



An Introduction to CNNs: Understanding the Basics
Last Updated on January 25, 2023 by Editorial Team
Author(s): Pranay Rishith
Originally published on Towards AI.
Exploring how powerful CNN is: from basics
Introduction
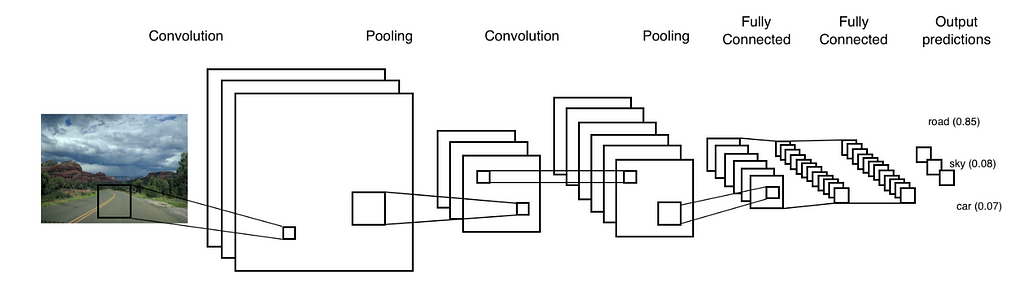
- Convolutional neural networks are a deep learning concept that was specifically built for processing images. Machine learning is a concept where a computer learns from past experiences. Deep Learning is an advanced part of machine learning. CNN is designed to find visual patterns.
- When we humans see images, we see objects, colors, etc. We learn these things as we grow up, but computers can only understand 0’s and 1’s, i.e., binary values. Then how will computers see images?
