



How Does an LLM Generate Text?
Last Updated on November 5, 2023 by Editorial Team
Author(s): Ivan Reznikov
Originally published on Towards AI.
The original article was published on my LinkedIn page.
All the code is provided on Github and Colab
Read more about LLMs in my Langchain 101 series:
LangChain 101: Part 2ab. All You Need to Know About (Large Language) Models
This is part 2ab of the LangChain 101 course. It is strongly recommended to check the first part to understand the…
pub.towardsai.net
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com
Generating Text
Let’s look at the text generation overview.
- The input text is passed to a tokenizer that generates token_id outputs, where each token_id is assigned as a unique numerical representation.
- The tokenized input text is passed to the Encoder part of the pre-trained model. The Encoder processes the input and generates a feature representation that encodes the meaning and context of the input. The Encoder was trained on large amounts of data, which we benefit from.
- The Decoder takes the feature representation from the Encoder and starts generating new text based on that context token by token. It uses previously generated tokens to create new tokens.
Today, we’ll concentrate on the third step — decoding and generating text. If you’re interested in the first two steps, comment below. I’ll also consider covering those topics.
Decoding the outputs
Let’s dive now a bit deeper. Say we want to generate the continuation of the phrase “Paris is the city …”. The Encoder (we’ll be using Bloom-560m model (link to code in the comments)) sends logits for all the tokens we have (if you don’t know what logits are — consider them as scores) that can be converted, using softmax function, to probabilities of the token being selected for generation.

If you look at the top 5 output tokens, they all make sense. We can generate the following phrases that sound legit:
- Paris is the city of love.
- Paris is the city that never sleeps.
- Paris is the city where art and culture flourish.
- Paris is the city with iconic landmarks.
- Paris is the city in which history has a unique charm.
The challenge now is to select the appropriate token. And there are several strategies for that.
Greedy sampling
Simply put, in a greedy strategy, the model always chooses the token it believes is the most probable at each step — it doesn’t consider other possibilities or explore different options. The model selects the token with the highest probability and continues generating text based on the selected choice.

Using a greedy strategy is computationally efficient and straightforward, but it comes with the cost of getting repetitive or overly deterministic outputs occasionally. Since the model only considers the most probable token at each step, it may not capture the full diversity of the context and language or produce the most creative responses. The model’s short-sighted nature solely focuses on the most probable token at each step, disregarding the overall impact on the entire sequence.
Generated output: Paris is the city of the future. The
Beam search
Beam search is another strategy used in text generation. In beam search, the model assumes a set of the top “k” most probable tokens instead of just considering the most likely token at each step. This set of k tokens is called a “beam.”
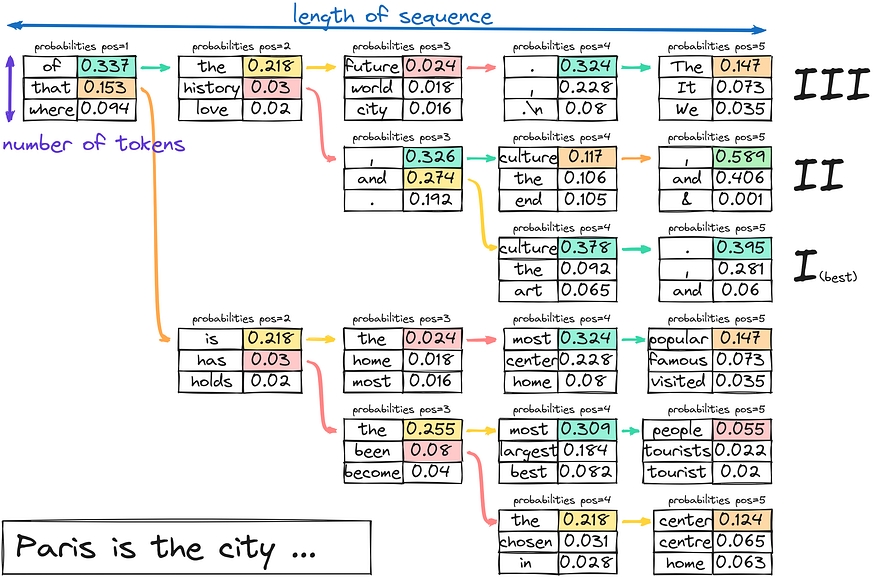
The model generates possible sequences for each token and keeps track of their probabilities at each step of text generation by expanding possible lines for each beam.
This process continues until the generated text’s desired length is reached or an “end” token is encountered for each beam. The model selects the sequence with the highest overall probability from all the beams as the final output.
From an algorithmic perspective, creating beams is expanding a k-nary tree. After creating the beams, you select the branch with the highest overall probability.
Generated output: Paris is the city of history and culture.
Normal random sampling or direct use of probability

