



Time Series Data Analysis In Python
Last Updated on January 6, 2023 by Editorial Team
Last Updated on March 31, 2022 by Editorial Team
Author(s): Youssef Hosni
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A practical guide for time series data analysis in Python Pandas
Time series data is one of the most common data types in the industry and you will probably be working with it in your career. Therefore understanding how to work with it and how to apply analytical and forecasting techniques are critical for every aspiring data scientist. In this series of articles, I will go through the basic techniques to work with time-series data, starting from data manipulation, analysis, visualization to understand your data and prepare it for and then using statistical, machine, and deep learning techniques for forecasting and classification. It will be more of a practical guide in which I will be applying each discussed and explained concept to real data.
This series will consist of 8 articles:
- Manipulating Time Series Data In Python Pandas [A Practical Guide]
- Time Series Analysis in Python Pandas [A Practical Guide] (You are here!)
- Visualizing Time Series Data in Python [A practical Guide]
- Arima Models in Python [A practical Guide]
- Machine Learning for Time Series Data [A practical Guide]
- Deep Learning for Time Series Data [A practical Guide]
- Time Series Forecasting project using statistical analysis, machine learning & deep learning.
- Time Series Classification using statistical analysis, machine learning & deep learning.
Table of content:
- Correlation and Autocorrelation
- Time Series Models
- Autoregressive (AR) Models
- Moving Average (MA) and ARMA Models
- Case Study: Climate Change
All the codes and datasets used in this article can be found in this repository.
1. Correlation and Autocorrelation
In this section, you’ll be introduced to the ideas of correlation and autocorrelation for time series. Correlation describes the relationship between two-time series and autocorrelation describes the relationship of a time series with its past values.
1.1. Correlation of Two Time Series
The correlation of the two-time series measures how they vary with each other. The correlation coefficient summarizes this relation in one number. A correlation of one means that the two series have a perfect linear relationship with no deviations. High correlations mean that the two series strongly vary together. A low correlation means they vary together, but there is a weak association. And a high negative correlation means they vary in opposite directions, but still with a linear relationship.
There is a common mistake when calculating the correlation between two trending time series. Consider two-time series that are both trending. Even if the two series are totally unrelated, you could still get a very high correlation. That’s why, when you look at the correlation of say, two stocks, you should look at the correlation of their returns, not their levels.
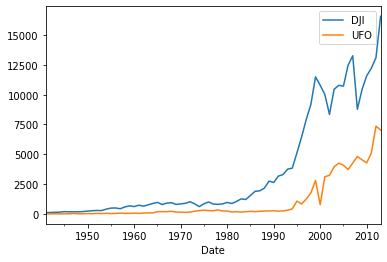
In the example below, the two series, stock prices, and UFO sightings, both trend up over time. Of course, there is no relationship between those two series, but the correlation is 0.94. But if you compute the correlation of percent changes, the correlation goes down to approximately zero.

The figure below shows that the two series are correlated when plotted with the time. The reason for this as mentioned is that they are both trending series.
1.2. Simple Linear Regression
A simple linear regression for time series finds the slope, beta, and intercept, alpha, of a line that’s the best fit between a dependent variable, y, and an independent variable, x. The x’s and y’s can be two-time series.
Regression techniques are very common, and therefore there are many packages in Python that can be used. In statsmodels, there is OLS. In numpy, there is polyfit, and if you set degree equals 1, it fits the data to a line, which is a linear regression. Pandas have an ols method, and scipy has a linear regression function. Beware that the order of x and y is not consistent across packages.
In the example below, we will regret the values of the oil prices using the sp500 as an independent variable. The data can be found here. You need to add a column of ones as a dependent, right-hand side variable. The reason you have to do this is that the regression function assumes that if there is no constant column, then you want to run the regression without an intercept. By adding a column of ones, statsmodels will compute the regression coefficient of that column as well, which can be interpreted as the intercept of the line. The statsmodels method “add constant” is a simple way to add a constant.
The regression output is shown in the figure below.
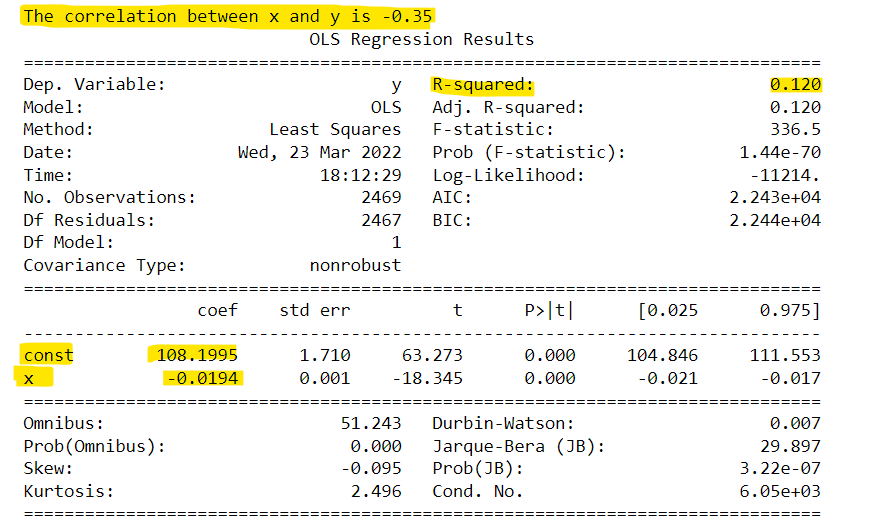
We will only focus on the yellow highlighter items of the regression results. The coef contains the slope and the intercept of the regression analysis. Since the two variables are negatively correlated the slope is negative. The second important statistic to take note of is the R-Squared which is 0.12. The R-squared measures how well the linear regression line fits the data. There is a relation between the correlation and the R-squared. The magnitude of the correlation is the square root of the R-squared. And the sign of the correlation is the sign of the slope of the regression line.
