


Tuning Word2Vec with Bayesian Optimization: Applied to Music Recommendations
Author(s): Jimmy Jarjoura
Originally published on Towards AI.
Hyperparameter Tuning
How we improved our recommendation system at Anghami
Providing personalized and engaging recommendation experiences remains a critical challenge in the ever-evolving landscape of recommender systems. While numerous techniques have been explored, methods harnessing natural language processing (NLP) have demonstrated strong performance. Word2Vec, a widely-adopted NLP algorithm has proven to be an efficient and valuable tool that is now applied across multiple domains, including recommendation systems.
However, the effectiveness of Word2Vec hinges on the careful tuning of its hyperparameters, a process that can be time-consuming and computationally expensive when relying on traditional methods. This is where Bayesian optimization comes into play, offering a sophisticated and efficient approach to navigating high-dimensional search spaces and identifying optimal hyperparameter configurations.
In this article, we embark on a comprehensive exploration of leveraging Bayesian optimization for tuning Word2Vec in the context of music recommendation systems, and the performance improvements we achieved from our offline and online experiments.
Understanding Word2Vec
Word2Vec is a pioneering natural language processing (NLP) technique that revolutionized the way we represent words in vector space. Developed by researchers at Google in 2013 [1], Word2Vec leverages neural networks to learn dense vector representations of words, capturing their semantic and contextual relationships.
At its core, Word2Vec is based on the distributional hypothesis, which states that words occurring in similar contexts tend to have similar meanings. This principle is implemented through two distinct model architectures: the Continuous Bag-of-Words (CBOW) model and the Skip-Gram model.
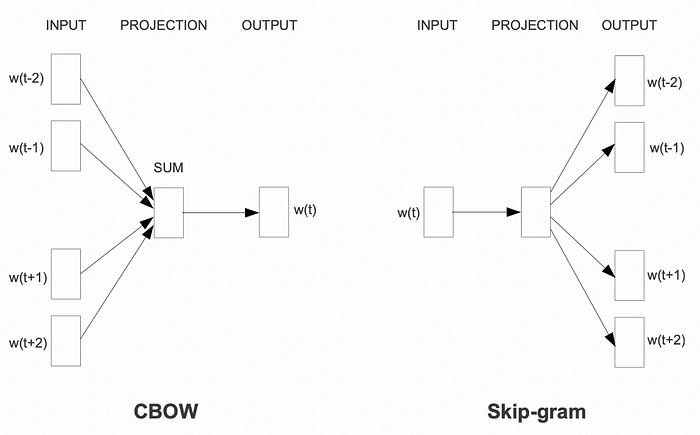
- Continuous Bag-of-Words (CBOW) Model: The CBOW model aims to predict a target word given its surrounding context words.
- Skip-Gram Model: The Skip-Gram model operates in the opposite direction, attempting to predict the surrounding context words given a target word.
Both models are trained on large corpora of text data, adjusting the word vector representations to maximize the likelihood of correctly predicting the target words or context words.
Applying Word2Vec to Music Recommendation
Word2Vec has also emerged as a powerful technique for building robust music recommendation systems. The core idea is to leverage Word2Vec’s ability to learn dense vector representations that capture semantic relationships from sequential data. In the context of music, individual songs can be treated as “words,” while sequences of songs played together (e.g., playlists, user listening sessions) represent the “sentences” or “phrases.”
The training process involves feeding these sequential song patterns from user data into the Word2Vec model. As the model iterates over the data, it builds vector embeddings for each unique song. Songs that frequently co-occur or appear in similar contexts will have vector representations that are clustered closer together in the high-dimensional embedding space.
Music streaming services like Spotify have successfully applied Word2Vec embeddings trained on user-generated playlists as part of their research[3]. At Anghami, we’ve similarly utilized variants of Word2Vec trained on user listening sessions as part of our music recommendation system [4].
