



The Non-Convexity Debate in Machine Learning
Last Updated on July 17, 2023 by Editorial Team
Author(s): Towards AI Editorial Team
Originally published on Towards AI.
Unpacking Mean Squared Error’s Impact on Logistic Regression
Author(s): Pratik Shukla
“If you can’t, you must. If you must, you can.” — Tony Robbins
Table of Contents:
- Proof of Non-convexity of the Mean Squared Error function for Logistic Regression
- A visual look at MSE for logistic
- Resources and references
Introduction:
In this tutorial, we will see why it is not recommended to use the Mean Squared Error function in logistic regression. Here, our goal is to prove that the Mean Squared Error function is not a convex function for logistic regression. Once we prove that the Mean Squared Error is not a convex function, we can establish that it is not recommended to use the Mean Squared Error function in logistic regression.
Logistic regression is a popular method used for binary classification in machine learning, statistics, and other related fields. It is often assumed that the mean squared error (MSE) function, which is commonly used as the loss function for linear regression, is also convex in logistic regression. However, recent studies have shown that the MSE function is non-convex in logistic regression, leading to challenges in model optimization and convergence. In this blog post, we will delve into the proof of the non-convexity of MSE in logistic regression, and examine the implications of this result for the performance and optimization of logistic regression models
Convex Function:
When we plot the MSE loss function with respect to the weights of the logistic regression model, the curve we get is not a convex curve. So, when the curve is not convex, it is very difficult to find the global minimum. The non-convex nature of MSE with the logistic regression is because of the sigmoid activation function which is non-linear. The sigmoid function makes the relationship between the weights and errors very complex.
Proof of Non-convexity of the Mean Squared Error function for Logistic Regression:
Let’s mathematically prove that the Mean Squared Error function for logistic regression is not convex.
We saw in the previous tutorial that a function is said to be a convex function if its double derivative is ≥0. So, here we will take the Mean Squared Error and find its double derivative to see whether it is ≥0 or not. If it’s ≥0, then we can say that it is a convex function.
Step — 1:
This is the first step in forward propagation. Here we are linearly transforming the input data.

Step — 2:
Since this is a binary classification problem, we are using the sigmoid function to generate the output. We will use the output from Step — 1 to generate the results. Here we are considering only one feature (x), and the weight associated with it is denoted by w.

Step — 3:
The mean squared error (MSE) is given by the following equation. Here, we are just considering a single example with only one feature.

Step — 4:
Next, we are going to find the first derivative of our cost function f(w) with respect to w. But, as we can see in Step — 3, our cost function f(w) is a function of ŷ. So, here we will use the chain rule.

Step — 5:
In this step, we are calculating the first part of the partial derivative.

Step — 6:
In this step, we are calculating the second part of the partial derivative.

Step — 7:
To calculate the second part of the partial derivative, we will use the formula we derived in the previous chapter.

Step — 8:
In this step, we are defining the value of p(w) for Step — 7.

Step — 9:
Here we are finding the partial derivative of p(w) to substitute in Step — 7.

Step — 10:
Next, we are calculating [p(w)]² to substitute in Step — 7.

Step — 11:
Here we are substituting the values of Step — 9 and Step — 10 into Step — 7.

Step — 12:
Next, we are just simplifying the equation we got in Step — 11. The simplification is shown in previous chapters.

Step — 13:
Next, we are substituting the values of Step — 5 and Step — 12 into Step — 4.

Step — 14:
In this step, we are simplifying the equation in Step — 13.

Step — 15:
Next, we are rearranging the terms from Step — 14.

Step — 16:
Now, let’s say the equation in Step — 15 is given by g(w).

Step — 17:
Next, we are going to find the partial derivative of g(w) with respect to w. Note that by doing so, we are finding the second derivative of the cost function f(w).

Step — 18:
Here we are calculating the first term of the partial derivative shown in Step — 16.

Step — 19:
Next, we are using the equation we derived in Step — 12.

Step — 20:
Next, we are substituting the values of Step — 17 and Step — 18 into Step — 16.

Step — 21:
Next, we are rearranging the terms in Step — 20.