1.3. Autocorrelation
Autocorrelation is the correlation of a single time series with a lagged copy of itself. It’s also called serial correlation. Often, when we refer to a series’s autocorrelation, we mean the “lag-one” autocorrelation. So when using daily data, for example, the autocorrelation would be the correlation of the series with the same series lagged by one day.
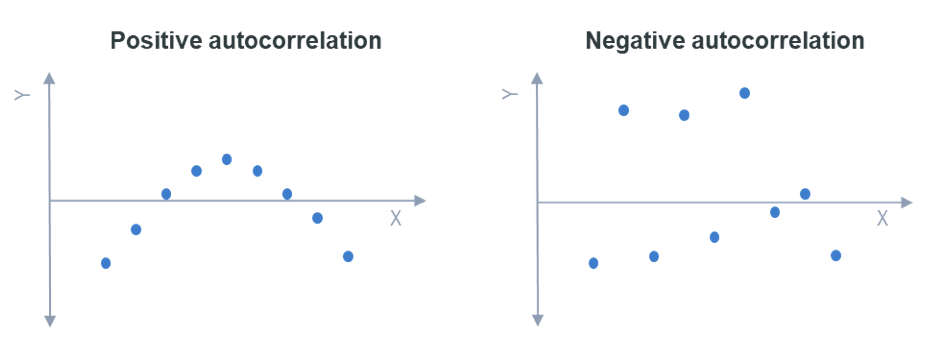
positive autocorrelation, which is also known as trend following, means that the increase observed in a time interval leads to a proportionate increase in the lagged time interval. While negative autocorrelation, which is known as mean-reverting, means that if a particular value is above average the next value (or for that matter the previous value) is more likely to be below average. The figure below shows an example of both of them.
The autocorrelation of time series has many real-world applications. Many hedge fund strategies are only slightly more complex versions of mean reversion and momentum strategies. Since stocks have historically had negative autocorrelation over horizons of about a week, one popular strategy is to buy stocks that have dropped over the last week and sell stocks that have gone up. For other assets like commodities and currencies, they have historically had positive autocorrelation over horizons of several months, so the typical hedge fund strategy there is to buy commodities that have gone up in the last several months and sell those commodities that have gone down.
1.4. Autocorrelation Function
The autocorrelation function (ACF) is the autocorrelation as a function of the lag. Any significant non-zero autocorrelations imply that the series can be forecast from the past. It can be which values you should rely on to forecast the values in the future, discover seasonal earnings by observing the autocorrelation function at these seasons, and can be used for selecting a model for fitting the data as will be shown in section 3.
plot_acf is the statsmodels function for plotting the autocorrelation function. The input x is a series or array. The argument lags indicate how many lags of the autocorrelation function will be plotted. The alpha argument sets the width of the confidence interval. For example, if alpha equals 0.05, that means that if the true autocorrelation at that lag is zero, there is only a 5% chance the sample autocorrelation will fall outside that window. You will get a wider confidence interval if you set alpha lower, or if you have fewer observations.
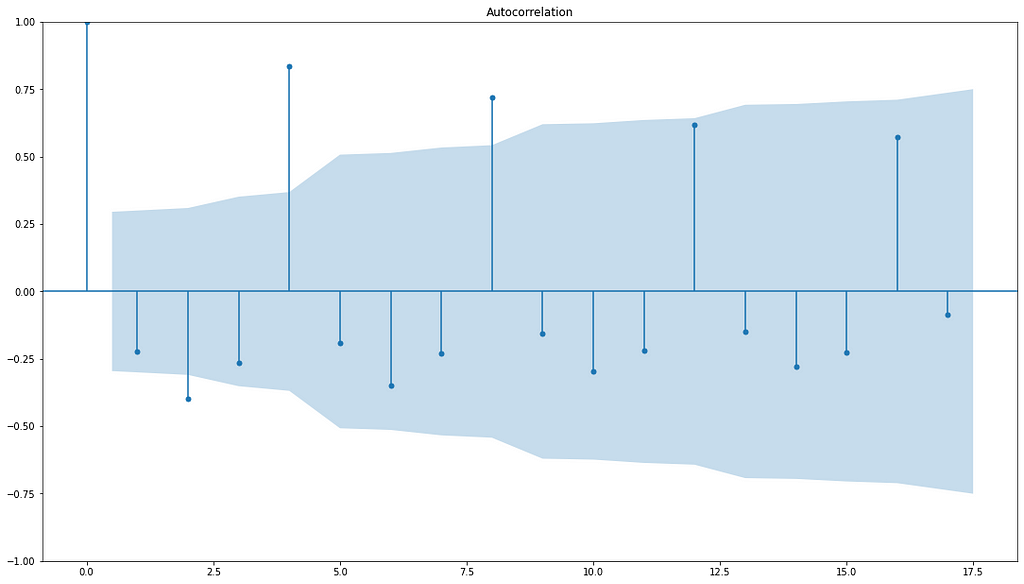
if you want no bonds set alpha = 1
2. Time Series Models
In this section, you’ll learn about some simple time series models. These include white noise and a random walk.
