



Why Batch Normalization Matters?
Last Updated on July 20, 2023 by Editorial Team
Author(s): Aman Sawarn
Originally published on Towards AI.
Understanding why batch normalization works, along with its intuitive elegance.
Batch Normalization(BN) has become the-state-of-the-art right from its inception. It enables us to opt for higher learning rates and use sigmoid activation functions even for Deep Neural Networks. It addresses gradient vanishing and gradient explosion by countering the Internal Covariate shift.
Let’s go through the terms one-by-one and understand why BN matters?
1. Normalization
The numerical features are normalized before being fed into Machine Learning or deep learning models so that the data could become scale-independent.
x_new=(x_old- x_min)/ (x_max-x_min)
In the case of neural networks, generally, they fasten the optimization process and thus speed up the training. For more details on why normalization is required before training neural networks, click here.

2. Internal Covariate shift
A quick refresher about neural networks- While training neural networks, the data points are feed into the training network. Then the error between the expected value and the output value from the network is calculated. It is then optimized using various techniques like SGD, AdaDelta, AdaBoost, Adam, etc.
In the context of neural networks, they are optimized using batches of data being fed into the network. If the training and test data have different sources, if they will have different distributions. These batches of inputs can have a different distribution, i.e. a slightly varying mean and variance from the sample (i.e., entire dataset considered) mean and variance.
The weights of various layers of the neural networks are updated while training. This means that the activation function changes throughout training, and these weights are then fed into the next layer. Now, when the input distribution of the next batch(or set of inputs) is different, the neural network is forced to change and adapt according to the changing input batches. So, training neural networks becomes much more complex when the values of parameters change continuously with new input batches. This changing parameter value slows down the training process by requiring lower learning rates and more careful optimization. We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training. Refer to the original paper for more details.

Batch Normalization is the solution to the internal covariate shift and makes the optimization care less about the initialization.
3. Addressing the Internal Covariate Shift
It is already known that the loss function would converge faster if it is whitened — i.e., linearly transformed to have zero means and unit variances, and decorrelated. This whitening process could be done at every step of training or a fixed interval. If the input data batches have been whitened(either at every training step or some intervals), it would be a step towards addressing the Internal covariate shift. But here is what the problem would occur.
Excerpts from the original paper:
We could consider whitening activations at every training step or at some interval, either by modifying the network directly or by changing the parameters of the optimization algorithm to depend on the network activation values (Wiesler et al., 2014; Raiko et al., 2012; Povey et al., 2014; Desjardins & Kavukcuoglu). However, if these modifications are interspersed with the optimization steps, then the gradient descent step may attempt to update the parameters in a way that requires the normalization to be updated, which reduces the effect of the gradient step. For example, consider a layer with the input u that adds the learned bias b, and normalizes the result by subtracting the mean of the activation computed over the training data: xb = x − E[x] where x = u + b, X = {x1…N } is the set of values of x over the training set and E[x]=(1/N)*sum(x) for entire training data X. If a gradient descent step ignores the dependence of E[x] on b, then it will update b ← b + ∆b, where ∆b ∝ −∂ℓ/∂xb. Then u + (b + ∆b) − E[u + (b + ∆b)] = u + b − E[u + b]. Thus, the combination of the update to b and subsequent change in normalization led to no change in the output of the layer nor, consequently, the loss. As the training continues, b will grow indefinitely while the loss remains fixed. This problem can get worse if the normalization not only centers but also scales the activations. We have observed this empirically in initial experiments, where the model blows up when the normalization parameters are computed outside the gradient descent step.
To address the problem with this approach, we make sure that for any parameter values, the network produces activations with the desired distribution- as it would allow the gradient of the loss function to account for the normalization. Also, it could be seen that the whitening of each layer would make training even more complex.
So, we make two assumptions to simplify the optimization process. 1. Instead of whitening the input features and output together, we normalize the features separately with mean 0 and variance 0f 1. This normalization is done separately for all the d-dimensions present in the dataset.
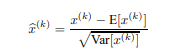
The first is that instead of whitening the activations in layer inputs and outputs jointly, we will normalize each scalar feature independently, by making it have the mean of zero and the variance of 1. For a layer with d-dimensional input x = (x (1) . . . x(d) ), we will normalize each dimension independently. 2. For all the mini-batches in stochastic gradient training, an estimate is made for the mean and variance values.
Since we use mini-batches in stochastic gradient training, each mini-batch produces estimates of the mean and variance of each activation. This way, the statistics used for normalization can fully participate in the gradient backpropagation.
But simply normalizing layers would change what that layer represents. To address this, we make sure that the transformation inserted in the network can represent the identity transform. For this purpose, we introduce two parameters γ (k), β(k), which could both scale and normalize the dataset for each activation x (k). And now, the best part is that these parameters could be learned over the training process along with the original model parameters.

4. Batch Normalization
Let’s consider a mini-batch B of size m. Due to our simplifications, we normalize the activations independently. So, let’s take one activation x(k) and remove k for clarity. There are m values in the mini-batch.

Let the normalized values be xb(from 1 to m), and their linear transformations are y(from 1 to m). This scaled y is scaled and shifted to the next layer.

Let’s see the entire batch normalization algorithm now. In the algorithm, epsilon is a constant added to the mini-batch variance for numerical stability.
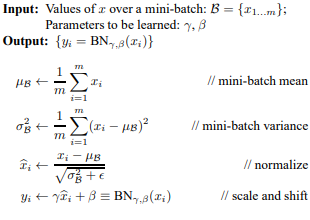
Batch Normalization doesn’t process each training example separately. In practice, BNγ,β(x) depends on both training examples and other examples in the dataset.
5. Why Batch Normalization matter?
Batch Normalization regularizes the model. Batch Normalization also enables a higher learning rate and thus faster convergence of the loss function. It is different from Dropout in a way that dropout reduces overfitting. But for Batch Normalized layers, dropout is not necessary. Also, Batch Normalization removes the need for L2 regularization.
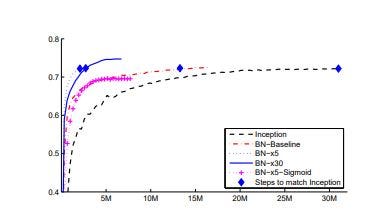
6. Conclusions
This blog explains the mechanism for batch normalization and how it addresses the internal covariant shift. It also gives an intuition on how simple the whitening process does not work, and the manipulations needed to make it work.
7. References
- https://arxiv.org/pdf/1502.03167.pdf
- https://www.jeremyjordan.me/batch-normalization/
- https://mlexplained.com/2018/01/10/an-intuitive-explanation-of-why-batch-normalization-really-works-normalization-in-deep-learning-part-1/
- https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html
- https://towardsdatascience.com/pitfalls-of-batch-norm-in-tensorflow-and-sanity-checks-for-training-networks-e86c207548c8
https://www.linkedin.com/in/aman-s-32494b80/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