- Every image is made up of pixels. The below image is a good depiction of how a computer reads images. There are two types of images, Grayscale and Color. Grayscale(black and white) is made up of an array of values that range from 0 to 255(black to white). Color images have 3 arrays, red array, green array, and blue array(RGB). Also each of those arrays ranging from 0 to 255(black to corresponding colors).

If a grayscale image has a size of 1080×1080 then the total number of values is 1080x1080x1 whereas a color image has 1080x1080x3(3 as in R+G+B).
Architecture
A convolutional neural network has 3 types of layers: convolution layer, pooling layers, and fully connected layers.
Convolutional Layers
The convolutional Layer is the layer where important features are extracted from input images. This layer uses a small square to extract features from the input image. This small square is called a kernel or filter. To explain, There is a mathematical operation in this layer between the input image and a filter in order to preserve and extract features. This is called Feature extraction in CNN.
Size of feature map: n-f+1
n = size of input
f = size of filter
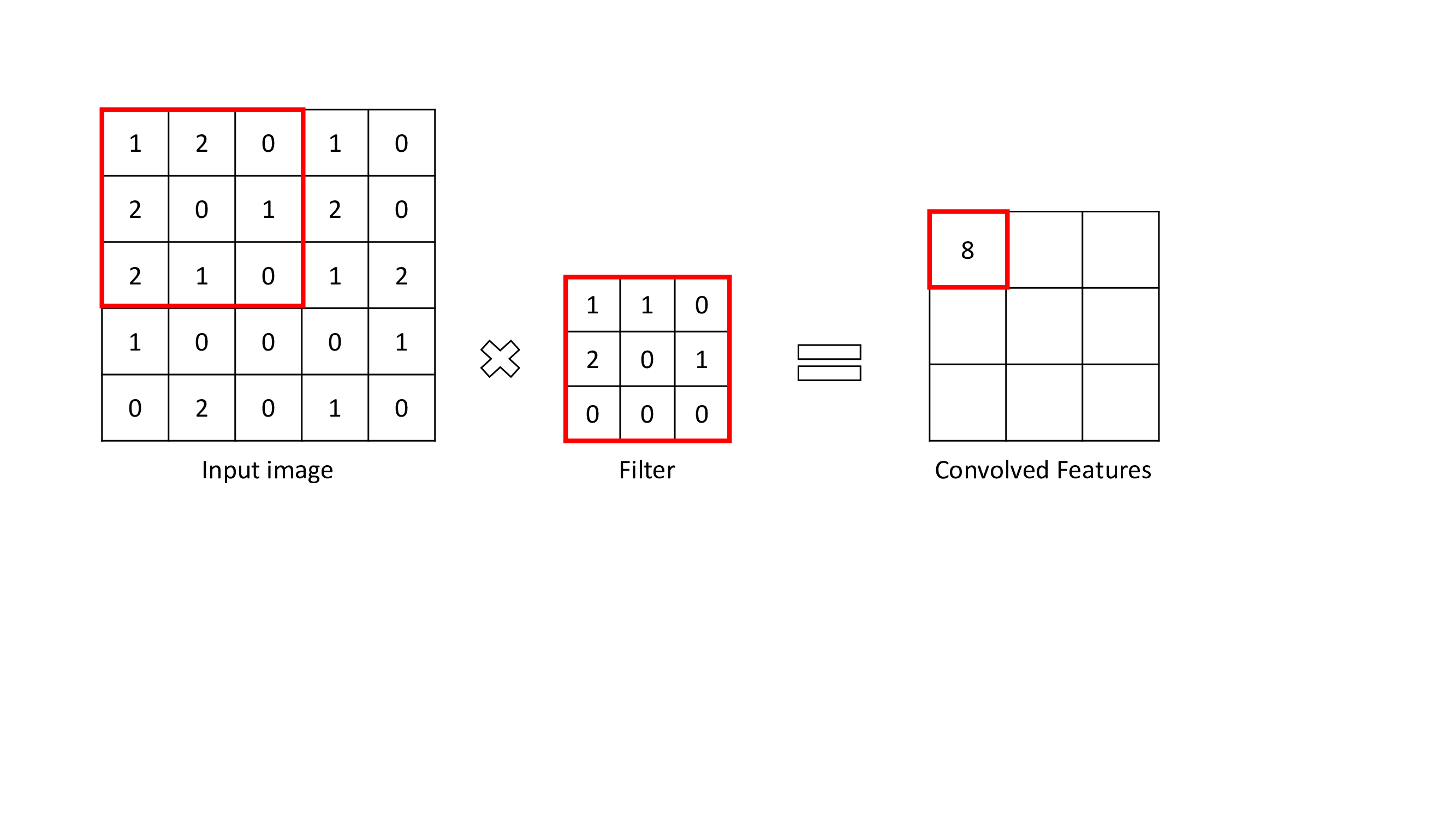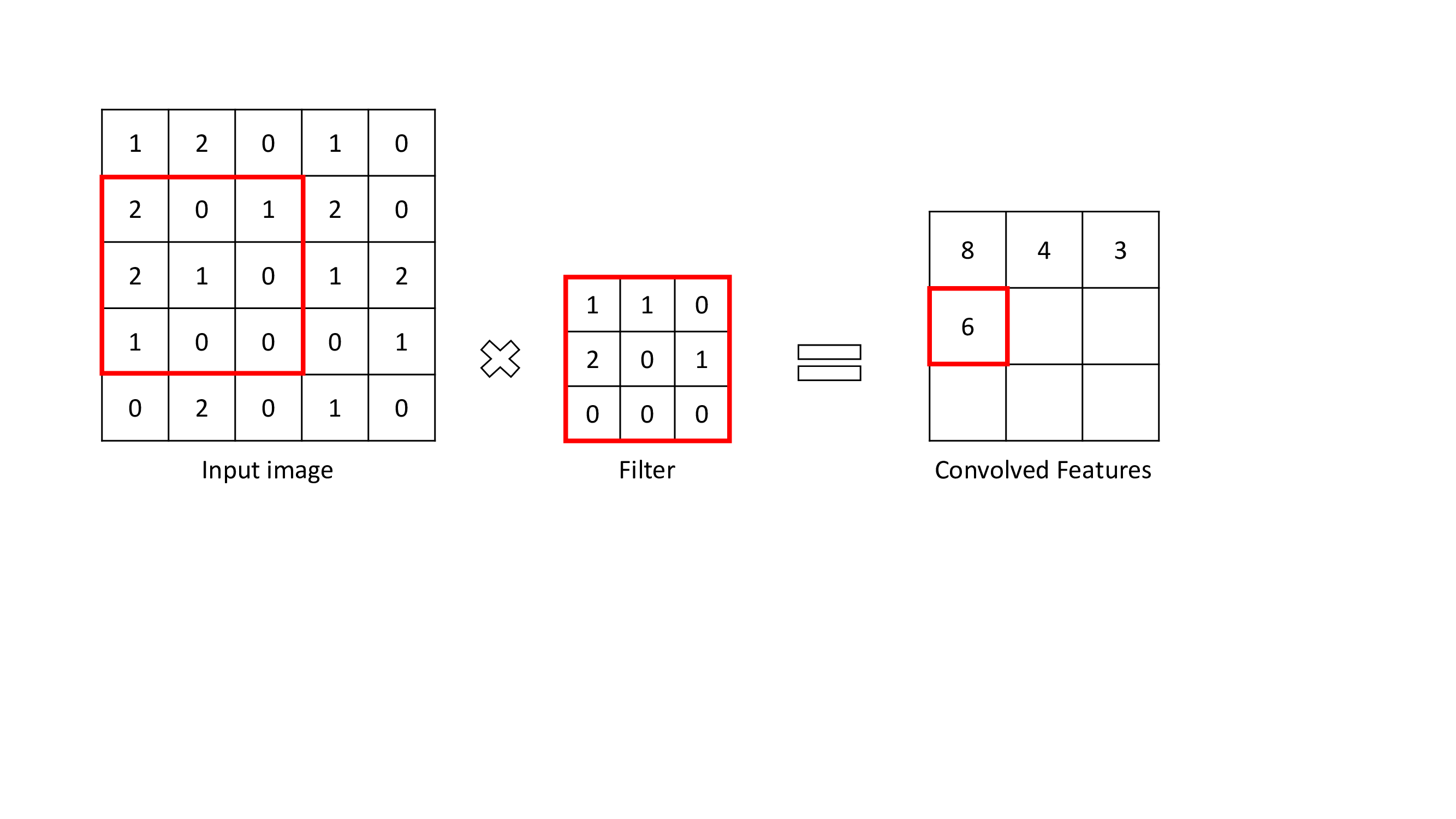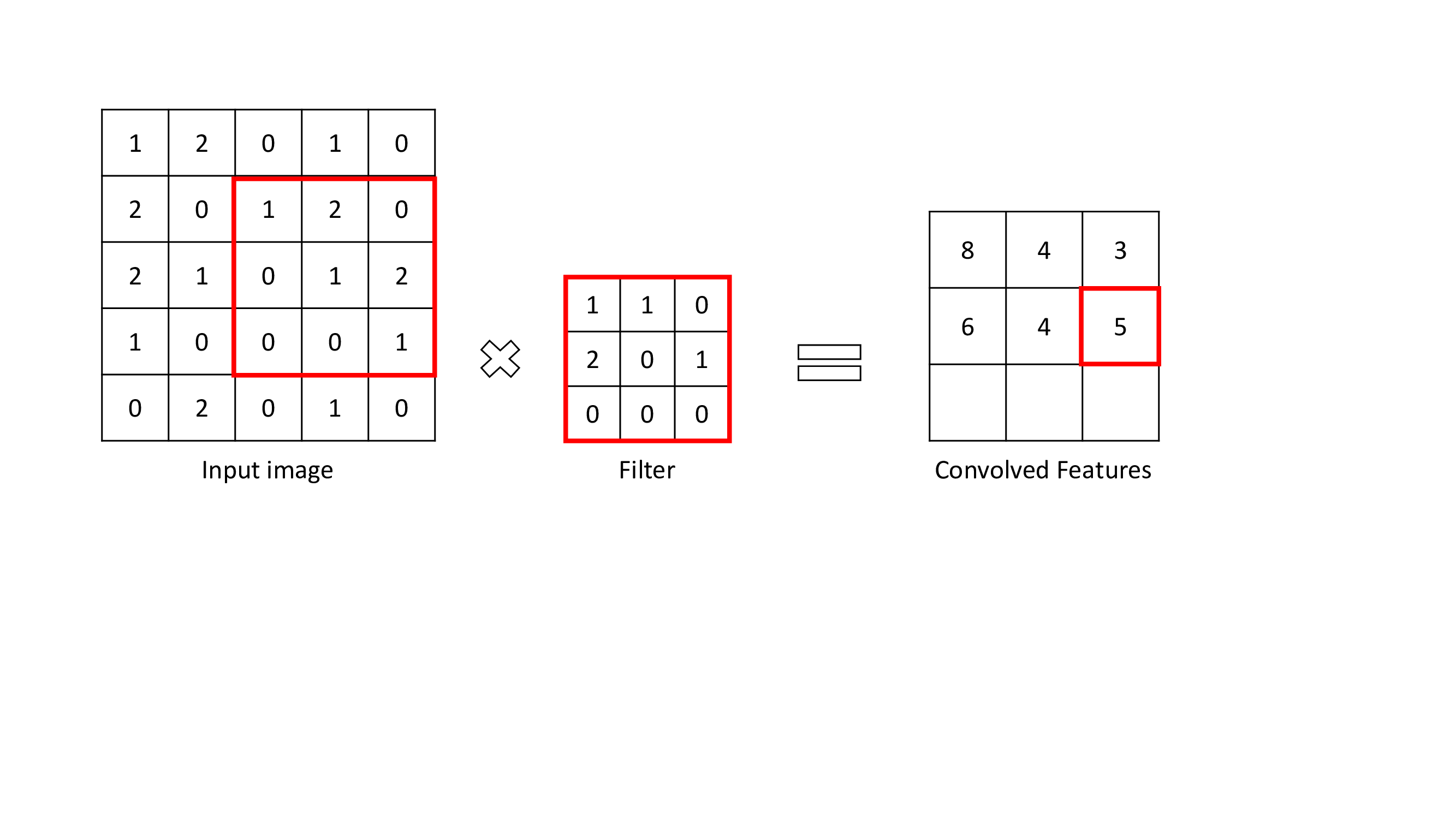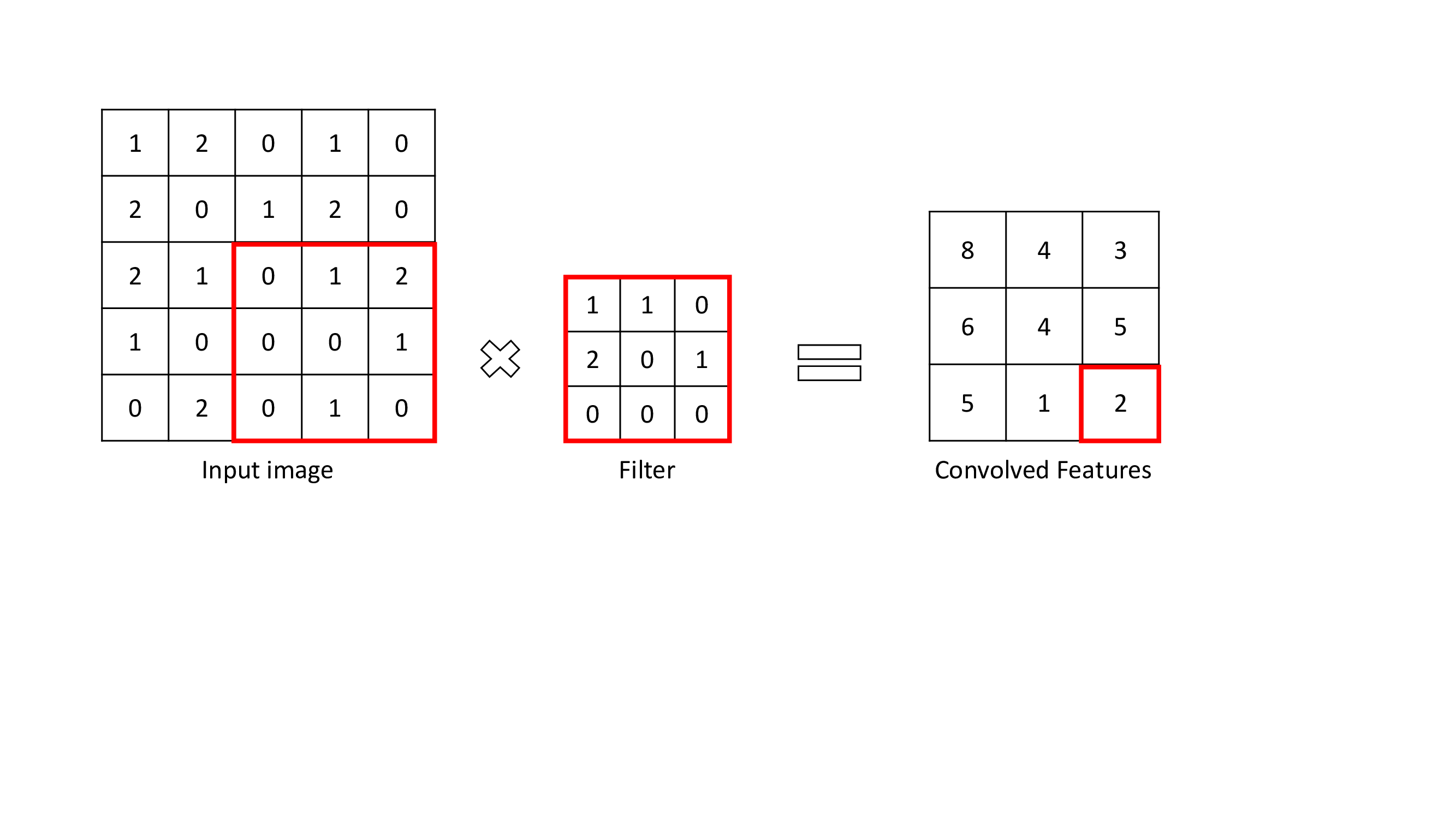
With different filters, different operations can be performed like edge detection, blur, etc.

