Several common choices for the surrogate model are Gaussian Processes, Random Forest Regressions, and Tree Parzen Estimators (TPE).
The Steps in Bayesian Distribution(Sequential Model-Based Optimization (SMBO)):-1.A domain of hyperparameters over which to search2.An objective function which takes in hyperparameters and outputs a score that we want to minimize (or maximize)3.The surrogate model of the objective function4.A criteria, called a selection function, for evaluating which hyperparameters to choose next from the surrogate model5.A history consisting of (score, hyperparameter) pairs used by the algorithm to update the surrogate model
Bayesian Optimization in code:-
#Bayesian Optimization in codedef data():"""
Defining a function that defines the data
"""# Load / Cleaning / Preprocessing
...
return x_train, y_train, x_test, y_test
def model(x_train, y_train, x_test, y_test):"""
Model providing function:
Create Keras model with double curly brackets dropped-in as needed.
"""
return {'loss': <metrics_to_minimize>, 'status': STATUS_OK, 'model': model}
# SMBO - TPE in action
best_run, best_model = optim.minimize(model=model,
data =data,
algo=tpe.suggest,
max_evals=,
trials=Trials())# Show the results
x_train, y_train, x_test, y_test = data()
print("Evalutation of best performing model:")
print(best_model.evaluate(x_test, y_test))
print("Best performing model chosen hyper-parameters:")
print(best_run)
Putting it All Together
Bayes SMBO is probably the best candidate as long as resources are not a constraint for us, but we should also consider establishing a baseline with Random Search. After all, the ultimate goal of Hyperparameter Tuning is to reduce the time taken to search the most optimized parameters and we want that to happen in the least possible time. “So, can optimize the training time?”.
Yes, we can. Enter Early Stopping. Early Stopping provides a great mechanism for preventing a waste of resources when the training is not going in the right direction.
Many prominent Deep Learning frameworks provide the function of Early Stopping and even better a suite of super useful callbacks.
A callback is a set of functions to be applied at given stages of the training procedure. #Example in Keras
keras.callbacks.Callback()#EarlyStopping
keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=0,
verbose=0, mode='auto', baseline=None, restore_best_weights=False)
Now if we remember, At the beginning of the article, we named it as Importance of Choosing the Correct Hyper-parameters while defining a model. I think we can see the idea behind it now. Since hyperparameters tuning take up most of the time while working on a model and they decide the performance, in the long run, we need to take steps to tune them, that in turn, decides the stability of the model. Choosing Correct Hyperparameters for our model will not only decide the time taken by a model to reach its convergence but can also decide the decisions and iterations needed to get better results faster.
Until next time…Ciao..!!!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



