



Segformer: An Efficient Transformers Design for Semantic Segmentation
Last Updated on July 17, 2023 by Editorial Team
Author(s): Albert Nguyen
Originally published on Towards AI.
Transformers have taken the machine-learning world by storm in the last few years. Their performances surpass state-of-the-art in Natural Language Processing tasks with the self-attention mechanism and even extend the dominance to Computer Vision.
The heart of Transformers is the self-attention mechanism. It allows making use of global features of the input. Vision Transformers have shown how Transformers can be used in Computer Vision with comparable results with other CNN architectures.
However, Vision Transformers are not resolution scalable. Their attention mechanism time complexity is quadratic to the size of the image, limiting Transformers’ performance on high-resolution photos, especially with tasks like semantic segmentation.
For example, Transformers often compute attention on a feature map of size (H/32, W/32, C) where H, W is the size of the image and C is the hidden channels. For (256, 256) image, the complexity for attention mechanism is O( (8*8*C)²)`. But when we double each side of the image, the complexity is O((16*16*C)²), which is 16 times more computations.
Segformers is an efficient design for Semantic Segmentation with Transformers. This article will explore how it avoids the costly computation of Transformers but still performs well.
How do Segformers work?
The design was first introduced by Enxie et al. in 2021. The goal is to have a simple, efficient, yet powerful semantic segmentation framework with Transformers and a lightweight MLP decoder. Some key points about Segformers:
- Not using positional encoding.
- Adapts an Efficient self-Attention mechanism from Pyramid Vision Transformers (PVT)
- A lightweight full-MLP decoder.
For ease of understanding, I will go through the Segformers’ architecture. First is the encoder, and then the decoder.

Encoder
Segformers encoder outputs feature maps from 4 different scales. For each scale, the feature map’s size is the input image’s size reduced by k=4, 8, 16, and 32, and we get four feature maps of size (H / k, W / k, C) where C is the embedded dimension. This is because Transformers, due to the self-attention mechanism, tend to learn local features in early layers and global features in later layers. Then, Segformers use these outputs to utilize local and global information in segmentation.
Each block of the Segformers is a sequence of smaller blocks that have:
- An Efficient self-attention layer
- A Mix-FFN (feed-forward network)
- An Overlapped Path merging layer.

Efficient Self-Attention (2nd key point)
This is the key to avoiding the costly computation of Transformers on image data. Segformers adopt the “sequence reduction process” proposed by Wang et al. 2021.

In the original self-attention mechanism of Vision Transformers, each head of the “multi-head attention” takes Q, K, V with the same dimension (N, C) where C is our embedding size, N = H * W is the length of the sequence. Then the following formula will have the complexity O(N²).
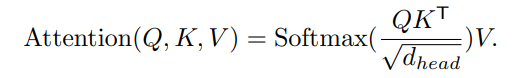
The SRA (the efficient Self-Attention) reduces this complexity by projecting K and V to lower dimensionality with a reduction ratio R. As a result, the time complexity for two matrix multiplications is reduced by R times. Hence, the time complexity is O(N² / R). The reduction is implemented by a Reshape and a Linear projection on K and V:

In practice, I find people using 2D Convolutional with kernel_size = stride = sqrt(R) on previous layers’ outputs (H/k, W/k, C). This reduces each size by sqrt(R) and the sequence’s size by R.
Mix-FFN (1st key point)
NLP Transformers need “Positional Encoding” to improve their performances by showing them where they are. Segformers say: “Hey, it’s something of a burden to me instead. And I’m going to remove it." Indeed, when Vision Transformers perform a task on image data, it receives “fixed positional information.” It is fine when the image size is the same as the trained image data.
“But what if it is bigger? Yes, the model will be lost”. The ‘positional information’ needs to be interpolated to match the bigger image and hence reduce the model’s accuracy.
But still, location information is important. So Segformers introduce Mix-FFN to remove Positional Encoding but still have location information.
Mix-FFN considers the effect of zero padding to leak location information, which is shown in the 4th section in How much position information do convolutional neural networks encode?
Formulated Mix-FFN:

Overlapped Patch Merging
Transformers and their Self-Attention mechanism are designed for NLP tasks. Its inputs are sequences of N-embedded vectors with embedded size C. Normal Vision Transformers need to divide images into separated patches to perform attention to images and then combine them again into feature maps.
Enxie argues that using overlapped patches merging helps preserve local information around those patches. This will improve the model receptive field for better segmentation.
Full-MLP Decoder (3rd key point)
Unlike other Vision Decoders using traditional CNNs, Segformer uses only MLP layers to avoid costly computation in generating segmentation maps. I don’t have much to talk about the decoder. I suggest readers to read the receptive field analysis in the paper to understand the power of this decoder.
According to the analysis, full-MLP has a larger receptive field by utilizing feature maps from four different scales. This results in better segmentations than traditional CNN-based decoders.
Conclusion
To sum up, Segformer is an efficient design for semantic segmentation on large-resolution images. It avoids the costly computations of traditional Vision Transformers with an efficient self-attention mechanism and a lightweight full-MLP decoder. Also, the proposed Mix-FFN to replace Positional Encoding allows Segformer to maintain its performance on larger images when trained on smaller images. The overlapped patch merging is also a key feature to help Segformer improves its segmentations quality.
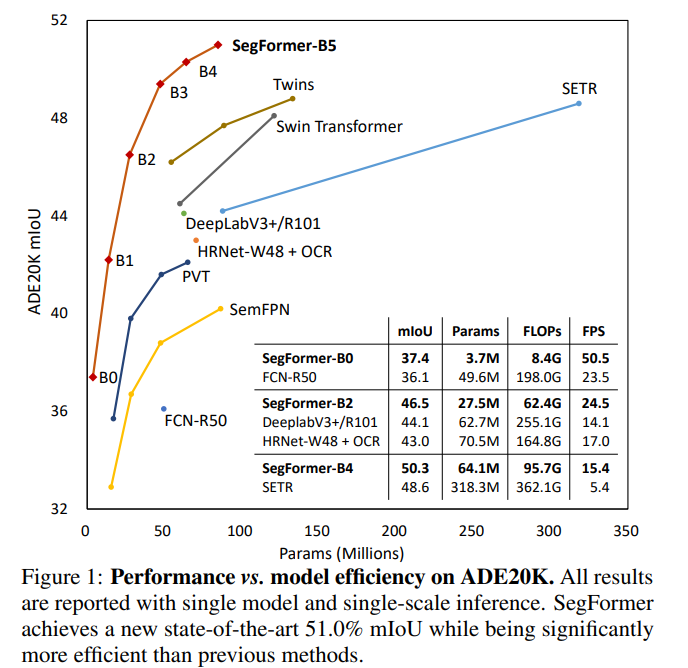
The figure above shows how Segformers results compare to other State-of-the-arts. There are 6 configurations of Segformers from b0 to b5, where b0 is the most lightweight, and b5 has the best segmentation quality.
Thank you!
Thank you for reading my blog. I hope this will be helpful. Some claps or comments will motivate me to write more and improve my writing.
I also have a Kaggle notebook to finetune the Segformer for the downstream tasks with Hugging Face packages. (Link to notebook) Hope this helps you to train your own Segformers.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

