



Using NLP in Disaster Response
Last Updated on July 25, 2023 by Editorial Team
Author(s): Abhishek Jana
Originally published on Towards AI.
In this project, we’ll apply the ETL, NLP, and ML pipeline to analyze disaster data from Figure Eight to build a model for an API that classifies disaster messages.
This is one of the most critical problems in data science and machine learning. During a disaster, we get millions and millions of messages either directly or via social media. We’ll probably see 1 in 1000 relevant messages. A few critical words like water, blocked roads, and medical supplies are used during a disaster response. We have a categorical dataset with which we can train an ML model to see if we identify which messages are relevant to disaster response.
Main Web Interface
In this project, three main features of a data science project have been utilized:
- Data Engineering — In this section, I worked on how to Extract, Transform and Load the data. After that, I prepared the data for model training. For preparation, I cleaned the data by removing bad data (ETL pipeline), then used NLTK to tokenize and lemmatize the data (NLP Pipeline). Finally used, custom features like StartingVerbExtractor, and StartingNounExtractor to add new to the main dataset.
- Model Training — I used XGBoost Classifier to create the ML pipeline for model training.
- Model Deployment — For model deployment, I used the flask API.
This project is done on an anaconda platform using jupyter notebook jupyter notebook. Detailed instructions on how to install an anaconda can be found here. To create a virtual environment, see here
in the virtual environment, clone the repository :
git clone https://github.com/abhishek-jana/Disaster-Response-Pipelines.git
Python Packages used for this project are:
Numpy
Pandas
Scikit-learn
NLTK
re
sqlalchemy
pickle
Flask
Plotly
- Run the following commands in the project’s root directory to set up your database and model.
- To run an ETL pipeline that cleans data and stores it in the database
python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db - To run an ML pipeline that trains classifiers and saves
python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl
2. Run the following command in the app’s directory to run your web app. python run.py
The project is structured as follows:
the data folder contains the data “disaster_categories.csv”, and “disaster_messages.csv” to extract the messages and categories. “DisasterResponse.db” is a cleaned version of the dataset saved in the SQLite database. “ETL Pipeline Preparation.ipynb” is the jupyter notebook explaining the data preparation method. “process_data.py” is the python script of the notebook.
“ML Pipeline Preparation.ipynb” is the jupyter notebook explaining the model training method. The relevant python file “train_classifier.py” can be found in the “models” folder. The final trained model is saved as “classifier.pkl” in the “models” folder.
The app folder contains the “run.py” script to render the visualization and results on the web. templates folder contains the .html files for the web interface.
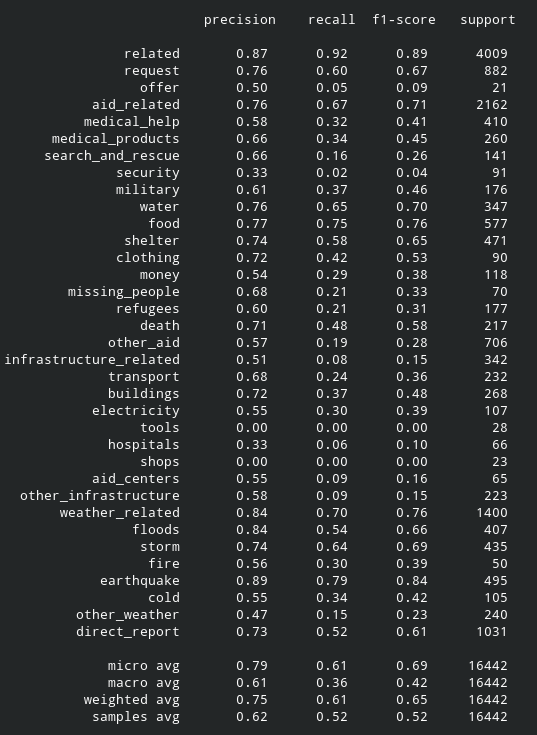
The accuracy, precision, and recall are:
accuracy
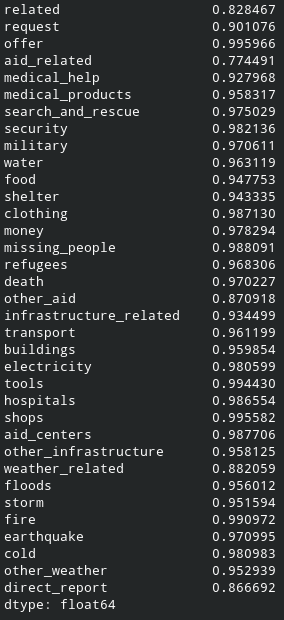
precision and recall
Some of the predictions on messages are given as well:
message 1
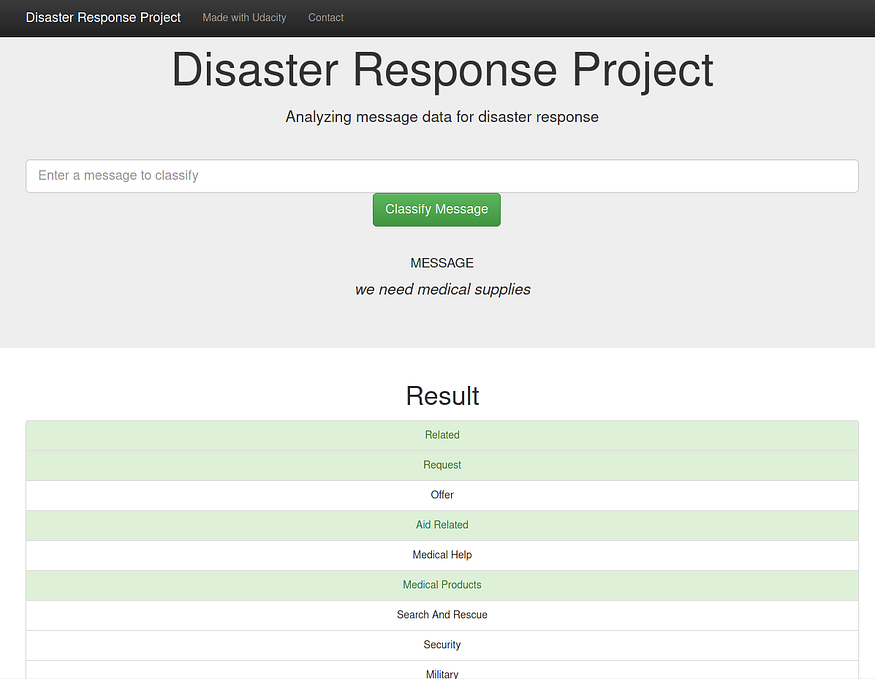
message 2

message 3
In the future, I am planning to work on the following areas of the project:
- Testing different estimators and adding new features in the data to improve the model accuracy.
- Add more visualizations to understand the data.
- Improve the web interface.
- Based on the categories that the ML algorithm classifies text into, advise some organizations to connect to.
5. This dataset is imbalanced (i.e., some labels like water have few examples). In the README, discuss how this imbalance affects training the model and your thoughts about emphasizing precision or recall for the various categories.
The GitHub link of the project can be found here.
Acknowledgment
I am thankful to the Udacity Data Science Nanodegree program and figure eight for motivating me in this project.
I am also thankful to figure eight for making the data publicly available.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