To perform a convolution operation, a filter should be specified as a certain size. The filter moves across the input image matrix and multiplies values with filter and summing. The result is smaller in size than the input image matrix size.
To sum up, in CNN convolutional layer is the most important step or layer. This is used to extract important features from the input image matrix. A CNN can consist of any number of convolutional layers.
Non-Linear Layer
This layer is added after every convolutional layer to introduce non-linearity to the matrix. Non-linearity is introduced so that the output is not affected by the input or the output is not proportional to the input. This nonlinearity is done by activation functions. That topic is for another article.
Why do we need non-linearity in the neural network? might be a question. If the data doesn’t have non-linearity, then the input is directly influencing the output, and it doesn’t matter how many layers we use. The outcome will be the same. By increasing the power of non-linearity, the network is created to find more new and unique patterns in the data.
The commonly used activation functions are RELU, Tanh, etc.
Padding
Now you have understood how important is the convolutional layer. A kernel or filter is used to extract important features. I mentioned that the convolutional layer could be used any number of times, and every time the size of the feature map decreases. We don’t need that. Consider an input matrix of 5×5 and a filter of size 3×3. The size of the feature map is 5–3+1 = 3. If we add another layer, then the size is 1.
To make a feature map of size of same as the input matrix, we use padding. Let’s reverse engineer. We need a feature map of size 5. The filter size is 3. from the above formula, n = 5+f-1 = 5+3–1 = 7. We need an input matrix of size 7 from a size 5 input matrix. We add padding, i.e., a row on top, bottom, and column on left and right, giving a matrix of size 7×7. now the math, n-f+1 = 7–3+1 = 5. Hence proved.
Padding formula = n+2p-f+1
p = padding
If p = 1, then one row and one column, so thats why we add 2p, so we get 2 rows and 2 columns.
The above-added rows and columns are filled with zeros, called as zero padding.
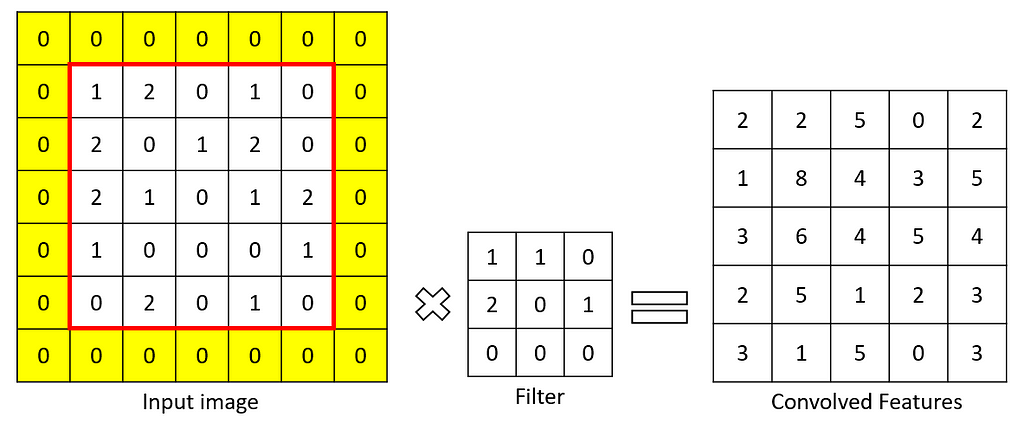
This is how padding is applied.
Strides
We talked about filters in the convolutional layer. Strides are defined as the number of pixels to move in any direction to apply the filter. If the stride is [1,1], then the filter moves 1 pixel at a time in either direction, and if it is [2,2] then the filter moves 2 pixels in either direction.
This parameter is mainly useful when there is an input image with high resolution, then more pixels to filter. The larger the stride, the smaller the convolution features map.
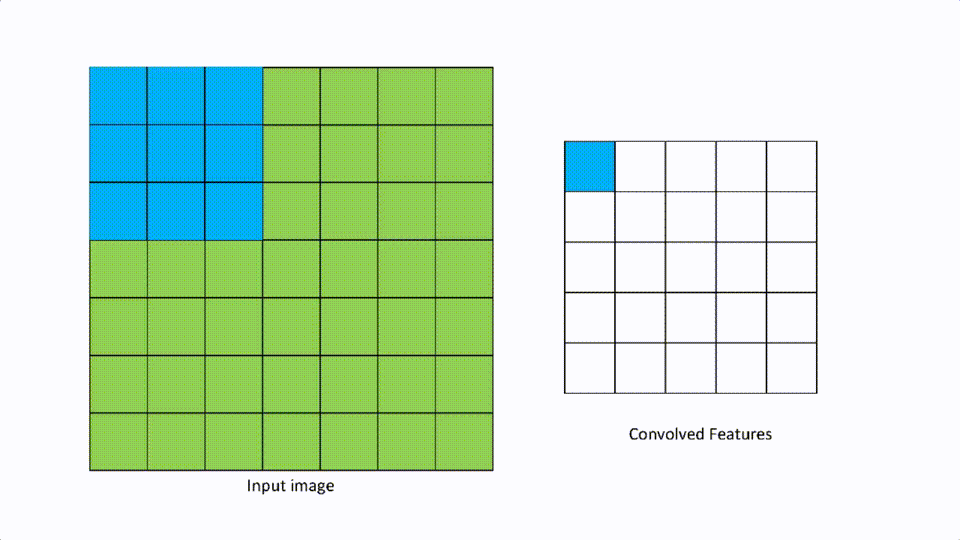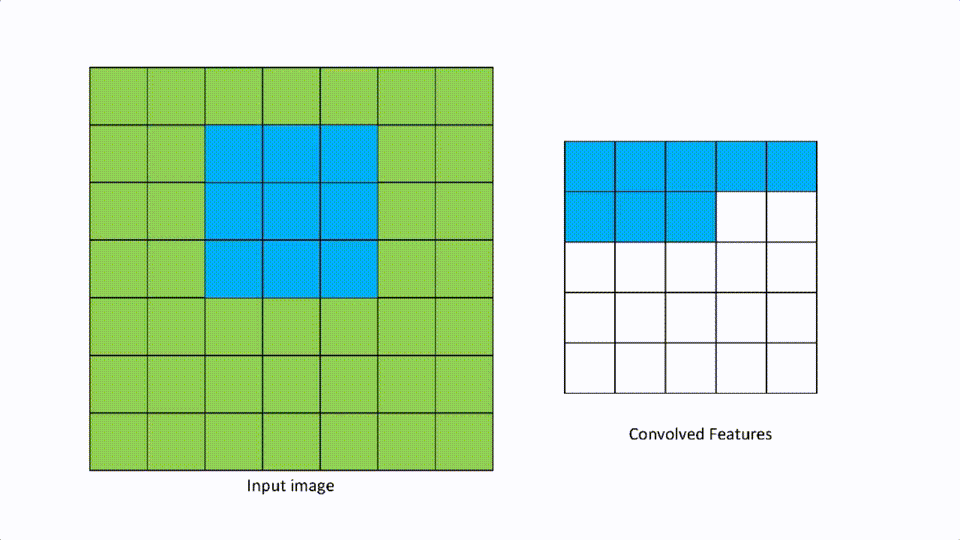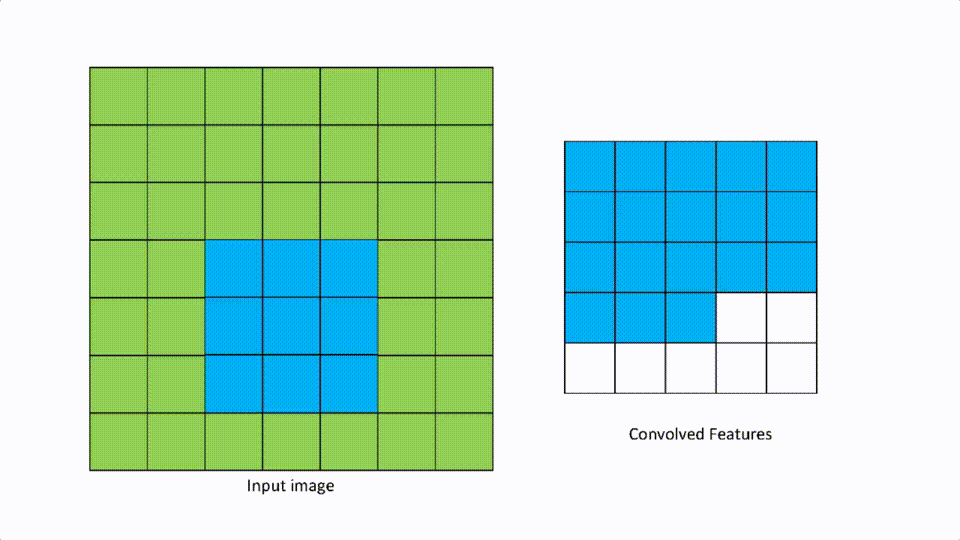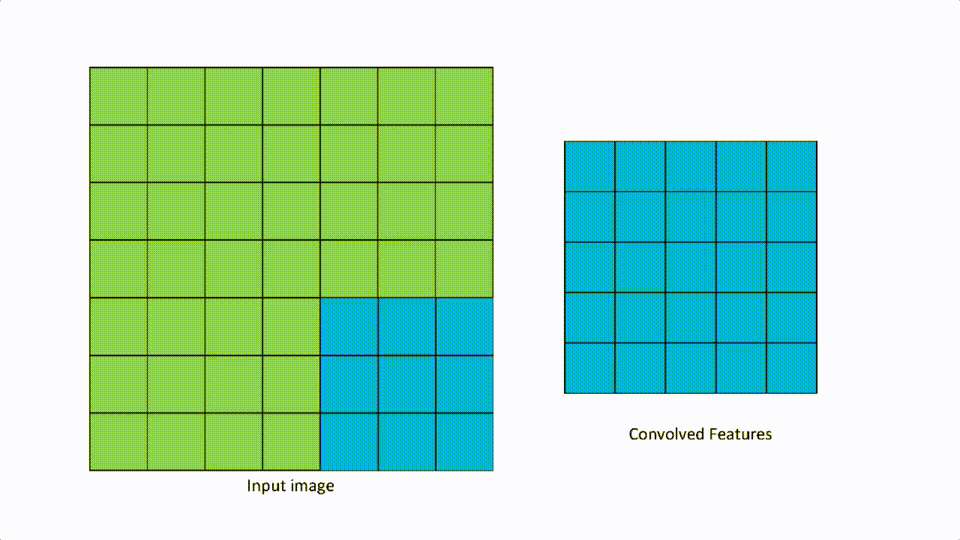
A [1,1] looks like the above.