2.1. White Noise
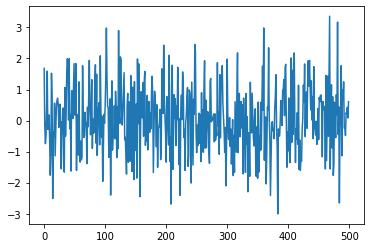
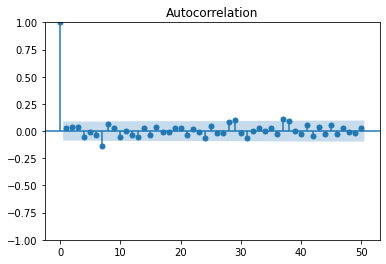
White noise is the series with constant mean and variance with time and zero autocorrelation at all lags. There are several special cases of white noise. For example, if the data is white noise but also has a normal, or Gaussian, distribution, then it is called Gaussian White Noise.
The white noise looks like the following:
The autocorrelation of the white noise:
2.2. Random Walk
In a random walk, today's price is the same as yesterday's price in addition to white noise.
P(t) = P(t-1) + white-noise
Therefore the change in the price is white noise. Since we cannot forecast the white noise, the best forecast for today's price will be yesterday's price.
To test whether a time series follows a random walk or not, we can regress the current value (for example the price) with the lagged values. If the slope coefficient is significantly less than one, we can reject the null hypothesis (series follows a random walk). If it is not significantly different from one, we cannot reject the null hypothesis.
Another way to do it is to regress the difference in values on the lag values and test the slope coefficient to be zero instead of one. This is known as the Dickey-Fuller test and if more lagged values are added it will be called the Augmented Dickey-Fuller (ADF) test.
The example below shows how to apply this test to the SP500 data in python using the statsmodels library.
The p-value is 0.9 which means that the difference is not significant and we cannot reject the null hypothesis therefore the SP500 time series follows a random walk.
2.3. Stationary
Stationery signals are the signals that their joint distribution does not depend on time. A more practical definition is the weak stationery definition which means that the mean, variance, and autocorrelation of the signal do not depend on time.
Stationery is a very important concept in time series analysis and forecasting. The reason for this is that if the series is not stationary we would not be able to model and forecast it. The main task of the modeling step is estimating a set of parameters that could be used for the required tasks such as forecasting. If the series is non-stationary, its parameters will be changing over time so you will not be able to model it. A random walk is a common type of non-stationary series. The variance grows with time. For example, if stock prices are a random walk, then the uncertainty about prices tomorrow is much less than the uncertainty 10 years from now. Seasonal series are also non-stationary.
Many non-stationary series can be made stationary through a simple transformation. A Random Walk is a non-stationary series, but if you take the first differences, the new series is White Noise, which is stationary.
In the example below the S&P 500 prices which is a non-stationary random walk, the signal is transformed into a stationary white noise signal by taking the first difference.