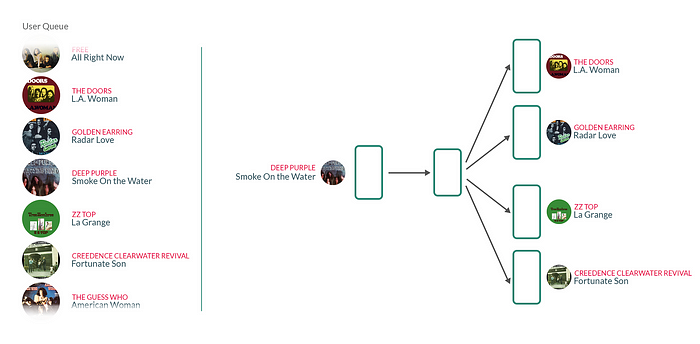
Once trained, these learned song vector embeddings can be utilized in various ways for recommendation scoring and ranking such as: Finding nearest neighbors to a seed song vector, or personalizing recommendations for users. For the latter, a user representation is calculated as recency-based weighted average over their listening behavior. The resulting output is a dense vector that could directly be used as the user embedding to serve recommendations [5].

Tuning Word2Vec: Why Hyperparameters Matter
Many recommendation applications, whether research papers or production systems, often rely on the default hyperparameter settings of the Word2Vec model [6][7]. However, these general defaults may not be optimal for specific data domains and use cases [1]. Numerous studies show that carefully tuning Word2Vec hyperparameters, like the embedding dimension, window size, and number of negative samples, can significantly boost recommendation performance.