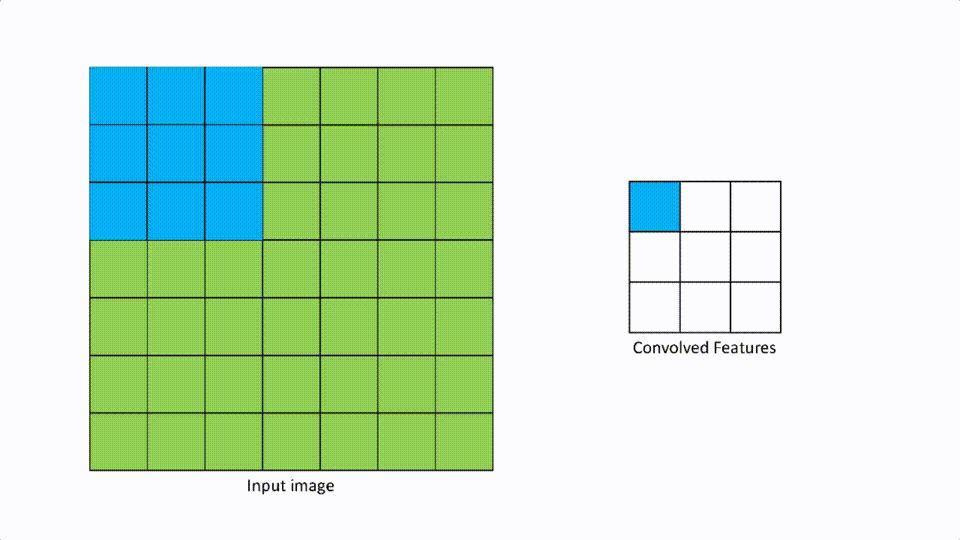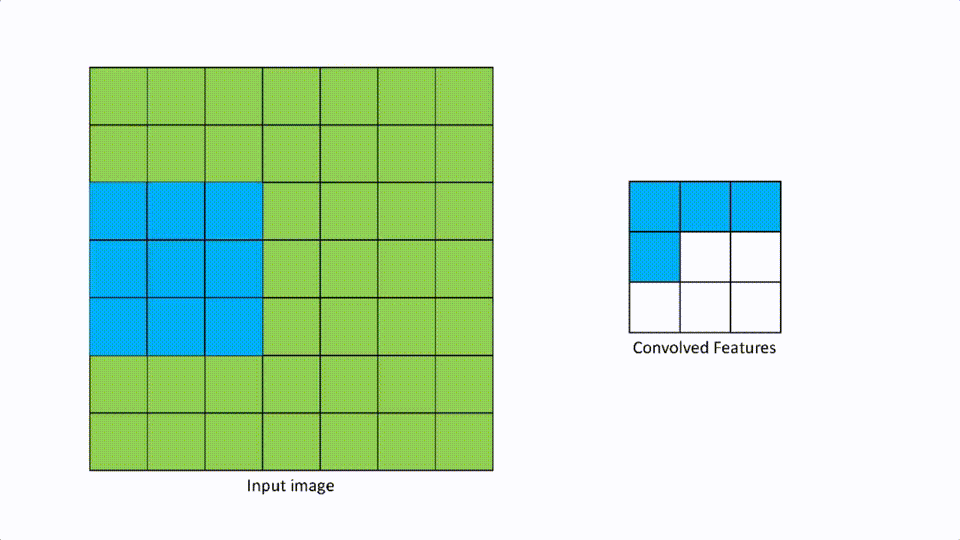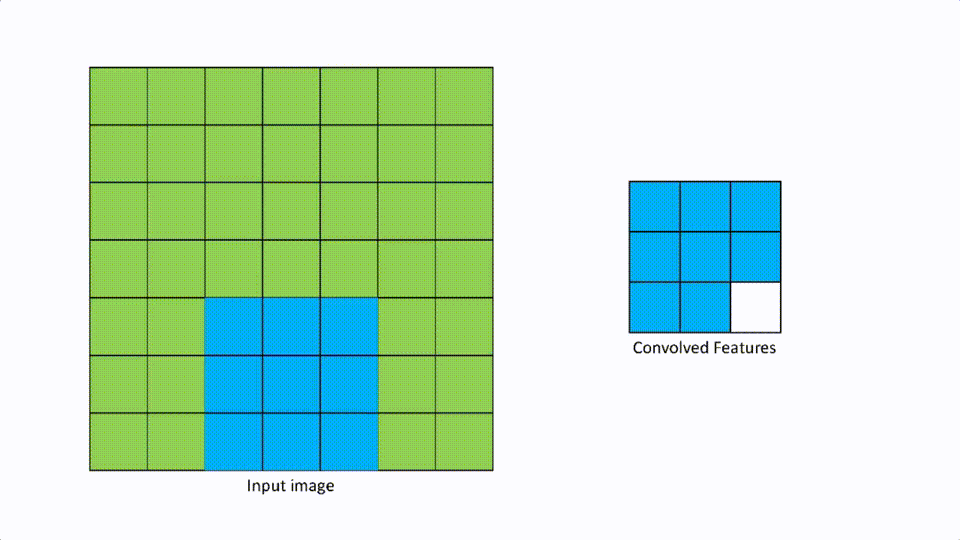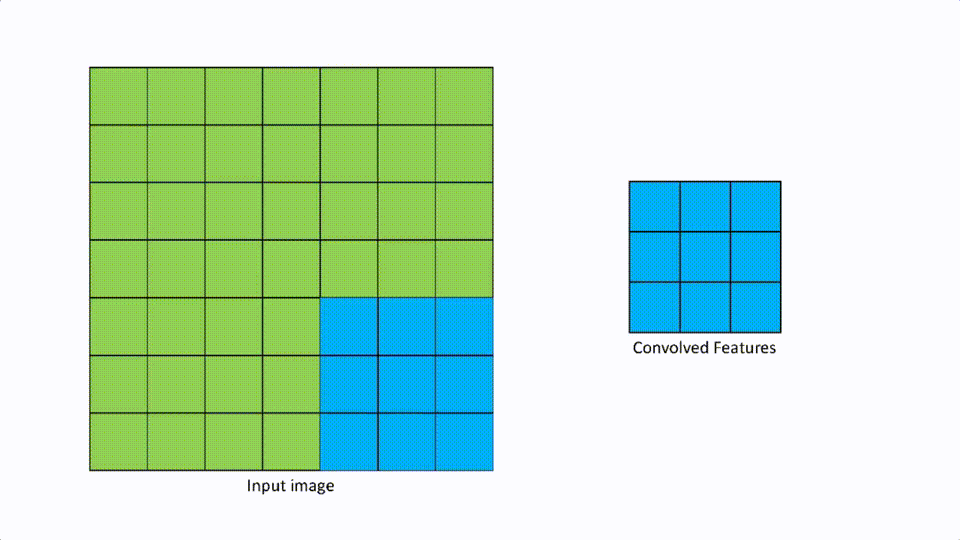
A [2,2] stride looks like the above.