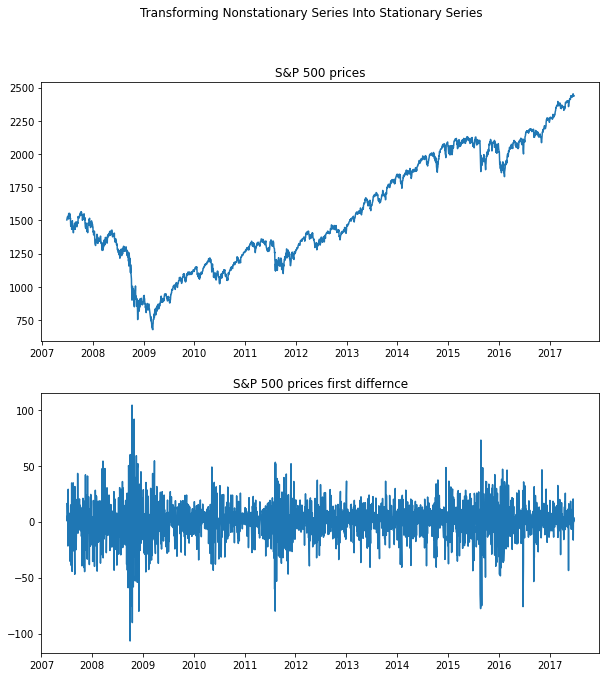
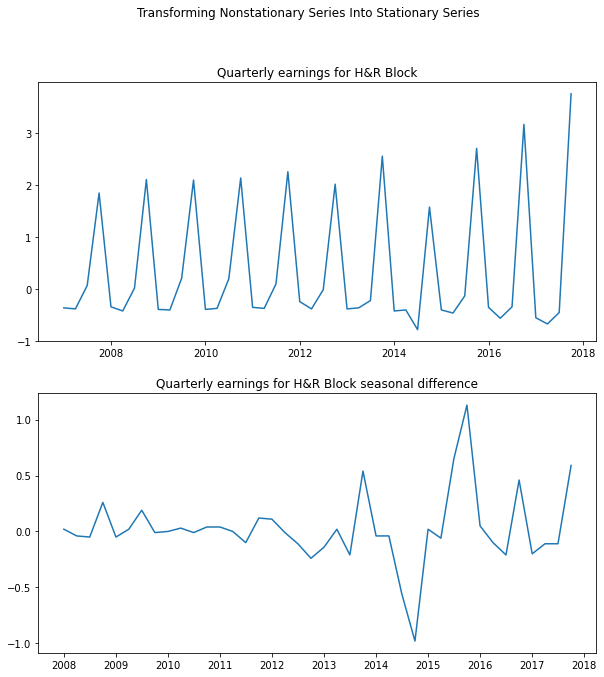
The example below is for the quarterly earnings for H&R Block, which has a large seasonal component and is therefore not stationary. If we take the seasonal difference, by taking the difference with a lag of 4, the transformed series looks stationary.
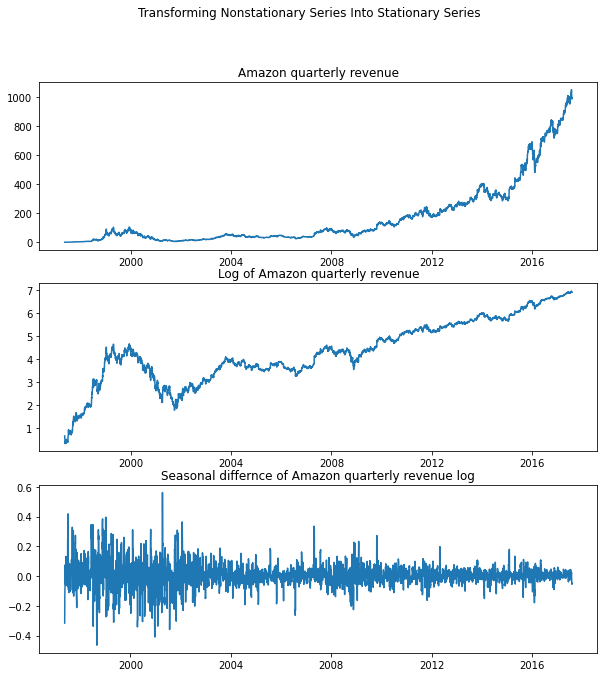
The last example is Amazon's quarterly revenue. It is growing exponentially as well as exhibiting a strong seasonal pattern. First, We will take only the log of the series to eliminate the exponential growth. But if you take both the log of the series and then the seasonal difference, the transformed series looks stationary.
3. Autoregressive (AR) Models
In this section, we will explain the autoregressive, or AR, models for time series. These models use past values of the series to predict the current value.
3.1. AR Models Definition
An autoregressive (AR) model predicts future behavior based on past behavior. It’s used for forecasting when there is some correlation between values in a time series and the values that precede and succeed them.
In the AR model, today's value is equal to the fraction (phi) of yesterday's value in addition to noise and the mean as shown in the equation below:
R(t) = mean + phi*R(t-1) + noise.
Since we only look at one previous step in time then this is AR(1) model, the model can be extended to include more lagged values and more phi parameters. Here we show an AR(1), an AR(2), and an AR(3).
If phi is equal to one, then the series will represent a random walk as discussed in the previous section and if it is zero it will be white noise. In order for the process to be stable and stationary, phi has to be between -1 and +1. If phi has a negative value then a positive return last period, at time t-1, implies that this period’s return is more likely to be negative. We referred to this as mean reversion in section 1.3. If phi has a positive value, then a positive return last period implies that this period’s return is expected to be positive. We referred to this as momentum in section 1.3.