At Deezer [8], tuning these hyperparameters substantially improved recommendation quality across datasets compared to using default values. However, they employed inefficient grid search, which becomes computationally prohibitive for large-scale datasets with billions of data points. Traditional techniques like grid search and random search struggle to effectively explore large, high-dimensional hyperparameter spaces in a reasonable timeframe.
To overcome this challenge, the field has increasingly adopted Bayesian optimization — a sophisticated model-based approach for efficiently navigating large search spaces.
Bayesian Optimization: A Smarter Approach
Bayesian optimization is a sophisticated model-based methodology for efficiently navigating high-dimensional hyperparameter spaces. The core idea is to iteratively evaluate configurations suggested by the predictive model, observe their performance, and use these results to update the model’s beliefs. This strategic exploitation of previous information allows Bayesian optimization to automatically balance the exploration of new areas in the parameter space and exploitation of known good regions, converging faster to optimal hyperparameter values while minimizing the total number of expensive evaluations required.
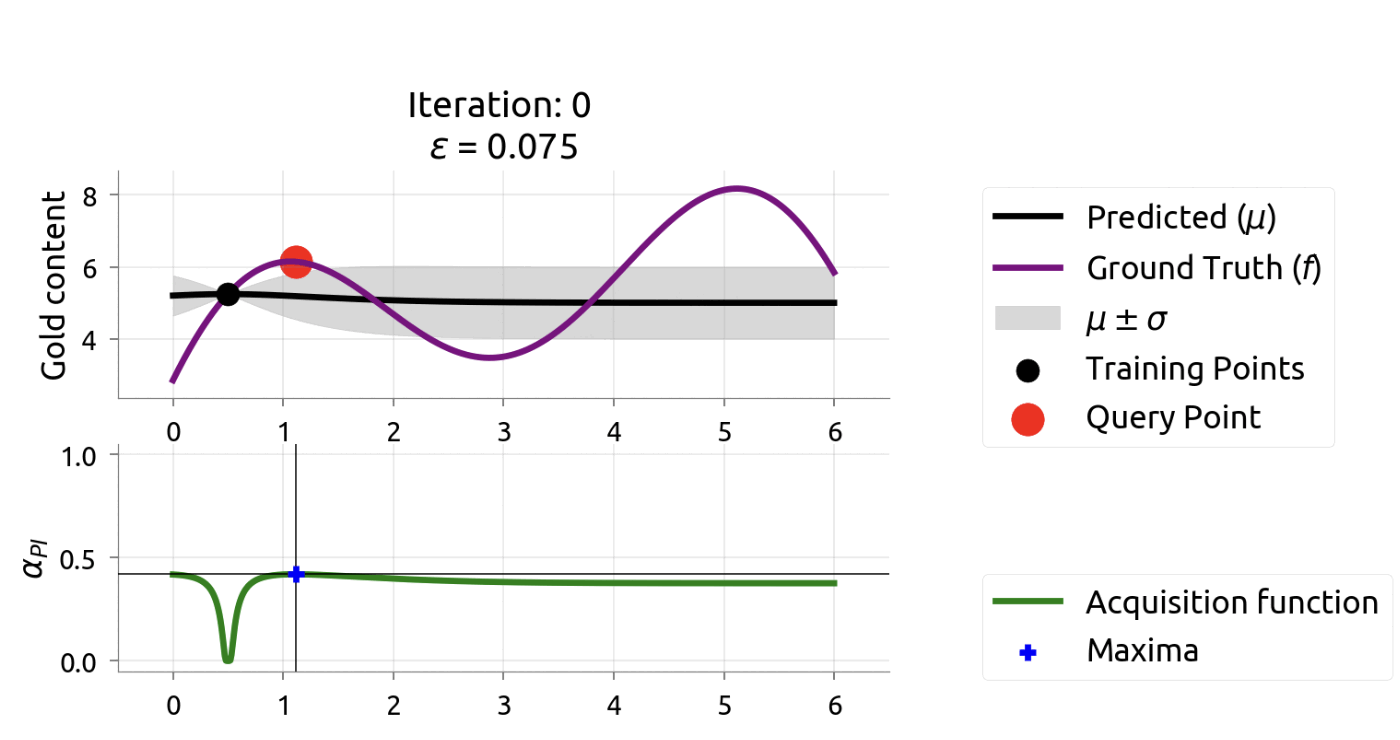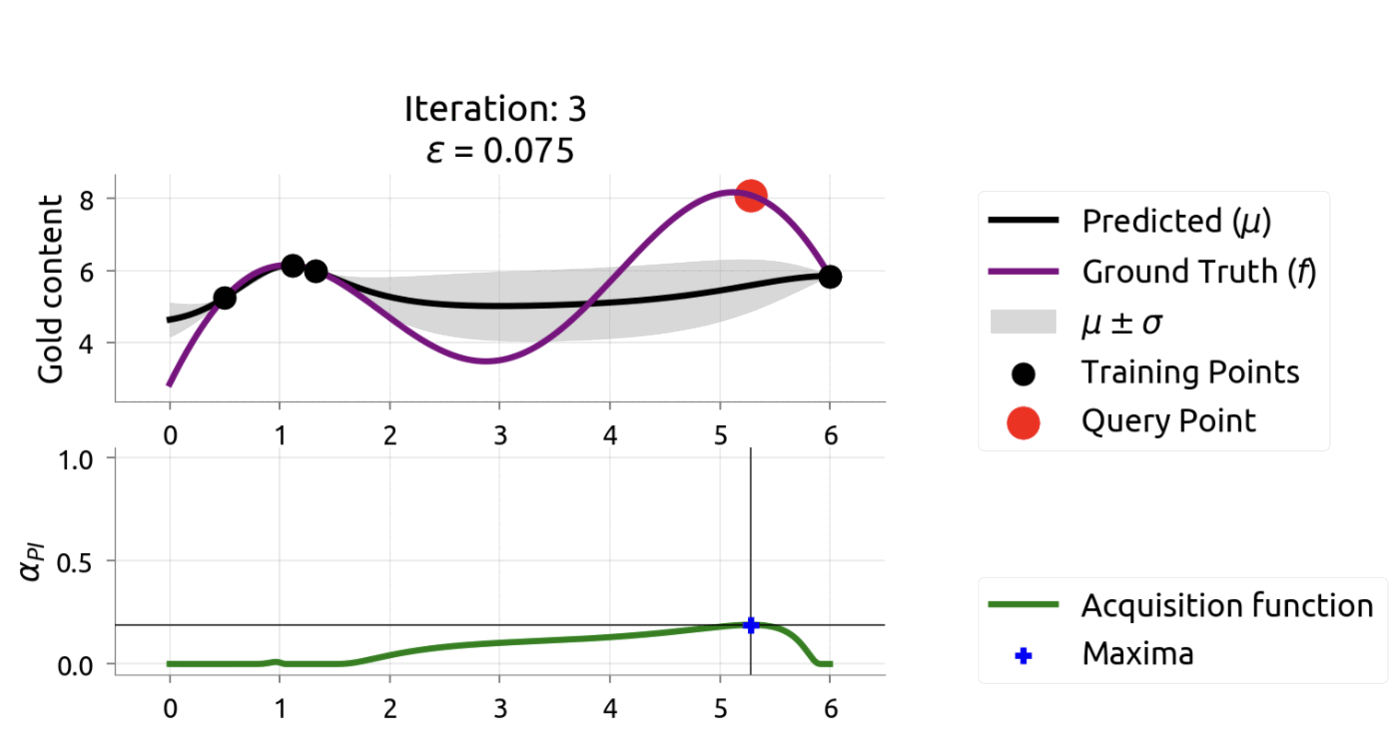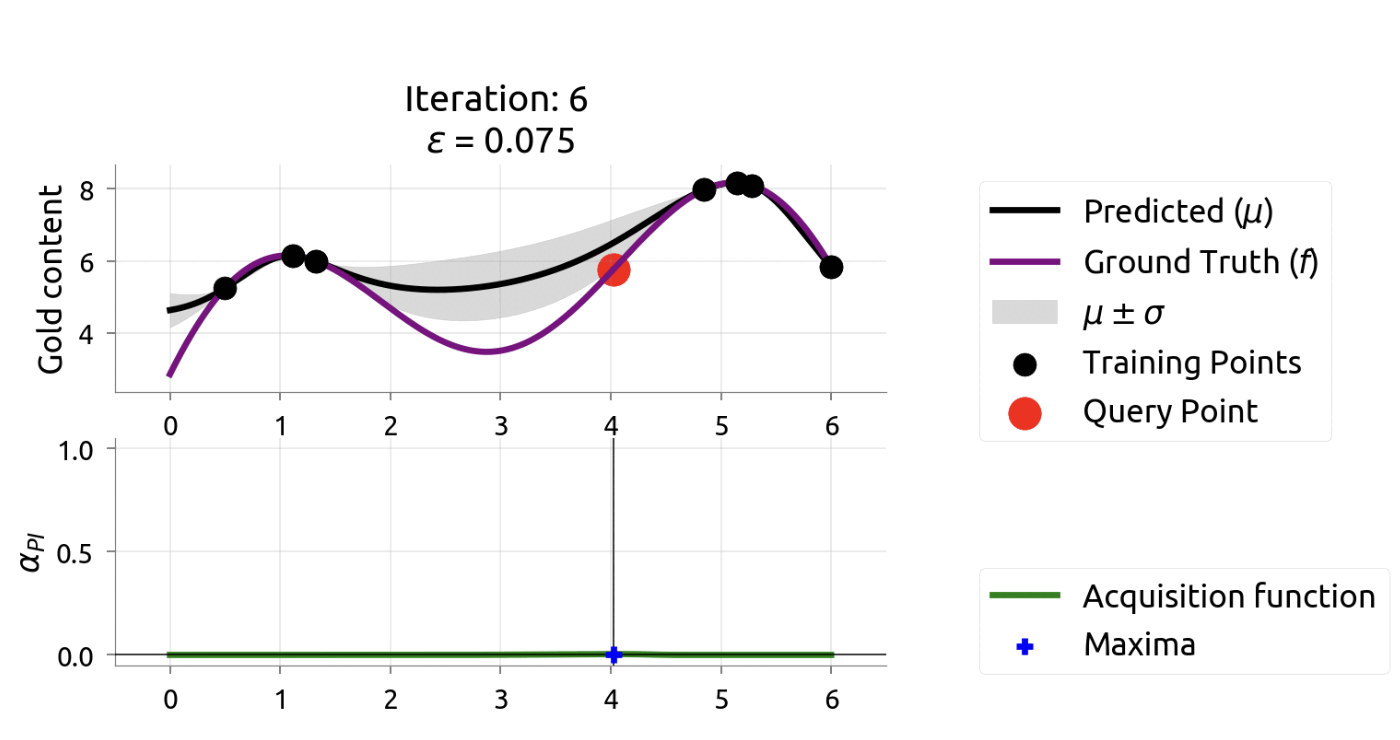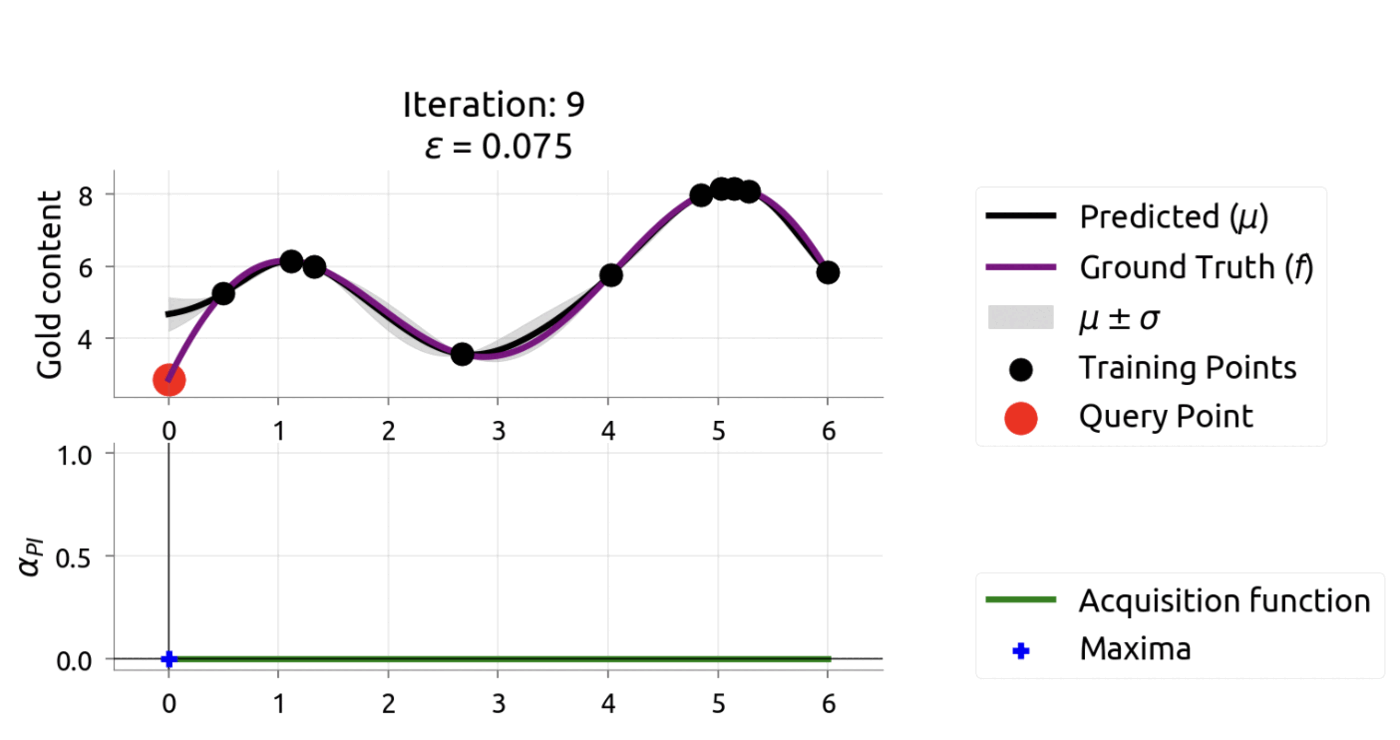
In [9], Twitter researchers used constrained Bayesian optimization for tuning their recommendation system’s hyperparameters. Notably, they found tuning on just 10% of the dataset yielded results that transferred well to online A/B tests, where user follow rates increased by 15%. This ability to work with data samples rather than full datasets provides significant computational advantages and faster iteration cycles.
These characteristics make Bayesian optimization well-suited for tuning complex models like Word2Vec that have many interdependent hyperparameters impacting recommendation performance metrics like hit rate, NDCG and diversity.
For more details about Bayesian Optimization, check references [ 10, 11, 12, 13]
Experimental Setup
To explore the potential of Bayesian optimization for tuning Word2Vec hyperparameters in the context of music recommendation, we conducted a comprehensive experiment on a large-scale dataset from Anghami, a popular music streaming service. The experimental setup consisted of the following components:
Dataset
The dataset consists of approximately 13 billion user listening sessions from over 6.7 million unique users, capturing listens across 25 million unique songs gathered between 2017 and 2023. These sessions capture the sequence of songs users listened to, with filtering applied to ensure coherent listening patterns. To make the hyperparameter tuning computationally tractable, we used a 10% random sample of the full dataset, following the approach in [9] which showed tuning results can transfer well to the complete data.
