



What Are Baseline Models and Benchmarking For Machine Learning, Why We Need Them?
Last Updated on January 31, 2022 by Editorial Team
Author(s): Hasan Basri Akçay
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Machine Learning
What Are Baseline Models and Benchmarking For Machine Learning, Why We Need Them? Part 1 Classification
Random, Machine Learning, Automated ML Baseline Models and Benchmarking For ML…
We can train a machine learning model with any prepared data but how can we be sure about the machine learning model learned from train data? The objective of this article is to explain baseline models in data science.
You can see the dataset here and you can see full python code at the end of the article.
What is Baseline Model?
The baseline models are references for our trained ML models. With baseline models, data scientists try to explain how their trained model is good and the score of the baseline model is the threshold for the data scientist.
What are Types of Baseline Model?
There are three types of the baseline model that are Random Baseline Models, ML Baseline Models, and Automated ML Baseline Models.
Random Baseline Models
In the real world, data can not always be predictable. In these such problems, the best baseline model is a dummy classifier or dummy regressor. That baseline model shows you to your ml model is learning or not. You can see how to use random baseline models below.
Firstly we create a random dataset for classification.
import pandas as pd
import numpy as np
np.random.seed(0)
random_dim = (1000,3)
random_X = np.random.random(random_dim)
random_reg_y = np.random.random(random_dim[0])
random_clf_y = np.random.randint(random_dim[1], size=random_dim[0])
train_clf = np.concatenate((random_X, random_clf_y.reshape(random_dim[0], 1)), axis=1)
col_list = [str(i +1) for i in range(random_dim[1])]
col_list.append('target')
train_clf = pd.DataFrame(train_clf, columns=col_list)
train_clf['target'] = train_clf['target'].astype('str')
train_clf
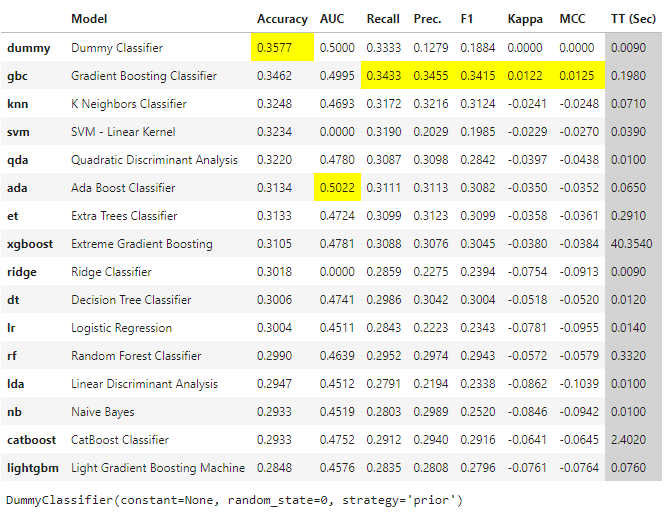
Then we compare machine learning models by using the pycaret compare_models function. According to the results, the best model is Dummy Classifier because there is no relationship between features and target.
from pycaret.classification import *
clf = setup(data=train_clf,
target='target',
numeric_features=col_list[:-1],
silent=True)
compare_models(sort='Accuracy')
Machine Learning Baseline Models
If data is predictable, the second step is to create an ml baseline model. This baseline model shows us which feature is important for prediction and which is not. Generally, ml baseline models use with feature engineering.
1. Baseline Scores
The first step is score calculations of the baseline ml model.
from pycaret.classification import *
CAT_FEATURES = ['Sex', 'Embarked']
NUM_FEATURES = ['Pclass', 'Age', 'SibSp', 'Parch', 'Fare']
IGN_FEATURES = ['PassengerId', 'Name', 'Ticket', 'Cabin']
clf = setup(data=titanic_train,
target='Survived',
categorical_features = CAT_FEATURES,
numeric_features = NUM_FEATURES,
ignore_features = IGN_FEATURES)
baseline_model = create_model('rf')
baseline_preds = predict_model(baseline_model, raw_score=True)
baseline_preds

2. Feature Engineering
In this part, we add new features to the dataset.