The example below shows four simulated time series with different phi values (0.9, -0.9, 0.5,-0.5):
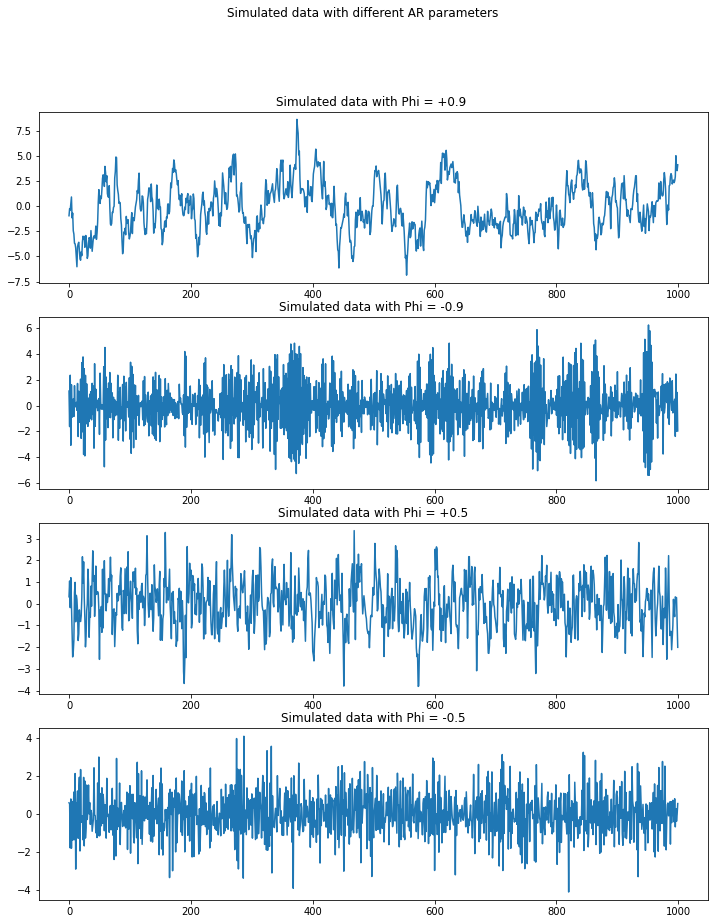
When phi is 0.9, it looks close to a random walk. When phi equals -0.9, the process has a large positive value is usually followed by a largely negative one. The bottom two are similar but are less exaggerated and closer to white noise.
To have better understanding let's look at the autocorrelation function of these four simulated time series:
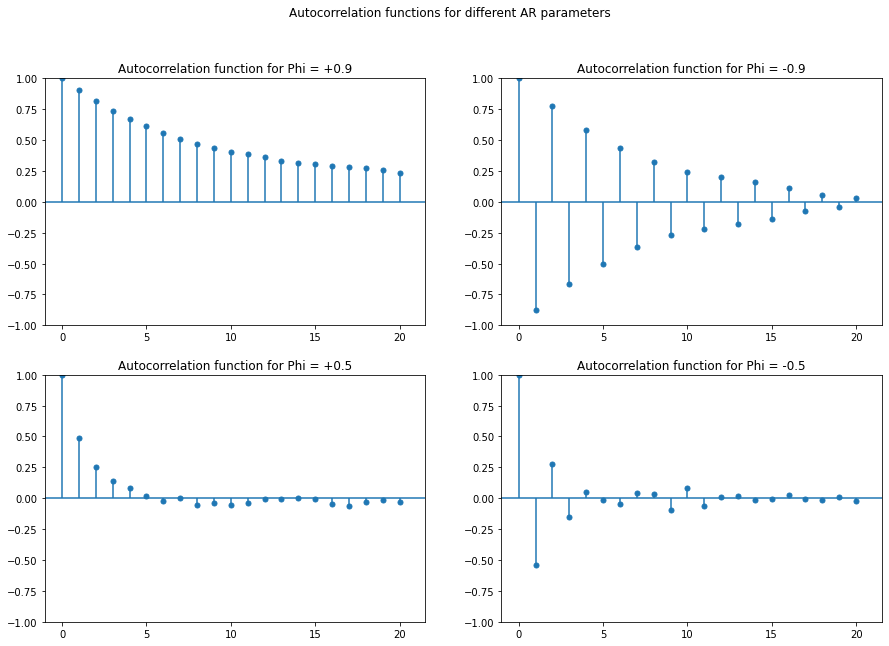
If the phi is positive the autocorrelation function will decay exponentially at the rate of phi. This means that if phi is 0.9, then the autocorrelation at 1 is 0.9 and at 2 is (0.9)**2 and at 3 is (0.9)**3, and so on. If phi is negative then it will be the same but it will reverse its sign at each lag.
3.2. Estimating & Forecasting AR Models
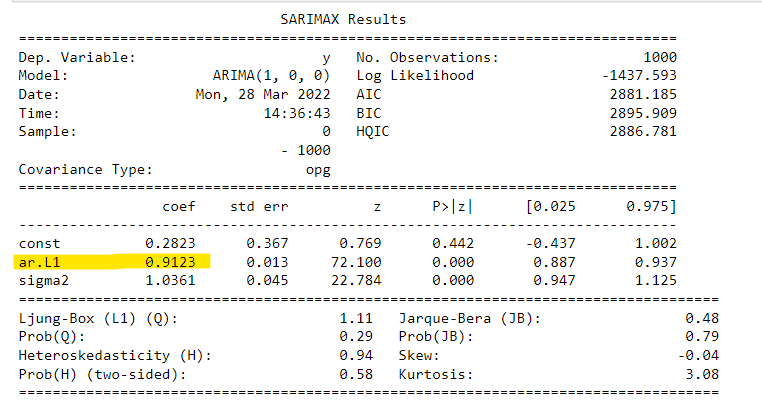
To estimate the parameters of AR models for a time series we can use the ARIMA class as shown in the example below:
The order (1,0,0) means you’re fitting the data to an AR(1) model. An order (2,0,0) would mean you’re fitting the data to an AR(2) model. The second and third parts of the order will be discussed in the next section.