To summarize, Strides is a value where the kernel or filter will move on the input matrix.
Pooling Layers
If deducing the input image to 1/4 determines what the whole image depicts, then it is no good in processing the whole image. This is where pooling comes into place.
This is the layer where the large feature matrix is reduced by retaining features. This is called spatial spacing. Pooling also has a kernel and strides. There are different types of spatial spacing.
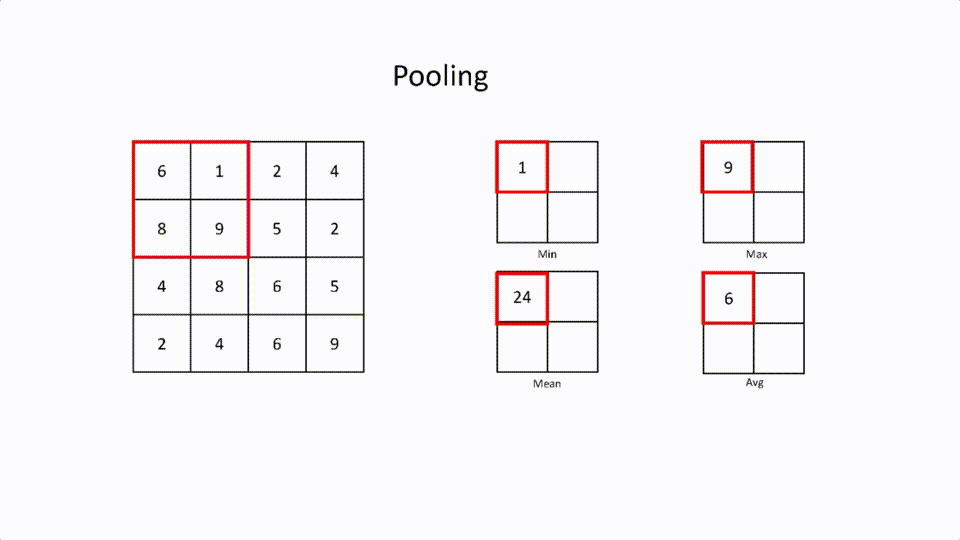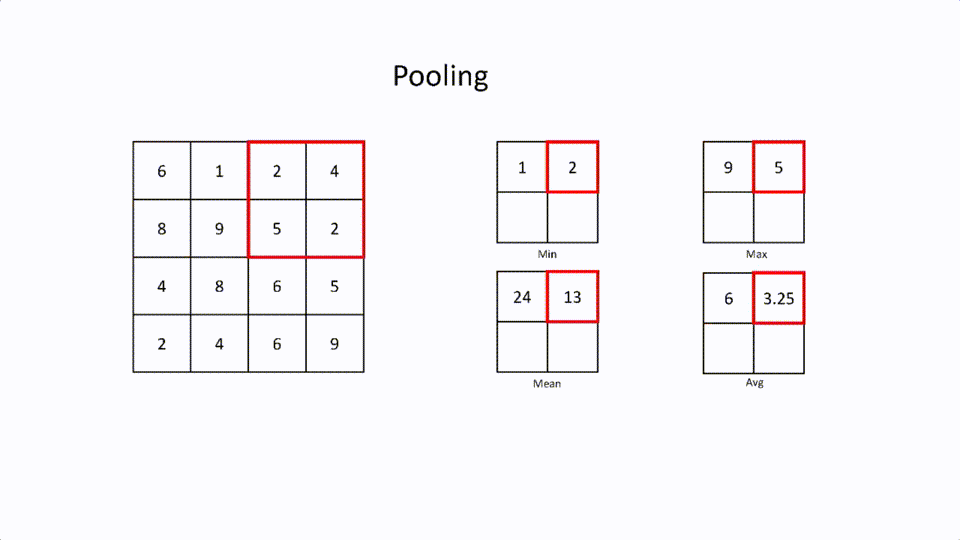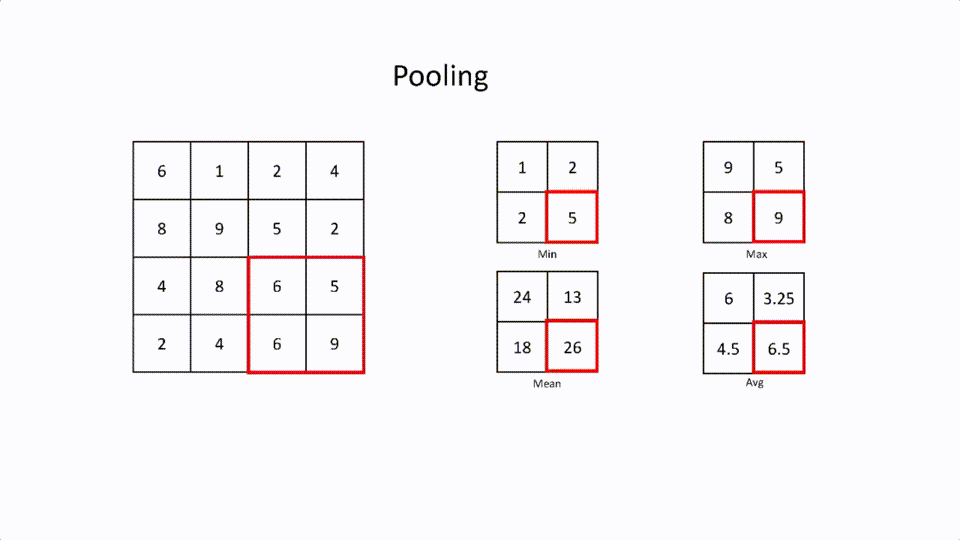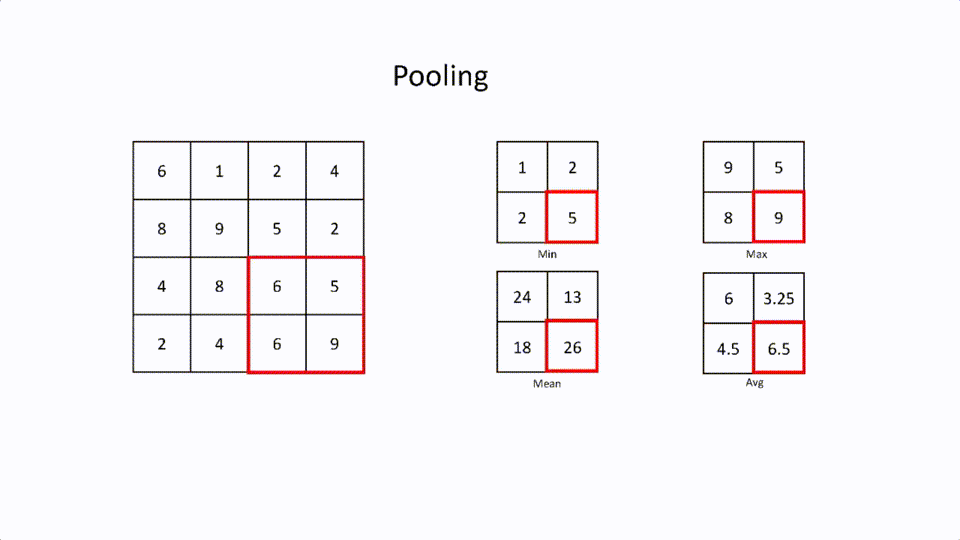
- Max Pooling: This is where the largest element in the filter is selected.
- Min Pooling: This is where the least element in the filter is selected.
- Mean Pooling: This is the mean of all the elements in the filter.
- Average Pooling: This is the average of all the elements in the filter.
This pooling layer is mainly used to connect Convolutional Layer and the Fully connected layer. The main reason the pooling layer is used after the convolutional layer because to reduce feature map size to save computational resources.
Fully Connected Layers