Methodology
Our methodology follows the work of [8] and [9] on tuning Word2Vec models for recommendation tasks. We formulated the problem as a next-song prediction task, training Word2Vec on the user listening session sequences while holding out the last two songs as a test set, split by timestamp. This test set comprises (query, target) song pairs, where the goal is to predict the target song given the query song’s context.

To evaluate performance, we used the trained Word2Vec model to generate the query song’s embedding and retrieved the top 10 nearest neighbors based on cosine similarity. We then computed the Hit Ratio at 10 (HR@10) and Normalized Discounted Cumulative Gain at 10 (NDCG@10) using the ranked list of recommendations against the target song.
Hyperparameter Tuning
For the Bayesian optimization process, we used the BayesianOptimization library due to its ease of use and flexibility. We tuned the following Word2Vec hyperparameters within the specified ranges:

The number of training epochs was fixed at 3 per iteration to bound the computational cost, unlike [8] which included epochs as a tunable parameter.
We defined an objective function to maximize the average of HR@10 and NDCG@10 on a validation set:
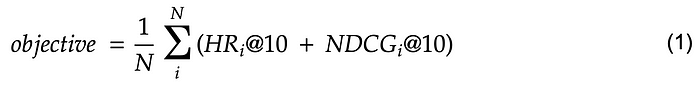
The Bayesian optimization was run for 19 iterations, preceded by 5 random initialization points, with a total budget of 24 hours using AWS SageMaker. We leveraged Facebook’s Faiss library for efficient nearest neighbor search.
The code below shows a general view how Bayesian Optimization can be easily used.
if __name__ == '__main__':
pbounds = {'dim': (10, 200), 'num_neg_samples': (1, 40),
'window_size': (1, 40), 'init_lr': (0.001, 0.1)}
optimizer = BayesianOptimization(
f=bayesian_optimization,
pbounds=pbounds,
random_state=1,
)
# Number of iteration is calculated based on the following:
# 1 hour per iteration: 5 iterations of random search + 19 iterations = 24 iterations = 24 hours running time
acq = "ei", # Excpected Improvement Aquisition Function
optimizer.maximize(
n_iter=19,
)
for iteration, results in enumerate(optimizer.res):
print(f"Iteration {iteration}: Result = {results}")
The bayesian_optimization function that we are trying to maximize is:
def bayesian_optimization(
path: str, init_lr: float, num_neg_samples: int, window_size:
int, dim: int, num_epochs: int
) -> dict:
"""
Function to optimize the hyperparameters of the model.
@param path: path to the data
@param init_lr: initial learning rate
@param num_neg_samples: number of negative samples
@param window_size: window size
@param dim: dimension of the features
@param num_epochs: number of epochs
@return: metrics to optimize
"""
# Train the model
model_name, songs_vectors_df = train(
path, epochs=num_epochs, lr=init_lr, neg=num_neg_samples,
ws=window_size, dim=dim, periods=periods
)
# Nearest neighbors
nearest_neighboors_df = get_nearest_neighboors(songs_vectors_df, dim)
# Compute Metrics
metrics = compute_metrics(nearest_neighboors_df)
# Return metrics to optimize
return metrics
Results
The Bayesian optimization tuning process identified a new set of hyperparameters that substantially improved recommendation performance compared to the baseline configuration. The table below summarizes the baseline and tuned hyperparameter values:

Offline Metrics
Using the hyperparameters tuned via Bayesian optimization, we evaluated the resulting Word2Vec model and observed the following:

- Compared to the current production model trained on the full dataset, the tuned model achieved an 8.06% increase in HR@10 and a 10.05% increase in NDCG@10 on the held-out test set.
- We also compared against a baseline Word2Vec model with default hyperparameters, trained only on the 10% dataset sample. On this sample’s test set, the tuned model showed a 3.95% improvement in HR@10 and 4.55% improvement in NDCG@10.
- Additionally, we tested the generalization performance by evaluating the 10% sample models against the full 100% dataset test set. Here, the tuned model outperformed the default model by 6.23% in HR@10 and 7.04% in NDCG@10.