The summary of the results is shown below, the phi parameter is highlighted in yellow. We can see that it is 0.91 which is similar to the phi parameter of the simulated data used in the previous subsection.
3.3. Choosing the Right Model
In the previous subsection, the order of the model was already known. However, in practice, this will not be given to you. There are different methods to determine the order of the AR model. We will focus on two of them: The Partial Autocorrelation Function, and the Information Criteria.
The partial autocorrelation function (PACF) measures the incremental benefits of adding another lag. To have a better understanding of PACF let's first define the partial autocorrelation. A partial autocorrelation is a description of the relationship between an observation in a time series and data from earlier time steps that do not take into account the correlations between the intervening observations. The correlation between observations at successive time steps is a linear function of the indirect correlations. These indirect connections are eliminated using the partial autocorrelation function.
Based on this definition of partial autocorrelation, The PACF indicates only the association between two data that the shorter lags between those observations do not explain. The partial autocorrelation for lag 3 is, for example, merely the correlation that lags 1 and 2 do not explain. In other words, the partial correlation for each lag is the unique correlation between the two observations after the intermediate correlations have been removed.
To plot the PACF you can use the plot_pacf function from the statsmodels library as shown in the example below:
We generated two simulated data with AR(1) and AR(2), the figure below shows the PACF for both of them:
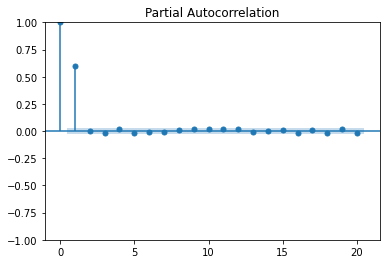
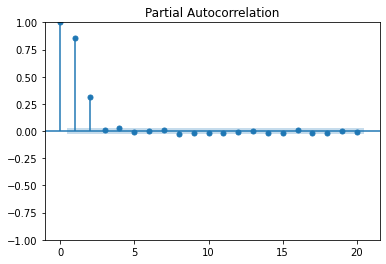
These plots show the Partial Autocorrelation Function for AR models of different orders. In the upper plot, for an AR(1) model, only the lag (1) PACF is significantly different from zero. Similarly, for an AR(2) model, two lags are different from zero.
If we applied the ARIMA function that we used in the previous subsection, to the simulated data used in the previous example and used the order of the model we got out of the PACF plot. We should get the same parameters from the function as the one used in generating the simulated data. In the example below we used the simulated data with AR(2) and phi of 0.6 and 0.3:
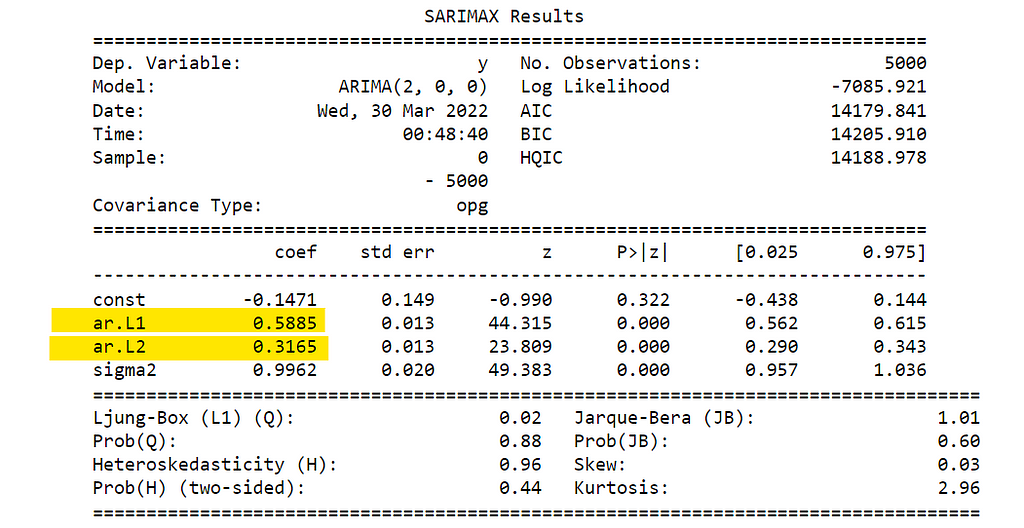
The coefficients highlighted in yellow are phi_1 and phi_2, which are as expected 0.6 and 0.3.
The more parameters in a model, the better the model will fit the data. But this can lead the model to overfit the data. The information criteria adjust the goodness-of-fit of a model by imposing a penalty based on the number of parameters used. Two common adjusted goodness-of-fit measures are called the Akaike Information Criterion (AIC) and the Bayesian Information Criterion(BIC).