Step — 22:
Now, our goal is to find out whether the equation shown in Step — 21 is > 0 for every value of x or not. If the answer is >0 for each value of x, then it is a convex function. But, if that is not the case, then it’s not a convex function.
Next, we are going to divide the equation in Step — 21 into three parts. Then we’ll check whether all three parts are >0 for all the values of x or not.

Step — 23:
We can clearly say that part — a of the equation is always going to be ≥0 for any value of x.

Step — 24:
Similarly, we can say that part — b of the equation is always going to be ≥0 for any value of x. Check the blog on Sigmoid function to have a clear understanding of this concept.


Step — 26:
Next, we need to find whether for all the values of x, part — c of the equation will be ≥0 or not.

Next, we need to find out whether the following term gives the value ≥0 for every value of x or not. If it is true then we can confidently say that the error function is convex.
Step — 27:
Here, we are just rearranging the terms of Step — 24.

Step — 28:
Now, we know that this is a binary classification problem. So, there can be only two possible values for y (0 or 1). Let’s first plug in y=0 and evaluate the equation in Step — 25.
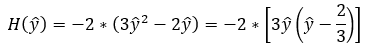
Here we can say that the output of the above equation is ≥0 only when ŷ is in the range of [0,2/3]. If the value of ŷ is in the range of (2/3,1], then the output of the above equation will be <0. So, based on that we can say that the above equation is not producing the value of ≥0 for every input of x.
Step — 29:
Next, let’s try and evaluate the equation in Step — 25 for y=1.

Step — 30:
Here we can say that the resultant value is ≥0 only when the value of ŷ is in the range of [1/3,1]. If the value of ŷ is in the range of [0,1/3] then the given function gives the value ≤0. So, we can say that the given function is not giving results ≥0 for all the values of x. Therefore, we can say that the given function is not convex.

Since the output value is not going to be ≥0 for every value of X, we can say that the Mean Squared Error function is not a convex function for logistic regression.
Important Note:
If the value of the second derivative of the function is 0, then there is a possibility that the function is neither concave nor convex. But, let’s not worry too much about it!
A Visual Look at MSE for Logistic Regression:
The Mean Squared Error function for logistic regression is given by…
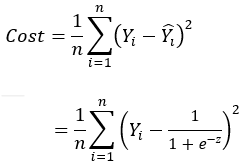
Now, we know that this is a binary classification problem. So, there can be only two possible values for Yi (0 or 1).
Step — 1:
The value of cost function when Yi=0.

Step — 2:
The value of the cost function when Yi=1.

Now, let’s consider only one training example.
Step — 3:
Now, let’s say we have only one training example. It means that n=1. So, the value of the cost function when Y=0,

Step — 4:
Now, let’s say we have only one training example. It means that n=1. So, the value of the cost function when Y=1,

Step — 5:
Now, let’s plot the graph of the function in Step — 3.

Step — 6:
Now, let’s plot the graph of the function in Step — 4.

Step — 7:
Let’s put the graphs in Step — 5 and Step — 6 together.

The above graphs do not follow the definition of the convex function (“A function of a single variable is called a convex function if no line segments joining two points on the graph lie below the graph at any point”). So, we can say that the function is not convex.
Conclusion:
In conclusion, we have explored the proof of non-convexity of mean squared error in logistic regression and its implications for model optimization. We have seen that despite the fact that the MSE function is convex for linear regression, it is non-convex for logistic regression, which can result in suboptimal or even misleading results. We have also discussed alternative loss functions that can be used in logistic regression to overcome these issues, including the cross-entropy loss and the hinge loss. As the field of machine learning continues to evolve, it is important to remain aware of the limitations and assumptions underlying our models, and to be open to exploring new approaches and techniques to improve their performance and reliability.

Citation:
For attribution in academic contexts, please cite this work as:
Shukla, et al., “Proving the Non-Convexity of the Mean Squared Error for Logistic Regression”, Towards AI, 2023
BibTex Citation:
@article{pratik_2023,
title={The Non-Convexity Debate in Machine Learning},
url={https://pub.towardsai.net/the-non-convexity-debate-in-machine-learning-e405687b17f6},
journal={Towards AI},
publisher={Towards AI Co.},
author={Pratik, Shukla},
editor={Binal, Dave},
year={2023},
month={Feb}
}
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