import re
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
# Name
titanic_train_FeaEng = titanic_train.copy()
name_last = titanic_train_FeaEng['Name'].str.split(' ', n=1, expand=True)[1]
title = name_last.str.split(' ', n=1, expand=True)[0]
titanic_train_FeaEng['Title'] = title
name_len = titanic_train_FeaEng['Name'].str.len()
titanic_train_FeaEng['Name_len'] = name_len
# Cabin
cabin_first = []
cabin_last = []
cabin_len = []
for cabin in titanic_train_FeaEng['Cabin']:
try:
re_list = re.split('(\d+)',cabin)
if len(re_list) > 1:
cabin_first.append(re_list[0])
cabin_last.append(int(re_list[-2]))
cabin_len.append(len(re_list))
else:
cabin_first.append('None')
cabin_last.append(0)
cabin_len.append(0)
except:
cabin_first.append('None')
cabin_last.append(0)
cabin_len.append(0)
titanic_train_FeaEng['Cabin_First'] = cabin_first
titanic_train_FeaEng['Cabin_Last'] = cabin_last
titanic_train_FeaEng['Cabin_Len'] = cabin_len
...
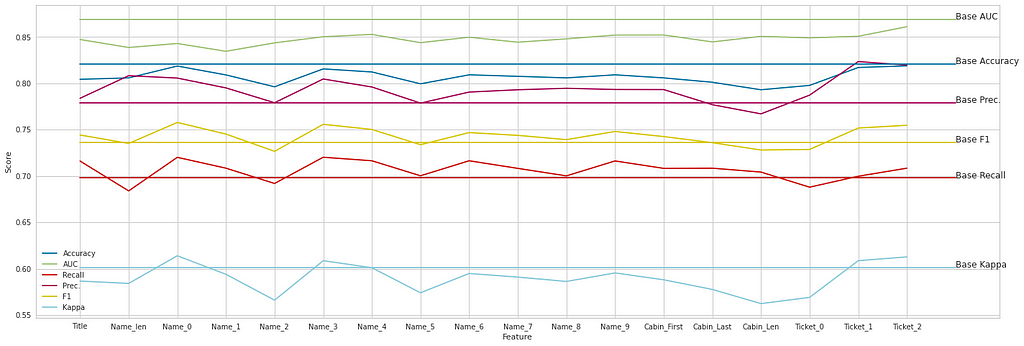
3. Features Importance
After feature engineering, we will add new features to the dataset one by one and we look at the score of baseline machine learning. If we have a better score, it means the new feature is good for predictions.
feature_score_dict = {}
for index, feature in enumerate(new_features):
old_features_temp = old_features.copy()
old_features_temp.append(feature)
titanic_train_FeaEng_temp = titanic_train_FeaEng[
old_features_temp].copy()
clf = setup(data=titanic_train_FeaEng_temp,
target='Survived')
baseline_model = create_model('rf')
scores = pull()
feature_score_dict[feature] = scores
4. Score Data Preparations
In this part, we prepare the dataset that includes scores for visualization.
metric_list = []
feature_list = []
score_list = []
for key in feature_score_dict.keys():
metric_list.extend(list(feature_score_dict[key].columns))
score_list.extend(list(feature_score_dict[key].loc['Mean', :]))
feature_list.extend([key for i in range(len(feature_score_dict[key].columns))])
all_scores_pd = pd.DataFrame()
all_scores_pd['Metric'] = metric_list
all_scores_pd['Feature'] = feature_list
all_scores_pd['Score'] = score_list
5. Visualization
import matplotlib.pyplot as plt
import seaborn as sns
col_list = ['Accuracy', 'AUC', 'Recall', 'Prec.', 'F1', 'Kappa']
score_color = {'Accuracy':'C0', 'AUC':'C1', 'Recall':'C2', 'Prec.':'C3', 'F1':'C4', 'Kappa':'C5'}
...
Automated Machine Learning Baseline Models
The final baseline model is the automated ml baseline model. It is a very good model for benchmarking your ml model. If your ml model is better than the automated baseline model, it is a very strong sign that the model can become a product.
1. LightAutoML
Firstly we install and import the lightautoml library.
%%capture
!pip install -U lightautoml
# Imports from our package
from lightautoml.automl.presets.tabular_presets import TabularAutoML, TabularUtilizedAutoML
from lightautoml.dataset.roles import DatetimeRole
from lightautoml.tasks import Task
import torch
After that, we prepare the task, role, and metric for the lightautoml library.