The AIC is a mathematical method for evaluating how well a model fits the data it was generated from. In statistics, AIC is used to compare different possible models and determine which one is the best fit for the data. The best-fit model according to AIC is the one that explains the greatest amount of variation using the fewest possible independent variables. BIC is a criterion for model selection among a finite set of models. It is based, in part, on the likelihood function, and it is closely related to AIC. When fitting models, it is possible to increase the likelihood by adding parameters, but doing so may result in overfitting. The BIC resolves this problem by introducing a penalty term for the number of parameters in the model. The penalty term is larger in BIC than in AIC.
In practice, the way to use the information criteria is to fit several models, each with a different number of parameters, and choose the one with the lowest Bayesian information criterion. This is shown in the example below:
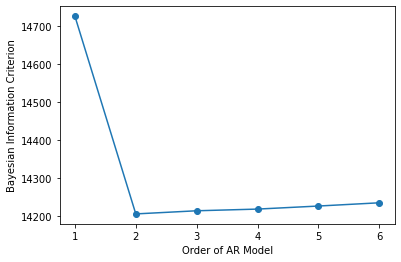
You can see that the lowest BIC occurs for an AR(2), which is what the simulated data was from.
4. Moving Average and ARMA Models
In this section, we will go through another kind of model, the moving average, or MA, model. We will also see how to combine AR and MA models into a powerful ARMA model.
4.1.Moving Average Model Definition
In the MA model, today's values equal a mean plus noise, plus a fraction of theta of yesterday's noise. This is shown in the following equation:
R(t) = Mean + noise + theta* (yesterday-noise)
This is called an MA model of order 1, or simply an MA(1) model as we take into consideration only yesterday's noise, if we look for two previous days it will be MA(2), and so on. If the MA parameter, theta, is zero, then the process is white noise. MA models are stationary for all values of theta.
Suppose R(t) is a time series of stock returns. If theta is negative, then a positive shock last period, represented by epsilon(t-1), would have caused the last period’s return to be positive, but this period’s return is more likely to be negative. A shock two periods ago would have no effect on today’s return — only the shock now and last period.
To create simulated data from the MA model we can use ArmaProcess from the statsmodels library as shown in the example below:
4.2. Estimation of MA Model
To estimate the MA model from given time series, we can use the same method as in estimating the AR model shown before in section 3.2. We will use the ARIMA function, but the order will be (0,0,1) instead of (1,0,0). An example of this is shown below:
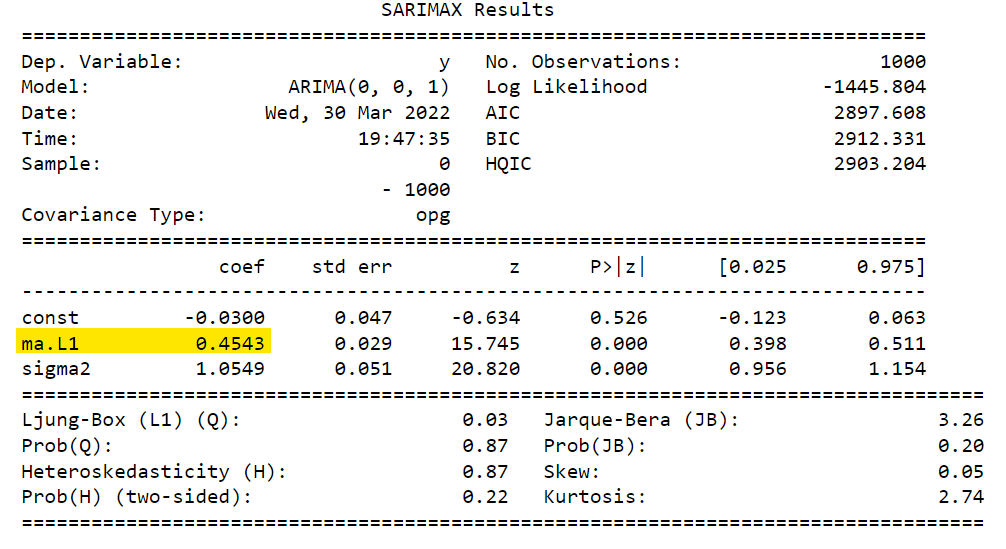
The number highlighted in yellow is the theta parameter for the simulated data. The result agrees with our expectation as the parameter used for generating the simulation data was 0.
4.3. ARMA Models
An ARMA model is a combination of both the AR and MA models. Here is the formula of the ARMA(1,1) model:
R(t) = Mean + theta * Noise(t-1) + phi* R(t-1) + Noise(t)
5. Case Study: Climate Change
Let's put all the concepts covered in this article together through the climate change case study. We will analyze some temperature data taken over almost 150 years. The data was downloaded from the NOAA website.
The following steps will be done:
- Apply pandas methods by converting the index to DateTime and plotting the data.
- Apply the Augmented Dickey-Fuller test to see whether the data is a Random Walk.
- Take the first differences in the data to transform it into a stationary series
- Compute the Autocorrelation Function and the Partial Autocorrelation Function of the data.
- Fit AR, MA, and ARMA models to the data.
- Use the Information Criterion to choose the best model among the ones you looked at.