The idea is straightforward — you select the next word by choosing a random value and mapping it to the token got picket. Imagine it as spinning a wheel, where the area of each token is defined by its probability. The higher the probability — the more chances the token would get selected. It is a relatively cheap computational solution, and due to high relative randomness — the sentences (or token sequence) will probably be different every time.
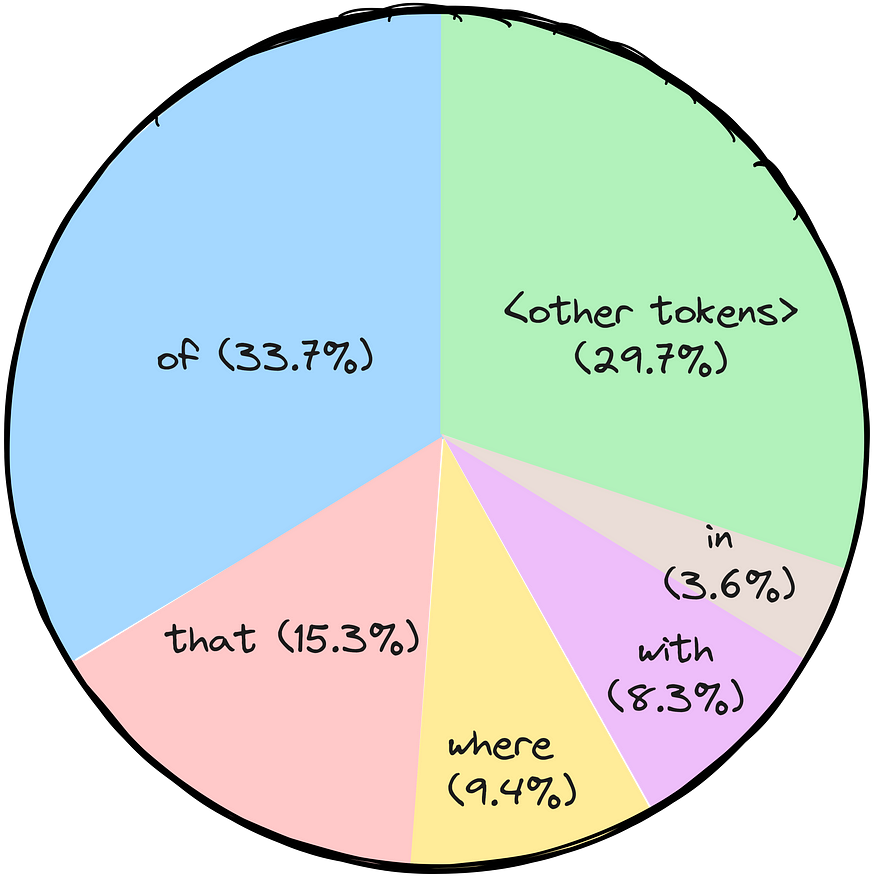
Random sampling with Temperature
As you might recall, we’ve been using the softmax function to convert logits to probabilities. And here, we introduce temperature — a hyperparameter that affects the randomness of the text generation. Let’s compare the activation functions to understand better how temperature affects our probability calculations.
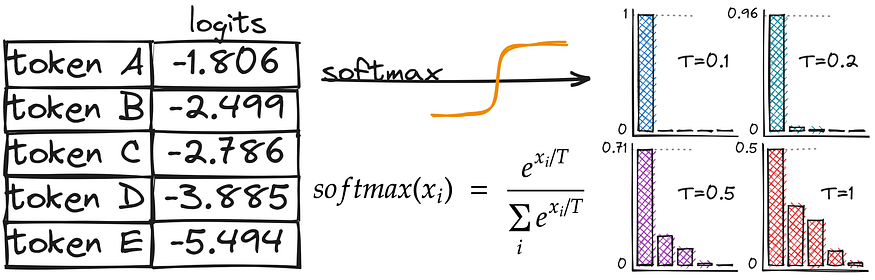
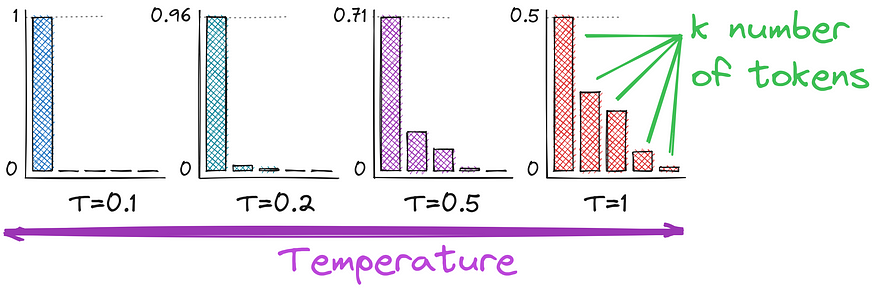
As you may notice, the difference is in the denominator — we divide by T. Higher values of temperature (e.g., 1.0) make the output more diverse, while lower values (e.g., 0.1) make it more focused and deterministic. T = 1 will lead to the initial softmax function we used initially.
Top-k sampling
We can now shift probabilities with temperature. Another enhancement is to use top-k tokens rather than all of them. This will increase the stability of the text generation, not decreasing creativity too much. It’s now random sampling with temperature for only top k tokens. The only possible issue might be selecting the number k, and here is how we can improve it.
Nucleus sampling or top-p sampling
The distribution of token probabilities might be very different, which can bring unexpected results during text generation.

