


")
Reading: MegDet — A Large Mini-Batch Object Detector, 1st Place of COCO 2017 Detection Challenge (Object Detection)
Last Updated on July 20, 2023 by Editorial Team
Author(s): Sik-Ho Tsang
Originally published on Towards AI.
Computer Vision
Large Mini-Batch Size of 256 With Warmup Learning Rate Policy and Cross-GPU Batch Normalization, the training time is reduced From 33 hrs To 4 hrs
In this post, MegDet: A Large Mini-Batch Object Detector, by Peking University, and Tsinghua University, is briefly presented. In this paper:
- a Large Mini-Batch Object Detector (MegDet) is proposed to enable the training with a large mini-batch size up to 256 so that we can effectively utilize at most 128 GPUs to significantly shorten the training time.
- A warmup learning rate policy and Cross-GPU Batch Normalization are suggested, which together allow us to successfully train a large mini-batch detector in much less time (e.g., from 33 hours to 4 hours), and achieve even better accuracy.
- The MegDet is the backbone of our submission (mmAP 52.5%) to COCO 2017 Challenge, where we won the 1st place of Detection task.
This is a paper in 2018 CVPR with over 100 citations.
Outline
- A Warmup Learning Rate Policy
- Cross-GPU Batch Normalization (CGBN)
- Experimental Results
1. A Warmup Learning Rate Policy
1.1. General Object Detection Loss
- Generally, the object detection loss is:

- where N is the mini-batch size, l(x, w) is the task-specific loss, and l(w) is the regularization loss.
- l(xi, w) are RPN prediction loss, RPN bounding-box regression loss, prediction loss, and bounding box regression loss.
1.2. Variance Equivalence
- In image classification, every image has only one annotation and l(x, w) is a simple form of cross-entropy.
- As for object detection, every image has a different number of box annotations, resulting in different ground-truth distribution among images. The assumption of gradient equivalence between different mini-batch sizes might be less likely to behold in object detection.
- Different from the gradient equivalence assumption, we assume that the variance of gradient remains the same during k steps.
- For the gradient of each sample ∇l(xi, w), the variance of gradient on a normal mini-batch size l(x, w):

- Similarly, for the large mini-batch ^N = k×N:
Here we want to maintain the variance of one update in large minibatch ^N equal to k accumulative steps in small mini-batch N.
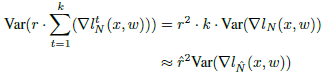
- The above equality holds if and only if ^r = k×r, which gives the same linear scaling rule for ^r.
- After the above derivation, though the final scaling rule is actually the same as the image classification one, a new explanation is given.
1.3. Warmup Strategy
- Linear Gradual Warmup from another tech report in arXiv: Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour, is used.
- That is, the learning rate is set up to small enough at the beginning, such as r. Then, the learning rate is increased with a constant speed after every iteration, until to ^r.
2. Cross-GPU Batch Normalization

- For object detection, a detector needs to handle objects of various scales, thus higher resolution images are needed as its input.
- For input of size 800×800 is used, the number of possible samples on one device is significantly limited.
- Thus, batch normalization should be performed crossing multiple GPUs to collect sufficient statistics from more samples.
- Given n GPU devices in total, sum value sk is first computed based on the training examples assigned to the device k.
- By averaging the sum values from all devices, we obtain the mean value μβ for the current mini-batch. This step requires an AllReduce operation.
- The variance for each device is calculated and get σ²β.
- After broadcasting σ²β to each device, we can perform the standard normalization by:

- NVIDIA Collective Communication Library (NCCL) is used to efficiently perform AllReduce operation for receiving and broadcasting.
3. Experimental Results
- COCO Detection Dataset is used, which is split into train, validation, and test, containing 80 categories and over 250,000 images.
- Over 118,000 training images are used for training and 5000 validation images are used for evaluation.
- ImageNet pre-trained ResNet-50 is used as the backbone network.
- Feature Pyramid Network (FPN) is used as the detection framework.
3.1. Large Mini-Batch Size, No BN

- For mini-batch sizes 32, the training already starts to have some chances to fail, even using the warmup strategy.
- And there is no loss of accuracy, compared with the baseline using 16.
- For mini-batch size 64, the training cannot be converged even with the warmup. Lowering the learning rate by half can make the training to converge. But there is noticeable accuracy loss.
- For mini-batch size 128, the training failed with both warmup and half learning rate.
- The training is harder or even impossible when the mini-batch size and learning rate are larger, even with the warmup strategy.
3.2. Large Mini-Batch Size, with CGBN

- Within the growth of the mini-batch size, the accuracy almost remains at the same level, which is consistently better than the baseline (16-base).
- A larger mini-batch size always leads to a shorter training cycle. For instance, the 256 mini-batch experiment with 128 GPUs finishes the COCO training only in 4.1 hours, which means an 8× acceleration compared to the 33.2 hours baseline.
- The best BN size (number of images for BN statistics) is 32. With too few images, e.g. 2, 4, or 8, the BN statistics are very inaccurate, thus resulting in a worse performance.
- However, when it is increased to 64, the accuracy drops. This demonstrates the mismatch between image classification and object detection tasks.
- A long training policy is also tried. Longer training time slightly boots the accuracy.
- For example, “32 (long)” is better than its counterpart (37.8 v.s. 37.3).
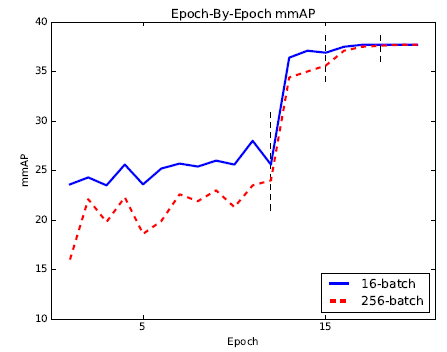
- 256 (long) is worse at early epochs but catches up 16 (long) at the last stage (after second learning rate decay).
3.3. COCO Detection Challenge

- The proposed MegDet integrates multiple techniques including OHEM [35], atrous convolution (DilatedNet, DeepLabv1 & DeepLabv2) [40, 2], stronger base models (ResNeXt, SENet) [38, 18], large kernel (GCN) [28], segmentation supervision [27, 34], diverse network structure (Maxout, Inception-v4) [12, 32, 36], contextual modules [22, 9], ROIAlign (Mask R-CNN) [14] and multi-scale training and testing for COCO 2017 Object Detection Challenge. (Please read those references’ stories or papers if interested. Some I haven’t covered, it’s too many…)
- 50.5 mmAP is obtained on the validation set, and 50.6 mmAP is obtained on the test-dev.
- The ensemble of four detectors finally achieved 52.5 mmAP. The above table summarizes the entries from the leaderboard of COCO 2017 Challenge.
- The below figure gives some exemplar results.

During the days of coronavirus, Challenges of writing 30 and 35 stories again for this month have been accomplished. Let me challenge 40 stories!! This is the 36th story in this month.. Thanks for visiting my story..
References
[2018 CVPR] [MegDet]
Paper: MegDet: A Large Mini-Batch Object Detector
Object Detection
[OverFeat] [R-CNN] [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net] [CRAFT] [R-FCN] [ION] [MultiPathNet] [NoC] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [G-RMI] [TDM] [SSD] [DSSD] [YOLOv1] [YOLOv2 / YOLO9000] [YOLOv3] [FPN] [RetinaNet] [DCN / DCNv1] [Cascade R-CNN] [MegDet] [DCNv2]
My Other Previous Readings
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

