


Inside Jamba: Mamba, Transformers, and MoEs Together to Power a New Form of LLMs
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 170,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Transformer architectures have been the dominant paradigm in LLMs leading to exceptional advancements in research and development. The question of whether transformers will be the final architecture to reach AGI versus the real possibility of new architecture paradigm has been a passionate topic of debate in the AI community. Recently, researchers from Princeton University and Carnegie Mellon proposed the Mamba architecture based on state space models(SSMs) which has become the most viable alternative to transformers.
Instead of thinking about SSMs vs. transformers, could we try to combine the two? This is the thesis behind a new model called Jamba released by the ambitious team at AI21 Labs. Jamba combines transformers and SSMs in a single architecture that could open new avenues for the future of LLMs.
The Problem
Until this point, the creation of LLMs has largely hinged on the use of traditional Transformer structures, known for their robust capabilities. However, these structures have two significant limitations:
1. They require a lot of memory, especially as the amount of text they process at once increases. This makes it difficult to use them for analyzing large documents or running many tasks at the same time unless you have a lot of computing power.
2. They become slower as the amount of text increases. This is because each piece of text (or “token”) needs to consider all the previous ones, making it inefficient for tasks that involve a lot of data.
Recently, new types of models called state space models (SSMs), exemplified by Mamba, have shown promise for being more training-efficient and better at dealing with long-distance relationships in text, though they still don’t match Transformer models in performance.
Jamba Architecture is Quite Unique
The key innovation of Jamba is its hybrid design, incorporating Transformer and Mamba layers with an MoE component. This unique blend, known as the Jamba block, allows for an adaptable approach in managing the challenges of low memory usage, high processing speed, and maintaining high quality in outputs. Despite the general misconception that bigger models require more memory, the use of MoE means that only a fraction of the model’s parameters are active at any time, significantly reducing memory demands. Furthermore, by substituting some Transformer layers with Mamba layers, Jamba significantly reduces the size of the key-value (KV) cache needed for processing, achieving up to an eight-fold decrease compared to traditional Transformers. A comparison with recent models showcases Jamba’s efficiency in maintaining a smaller KV cache, even when processing up to 256,000 tokens.
The core of Jamba consists of what’s called a Jamba block, a sequence of layers combining both Mamba and attention mechanisms, each followed by a multi-layer perceptron (MLP). Within these blocks, the ratio of attention to Mamba layers can be adjusted to strike the right balance between memory usage and computational speed, especially beneficial for long sequences. Some of the MLPs can be swapped for MoE layers, enhancing the model’s capacity while keeping the computation overhead low. This modular design affords Jamba the flexibility to prioritize between computational efficiency and memory usage by adjusting the mix of its core components.

Jamba Performance is Impressive
Jamba’s initial performance across different benchmarks is quite remarkable as shown in the following figure.
Even more interesting is the fact that this performance improvementn manifest itself across different dimensions.

Efficiency
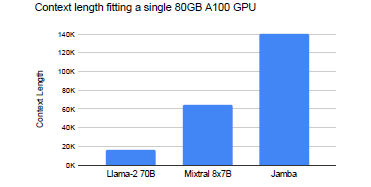
Jamba’s design allows it to operate on a single 80GB GPU, offering a balance between high quality and fast processing. With a setup of four Jamba blocks, it supports double the context length compared to Mixtral and seven times that of Llama-2–70B.
Throughput
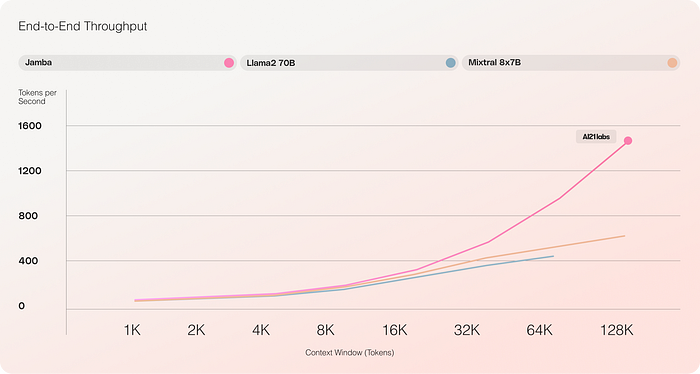
The model’s throughput, or how quickly it can process text, shows a significant advantage in settings utilizing both small and large amounts of text. For instance, when using a single A100 80 GB GPU, Jamba achieves three times the throughput of Mixtral for large batches. Additionally, in scenarios involving longer texts across multiple GPUs, Jamba maintains its superior performance, especially noticeable in handling up to 128,000 tokens.
Cost
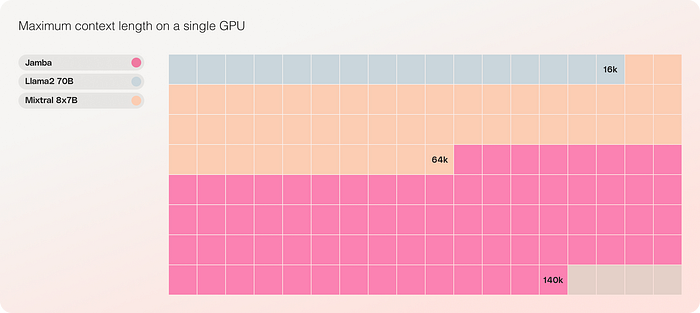
Jamba’s efficiency enables it to process up to 140,000 tokens on a single GPU. This opens up new possibilities for using advanced text processing models without needing extensive hardware, making it more accessible for a broader range of applications.
Just like Mistral recently innovated by combining MoEs and LLMs, Jamba represents a major architectural innovation in the generative AI space. The combination of transformer, SSMs and MoEs can set the standard for new LLMs. Happy to see AI21 pushing the envelope.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