So until now, we have received a matrix with important features. This matrix is flattened into a 1d vector and feeding it into a fully connected neural network. It is called a fully connected layer because each and every neuron is connected to each neuron in the next layer.
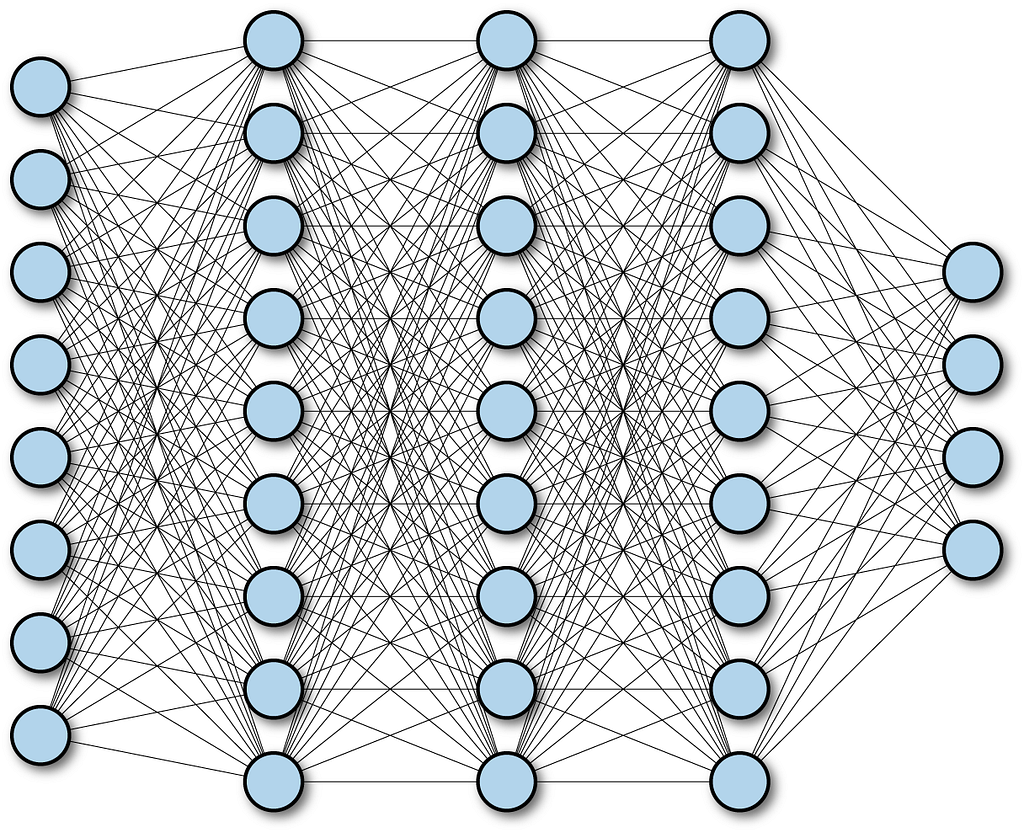
The output layer basically uses the softmax activation function. Softmax activation is used, so the sum of all the probabilities of output is 1. From here, the network acts as a neural network.
Conclusion:
CNN is a deep learning concept to extract features and patterns from images. CNN is a basic ANN but has 2 more layers called the convolutional layer and the pooling layer.
CNN mostly benefits from the healthcare industry.
References:
Well, this the what I learned about CNN. More advanced concepts for another article. Let us meet at the next one. If you enjoy this content, giving it some claps👏 will give me a little extra motivation.
You can reach me at:
LinkedIn: https://www.linkedin.com/in/pranay16/
GitHub: https://github.com/pranayrishith16
An Introduction to CNNs: Understanding the Basics was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