These results demonstrate the effectiveness of applying Bayesian optimization to navigate Word2Vec’s high-dimensional hyperparameter space and identify configurations tailored to the characteristics of our music recommendation data and objectives.
Online A/B Testing
To validate the tuned Word2Vec model’s performance in a real-world setting, we conducted an online A/B test by deploying the model with the optimized hyperparameters for 1 week.
Initial top-line metrics did not show consistent improvements compared to the production model. However, deeper analysis revealed interesting insights when segmenting by content language.
Our music catalog comprises both Arabic and International/English songs, catering to a diverse user base that consumes content in both languages. Upon examining per-language user session metrics, we noticed measurable gains for Arabic content sessions:
- For user sessions consisting primarily of Arabic songs, we observed a 2.45% to 4.04% increase in average seconds streamed compared to the production model.
However, the improvements did not translate as strongly to International/English sessions, potentially due to a few factors:
- Since most user activity in our dataset involves Arabic content, the hyperparameter tuning process was biased towards optimizing for Arabic language sessions, which dominates the data.
- User-created Arabic playlists/sessions may exhibit more coherent patterns, enabling the Word2Vec model to extract higher-quality embeddings compared to the more diverse consumption patterns for International music.
These findings suggest that while overall gains were modest in the online experiment, the tuning process successfully enhanced the model’s ability to capture relevant signals for the dominant Arabic music consumption on our platform.
Moving forward, we plan to further investigate these hypotheses and explore additional tuning strategies, such as conducting separate tuning runs for Arabic and International subsets to better cater to the unique characteristics of each domain.
Conclusion
In this work, we demonstrated the effectiveness of Bayesian optimization for tuning Word2Vec hyperparameters in the context of a large-scale music recommendation system. Comprehensive evaluations showed significant performance gains in recommendation quality metrics compared to baseline configurations. Online A/B tests further validated the benefits, especially for the dominant Arabic music segment. Moving forward, we plan to explore segment-specific tuning strategies to cater to the unique characteristics of different content domains
References
[1] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Neural Information Processing Systems. (2013) 3111–3119.
[2] Mikolov, T., Chen, K., Corrado, G. and Dean, J., 2013. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
[3] Anderson, A., Maystre, L., Anderson, I., Mehrotra, R. and Lalmas, M., 2020, April. Algorithmic effects on the diversity of consumption on spotify. In Proceedings of the Web Conference 2020 (pp. 2155–2165).
[4] Medium U+007C Using Word2vec for Music Recommendations by Ramzi Karam
[5] Medium U+007C Simple Re-Ranker For Personalized Music Recommendation At Anghami by
[6] Mihajlo Grbovic, Vladan Radosavljevic, Nemanja Djuric, Narayan Bhamidipati, Jaikit Savla, Varun Bhagwan, and Doug Sharp. 2015. E-commerce in Your Inbox : Product Recommendations at Scale Categories and Subject Descriptors. SIGKDD 2015: Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining — KDD ’15 (2015), 1809–1818.
[7] Oren Barkan and Noam Koenigstein. 2016. Item2Vec : Neural Item Embedding for Collaborative Filtering. 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP) (2016)
[8] Caselles-Dupré, H., Lesaint, F. and Royo-Letelier, J., 2018, September. Word2vec applied to recommendation: Hyperparameters matter. In Proceedings of the 12th ACM Conference on Recommender Systems (pp. 352–356).
[9] Chamberlain, B.P., Rossi, E., Shiebler, D., Sedhain, S. and Bronstein, M.M., 2020, September. Tuning word2vec for large scale recommendation systems. In Proceedings of the 14th ACM Conference on Recommender Systems (pp. 732–737).
[10] Medium U+007C A Conceptual Explanation of Bayesian Hyperparameter Optimization for Machine Learning By
[11] Medium U+007C Bayesian Optimization Concept Explained in Layman Terms By
[12] Shahriari, B., Swersky, K., Wang, Z., Adams, R.P. and De Freitas, N., 2015. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 104(1), pp.148–175.
[13] Frazier, P.I., 2018. A tutorial on Bayesian optimization. arXiv preprint arXiv:1807.02811.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