Nucleus sampling is designed to address some limitations of different sampling techniques. Instead of specifying a fixed number of “k” tokens to consider, a probability threshold “p” is used. This threshold represents the cumulative probability you want to include in the sampling. The model calculates the probabilities of all possible tokens at each step and then sorts them in descending order.
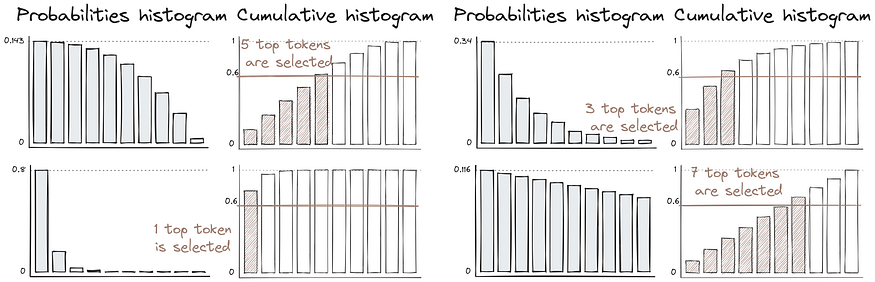
The model continues adding tokens to the generated text until the sum of their probabilities surpasses the specified threshold. The advantage of nucleus sampling is that it allows for more dynamic and adaptive token selection based on the context. The number of tokens selected at each step can vary depending on the probabilities of the tokens in that context, which can lead to more diverse and higher-quality outputs.
Conclusion
Decoding strategies are crucial in text generation, primarily with pre-trained language models. If you think about it, we have several ways to define probabilities, several ways to use those probabilities and at least two ways to determine how many tokens to consider. I’m leaving a summary table below to wrap up the knowledge.
Temperature controls the randomness of token selection during decoding. Higher temperature boosts creativity, whereas lower temperature concerns coherence and structure. While embracing creativity allows for fascinating linguistic adventures, tempering it with stability ensures the elegance of the generated text.
Afterword
Check out how LLMs are used in langchain:
LangChain 101: Part 2ab. All You Need to Know About (Large Language) Models
This is part 2ab of the LangChain 101 course. It is strongly recommended to check the first part to understand the…
pub.towardsai.net
LangChain 101: Part 2c. Fine-tuning LLMs with PEFT, LORA, and RL
All you need to know about fine-tuning llms, PEFT, LORA and training large language models
pub.towardsai.ne
I would appreciate your support if you’ve enjoyed the illustrations and the article content. Until next time!
This article is part of the ongoing LangChain 101 course:
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com
Reminder: The complete code is available on GitHub.

Clap and follow me, as this motivates me to write new parts and articles 🙂 Plus, you’ll get notified when the new articles will be published.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


