



Trends in AI — 2023 Round-up
Last Updated on January 25, 2023 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI.
Trends in AI — 2023 Round-up
What’s next for Language Models, Reinforcement Learning, Computer Vision, and leading AI companies like OpenAI and Google?
Prophecies of the third AI winter early in 2022 — or AI hitting a wall — aged fast and poorly with DALL·E 2’s announcement in April 2022, followed by many more text-to-image applications largely driven by Diffusion Models, a very productive area for Computer Vision research and beyond. The year 2022 in AI was defined by a strong upward trend.
Moreover, large Language Models proved to be an even more fertile area with several papers significantly expanding on their capabilities: Retrieval Augmentation, Chain-of-Thought prompting, Mathematical Reasoning, Reasoning Bootstrapping. Language Models research is far from over. It’s on a roll!
The blockbuster of the year was surely OpenAI’s ChatGPT, once again redefining what can be expected from LLMs and strengthening OpenAI’s position as a world leader in LLMs as a service. As we’ll see, this might have ripple effects through 2023 in the whole tech space, as Microsoft — having a strong partnership with OpenAI — will likely use it to revamp their mainstream products, including Bing and Office.
Now let’s take a look at a few key areas in AI: where they are currently and where we expect them to develop in 2023. Let’s dive in!
🗺️ Community
Twitter has long been the biggest online space where AI research people share and discuss their work publicly. But Elon Musk’s infamous acquisition of the company has sent it onto shaky ground. Growing instability, unpredictable policy changes, and Musk’s divisive political stances have produced an outcry to change over to other places such as Mastodon. For now, most of the action still remains on the bluebird site, and a full-on overnight exodus on political grounds remains unlikely, but we can’t completely rule out the possibility of some sort of company meltdown within the next year.
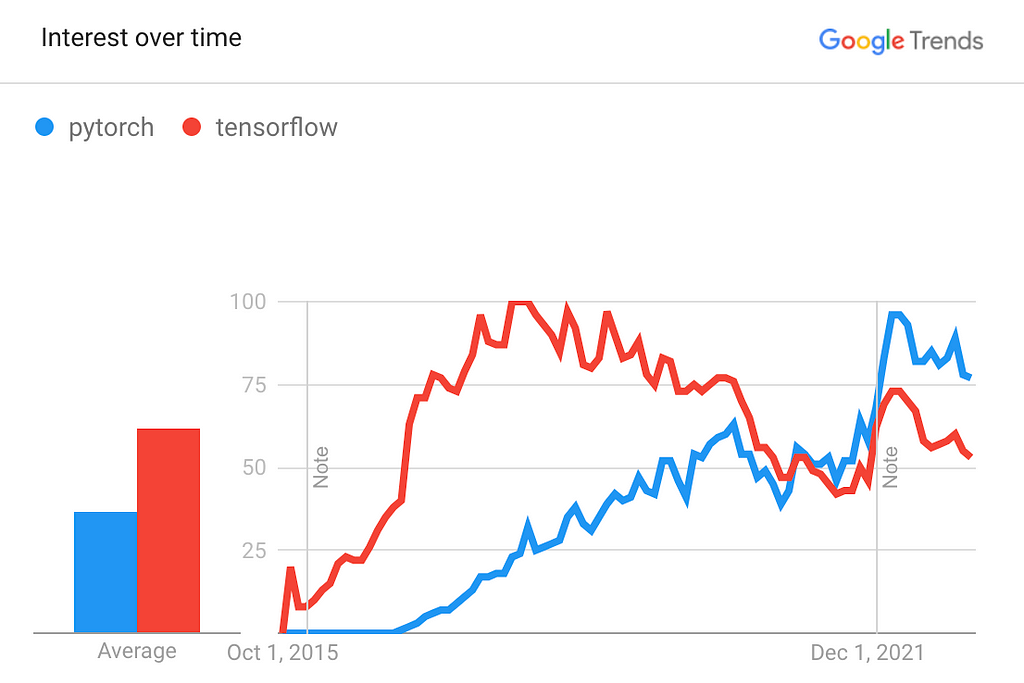
Another battlefront for the Deep Learning community has been that of frameworks. The adoption of PyTorch has been above TensorFlow for a couple of years now and is the most widely loved and used framework for Autograd and Neural Networks. In 2023, PyTorch v2.0 will be released, with a compiler and speedups as the headline feature. Not even Google is betting on a comeback of TensorFlow, and the JAX/FLAX ecosystem — already a favorite in Google Brain and many other researchers — is still not mature enough to go mainstream.
Finally, the industry and academia divide continues to grow as (1) big tech has much more compute resources available and (2) much of the current blockbuster research relies on the close collaboration of dozens of world-class engineers, which are not available to the average PhD student. This means that academic research is shifting towards better examining, understanding, and extending existing models, and devising new benchmarks and theoretical advancements.
Language Models
If LLMs were already the main characters in the AI landscape a year ago, the situation now is even closer to a monologue. Sutton’s bitter lesson continues to age like fine wine. With ChatGPT, LLMs went mainstream — even my non-AI non-tech friends were asking about it — and we expect 2023 to be the year where this tech truly reaches the masses. Microsoft — already considering to expand its stake up to 49% of OpenAI — and Google won’t want to miss out, so it’ll be a clash of titans.
- Scale. Models have barely grown in terms of parameters in the past couple of years — contrary to much of the public AI discourse! The best existing available dense LLMs are still in the 200B parameter range because they were underoptimized and so much could still to be discovered and improved in that regime. However, we expect that to change this year with (1) Google making public use of their FLAN family of models and (2) OpenAI and contenders venturing into the trillion scale parameter count with the much anticipated GPT-4 if all optimization challenges are overcome. These might not power the bulk of LLMs as a Service because of costs but will become the next flagship tech to make the headlines.