- Finally, with the best model, forecast temperatures over the next 30 years.
The first two steps are done with the code below:
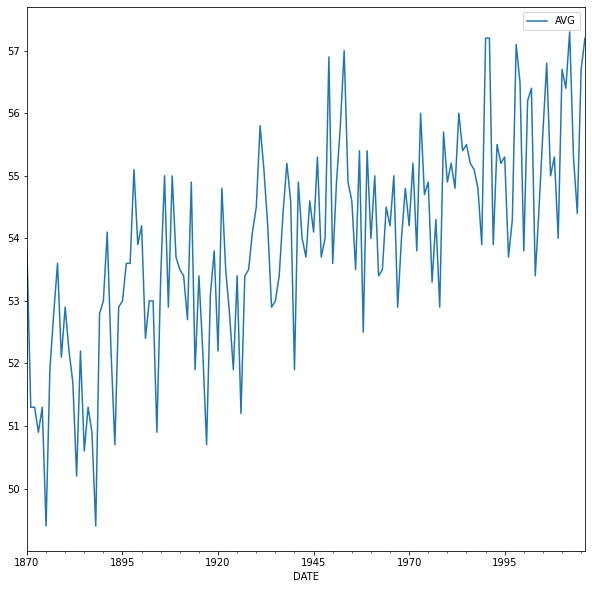
The p-value of the ADF test is 0.58, which means that the time series is not stationary and we cannot reject that it is a random walk.
The third and fourth steps are applied to the data using the code below:
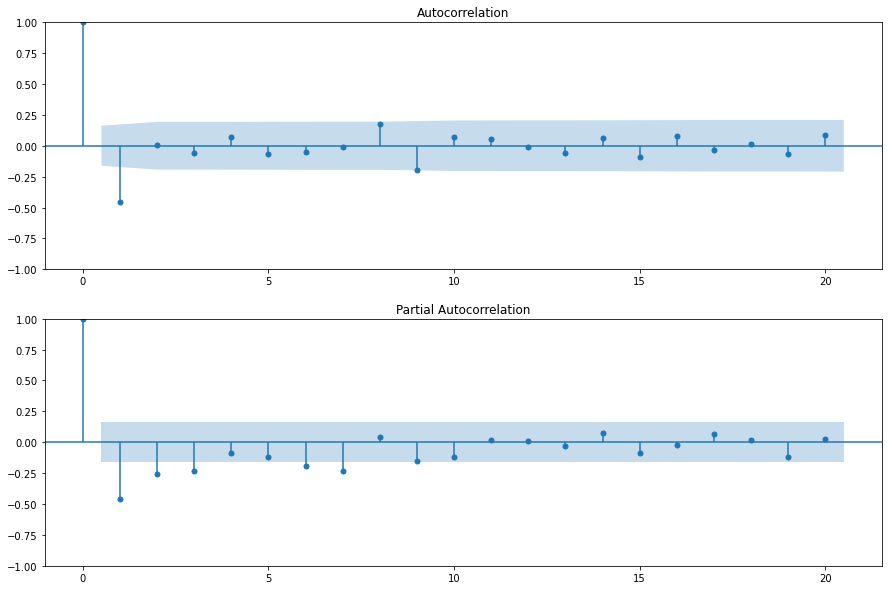
There is no clear pattern in the ACF and PACF except for the negative lag-1 autocorrelation in the ACF.
After that, the data three models will be fitted to the data and the AIC is calculated for each model. This is done using the code below:
The AIC for three models is shown below:

The ARMA(1,1) has the lowest AIC values among the three models. Therefore it will be used for parameters estimation and forecasting.
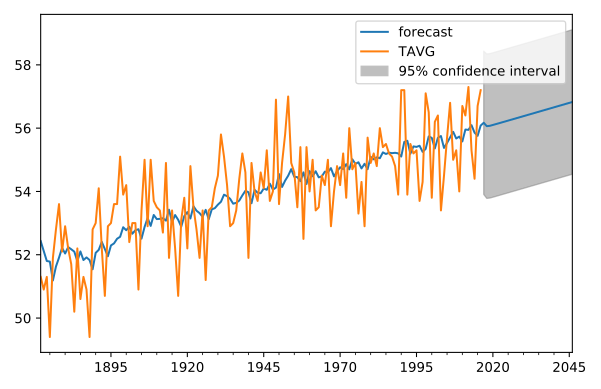
According to the model, the temperature is expected to be about 0.6 degrees higher in 30 years (almost entirely due to the trend), but the 95% confidence interval around that is over 5 degrees.
References
[1]. https://app.datacamp.com/learn/courses/time-series-analysis-in-python
[2]. https://www.statisticshowto.com/autoregressive-model/
[4]. https://www.scribbr.com/statistics/akaike-information-criterion/
[5]. https://medium.com/@analyttica/what-is-bayesian-information-criterion-bic-b3396a894be6
Thanks for reading! If you like the article make sure to clap (up to 50!) and connect with me on LinkedIn and follow me on Medium to stay updated with my new articles.
Time Series Data Analysis In Python was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