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
N_THREADS = 4 # threads cnt for lgbm and linear models
N_FOLDS = 5 # folds cnt for AutoML
RANDOM_STATE = 42 # fixed random state for various reasons
TEST_SIZE = 0.2 # Test size for metric check
TIMEOUT = 300 # Time in seconds for automl run
np.random.seed(RANDOM_STATE)
torch.set_num_threads(N_THREADS)
def acc_score(y_true, y_pred, **kwargs):
return accuracy_score(y_true, (y_pred > 0.5).astype(int), **kwargs)
def f1_metric(y_true, y_pred, **kwargs):
return f1_score(y_true, (y_pred > 0.5).astype(int), **kwargs)
task = Task('binary', metric = acc_score)
roles = {
'target': 'Survived',
'drop': ['Passengerid', 'Name', 'Ticket'],
}
Now, we can calculate the cross-validation score by using the below code.
%%time
from sklearn.model_selection import StratifiedKFold
n_fold = 3
skf = StratifiedKFold(n_splits=n_fold)
skf.get_n_splits(titanic_train)
...
print('lightautoml_acc_score: ', lightautoml_acc_score)
lightautoml_acc_score: 0.7957351290684626
2. H2O AutoML
Firstly we import the h2o library.
import h2o
from h2o.automl import H2OAutoML
h2o.init()
Now, we can calculate the cross-validation score by using the below code.
%%time
acc_list = []
for train_index, test_index in skf.split(titanic_train, titanic_train['Survived']):
X_train, X_test = titanic_train.loc[train_index, :], titanic_train.loc[test_index, :]
y = X_test['Survived'].astype(int)
X_test.drop(['Survived'], axis=1, inplace=True)
...
print('h2o_tautoml_acc_score: ', h2o_tautoml_acc_score)
h2o_tautoml_acc_score: 0.8271604938271605
3. Visualization
After calculation of score of the auto ml models. Now, you can see scores that you should pass for strong ml production below.
fig, ax = plt.subplots(figsize=(24, 8))
ax.plot([0, 10], [h2o_tautoml_acc_score, h2o_tautoml_acc_score], color='r')
ax.text(10, h2o_tautoml_acc_score, 'Base_H2O')
ax.plot([0, 10], [lightautoml_acc_score, lightautoml_acc_score], color='r')
ax.text(10, lightautoml_acc_score, 'Base_LightAutoMl');
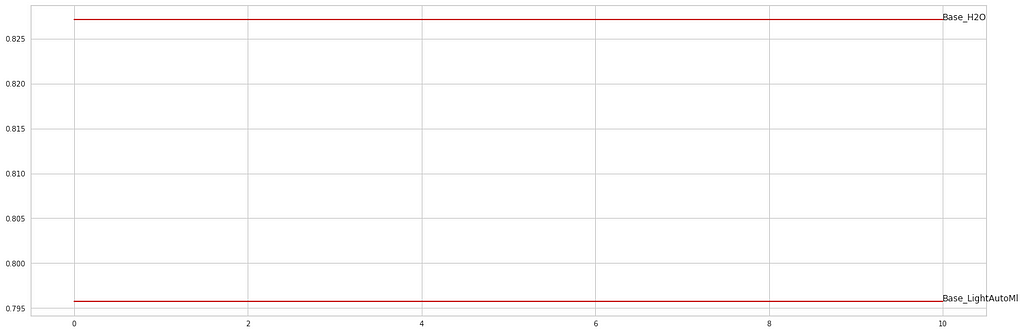
In this part of the article, we talked about baseline model types in classification problems. In the second part of the article, we will talk about baseline models in regression problems.
You can see full python code and all plots from here 👉 Kaggle Notebook.
👋 Thanks for reading. If you enjoy my work, don’t forget to like it, follow me on Medium and LinkedIn. It will motivate me in offering more content to the Medium community! 😊
References:
[1]: https://www.kaggle.com/hasanbasriakcay/baseline-models-clf-random-ml-automl
[2]: https://www.kaggle.com/c/titanic/data
[3]: https://pycaret.gitbook.io/docs/
[4]: https://lightautoml.readthedocs.io/en/latest/index.html
[5]: https://docs.h2o.ai/h2o/latest-stable/h2o-docs/automl.html
More…
- Welcome, 2022🎉. What Has Changed in Data Science in 2021?
- What Are The Differences Between Data Scientists That Earn 500💲 And 225.000💲 Yearly?
- 5 Important Python Libraries and Methods For Data Scientists!
- Olympic Medal Numbers Predictions with Time Series, Part 2: Data Analysis
What Are Baseline Models and Benchmarking For Machine Learning, Why We Need Them? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