- Optimization. The era of training on static text data is over. Current LLMs are not really just Large Language Models, their optimization includes curated, interactive, and continual data/text and formal languages like code. We expect developments in how LLMs are optimized that leverage more complex RL environments (e.g. LLMs as agents), LLMs trained within a formal environments loop to learn better symbol manipulation (e.g. Minerva v2), LLMs to generate more and increasingly better data to train themselves on, and methods to distill more performance on models that run cheaply on modest hardware, cause every FLOP counts in the economics of LLMs as a Service.
- Progress in Language Models will continue to trickle down to other AI fields like Computer Vision, Information Retrieval, and Reinforcement Learning (as has already happened in 2022).
- Code + LLMs. GitHub Copilot has been around for more than a year, and it’s slowly changing the way people write code. Google shared earlier in 2022 that 3% of its code was already written by LLMs, and we expect code completion LLMs to get much better, slowly shifting how people write code.

🤖 Reinforcement Learning and Robotics
Arguably, RL has not advanced substantially from a fundamental perspective in the last year. Instead, progress was constituted by the application of increasingly complex agents that combine Computer Vision, Text, Language Models, Data Curation… such as CICERO, Video PreTraining (VPT), MineDojo, or GATO. Largely driven by success with scaling up Imitation Learning or offline RL, with just a sprinkle of the good-old online RL agent-environment-reward loop. We expect the development of more multimodal complex agents that take actions under incomplete information, leveraging modular components based on large neural networks and large pretraining data.
In 2023 we expect the symbiosis between LLMs and RL to grow even further: training LLMs in an RL setting, and using LLMs as part of RL agents (e.g. as planners for a policy, strong priors).
Finally, Zero-few shot and extreme efficiency will be key for progress in robots that interact in the real world, and we expect the trend in ML modularization (the ability to just plug in pretrained modules), few-shot abilities, and causal representation learning to help in that regard in 2023. But we’d be surprised if there’s a massive breakthrough in the space before extreme sample efficiency is solved in silico for traditional RL.
🕶️ Computer Vision
Diffusion Models and text-to-image were the stars of the show when it comes to 2022 CV. Our perception of what can be achieved by generating images is very different from what we thought a year ago. Yet, image understanding is far from solved. What are the keys that will get us closer?
- Causal Representation Learning (often related to Object-centric representation learning) is a growing field of interest that studies the learning of the causal relationships between elements beyond their statistical correlations. A key blocker for progress has been a lack of strong standardized benchmarking, and we expect 2023 to bring a shift in the benchmarking culture of CV, shifting focus to Out of Domain Generalization, Robustness, and efficiency, and away from in-domain image classification, tracking, segmentation…
- More multimodal models combining text, audio, and actions with vision like we’ve seen with Video Pretraining Transformer MineDojo.
- Diffusion Models have taken over generative text-to-image AI, and are being used for other applications such as molecule docking and drug design. Generative video and 3D scenes are and will be the next natural step for these applications, but we expect coherent long video generation to take longer. Modeling high-frequency data (tokens/images) is harder than gathering large-scale low-frequency data (e.g. novel-scale narrative structure). There’s not enough static data to solve this problem by brute force, thus the need for better optimization techniques for large models.
🔎 Information Retrieval
Finally, the topic close to our hearts. The biggest problem of Neural IR in the past couple of years has been to translate the success in academic benchmarks — where BM25 is routinely beaten — into real-world settings and widespread adoption. The keys for this to happen:
- No need human relevance annotations. This has already been one of the aspects where IR advanced the most in 2022, with proposals such as InPars (using LMs to generate annotations), LaPraDor (Unsupervised Contrastive Learning), and others.
- Convenience. Current models might perform well on benchmarks, but they don’t just work. We expect advancements in convenience in the whole development lifecycle of neural IR models that will increase adoption.
- Conversational AI. Retrieval Augmented Language Models and powerful models like ChatGPT have recently revived interest in the space, as many now see real feasibility. While standardized evaluation remains challenging, we expect the interest in the space to grow.
Besides research, 2023 could be a year of disruption in the space of consumer web search, and just a paradigm shift of what people come to expect from search engines. Microsoft’s collaboration with OpenAI and the recent stellar success of ChatGPT has many speculating about the possibility of a 180° turn for Bing with the adoption of true complex web-scale question answering powered by language models that just work. Google now sees its main business challenged and this might be the year of disruption where Google needs to step up its game.
To close off, we’d like to highlight some closing topics less related to research that are still key to how AI will evolve in the next 12 months:
- On the hardware front, Nvidia’s monopoly on chips for AI remains untouched and only a miracle could change that in the short term. Rumors of a HuggingFace acquisition by Google and tight integration with their GCP and TPUs for hosting could increase the usage of TPU hardware, but that still sounds like a long shot.
- The European AI Act — the most ambitious and comprehensive regulatory effort yet to be seen — continues to progress and current estimates indicate that it could come into force as soon as late 2023. We hope other big economies will take note and follow the lead as it happened with GDPR, to ensure individual rights are preserved when it comes to AI usage.
- How the current big tech slowdown will impact AI research — especially in short-term industry funding. While we hope the strong progress we’ve seen in the past 12 months will translate into overall optimism in the space, a slowdown can’t be ruled out.
What about you? What do you think will be the biggest advancements and surprises in the AI world in 2023? Follow us on Twitter @zetavector or let us know in the comments. Til the next one!
Trends in AI — 2023 Round-up was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

