



Python Prior Machine Learning Part 2 & Data Analysis
Last Updated on January 6, 2023 by Editorial Team
Last Updated on July 16, 2022 by Editorial Team
Author(s): Gencay I.
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Machine Learning Prior Part 2 & Data Analysis
Data Frame Analysis with Python
Content Table
· Introduction
∘ Installation
· How to gather your data?
∘ Example
· How long your data frame is? What are the column data types? How can I look at a little bit of my data?
∘ Info
∘ Shape
∘ Sample
∘ Head
∘ Tail
∘ Describe
∘ Value Counts
· How to select your pre-defined row?
· How to select multiple columns?
∘ First Two Columns
∘ Select Columns with Name
∘ Select Column with their Indexes
· How can I sort the values?
· How can I look at the mean/standard deviation/max of one column per its categories?
· How can I drop the NA Values?
· Conclusion
Introduction
Hi from another Machine Learning Tutorial. I want to explain this to you guys briefly here and really think about that, how can I explain it really briefly? Reading too many articles may have helped me. I want to explain to you guys the pandas library with questions and their answers.
Installation
Now let's begin with the installation process.
Here is the main page of the panda's library.
Pip or conda, this will depend on your set-up.
pip install pandas
conda install pandas
Now it's time to import your package.
import pandas as pd
How to gather your data?
Now it is time to download your Data.
CSV is mostly used file type when you will deal with pandas.
url = " "
col =
df = pd.read_csv(“”)
- The URL you will download your data.
- The column you want to select to see.
- Define your data frame as df.
Here is the documentation of this method, and you can see the following codes.
Example
Now let's look up real-life examples.
Iris data set is really famous one, you can download it by using the sklearn datasets module or seaborn or via URL.
This is perhaps the best known database to be found in the pattern recognition literature. Fisher’s paper is a classic in the field and is referenced frequently to this day. (See Duda & Hart, for example.) The data set contains 3 classes of 50 instances each, where each class refers to a type of iris plant. One class is linearly separable from the other 2; the latter are NOT linearly separable from each other.
Predicted attribute: class of iris plant.
Here are the remaining details of this Dataset.
Now, let's implement our codes in that Dataset;

How long your data frame is? What are the column data types? How can I look at a little bit of my data?
Info
It will give your column data types.
df.info()
Your column data types.

Shape
It will give the dimension from your Dataframe.
df.shape()
Shape of your df.

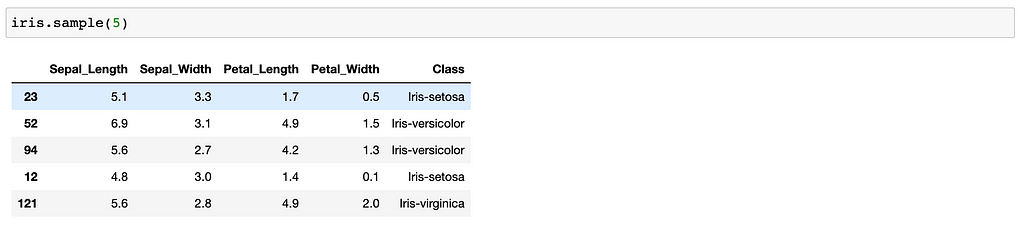
Sample
It will give “n” random samples from your Dataframe.
df.sample(5)
5 random samples of your df
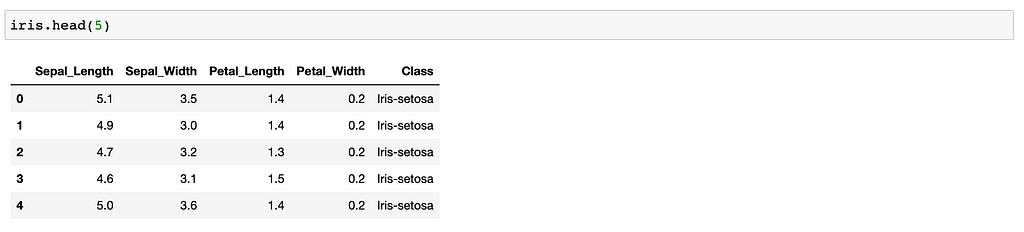
Head
Looking first “n” rows of your Data frame.
df.head(5)
Looking first 5 rows of your df.
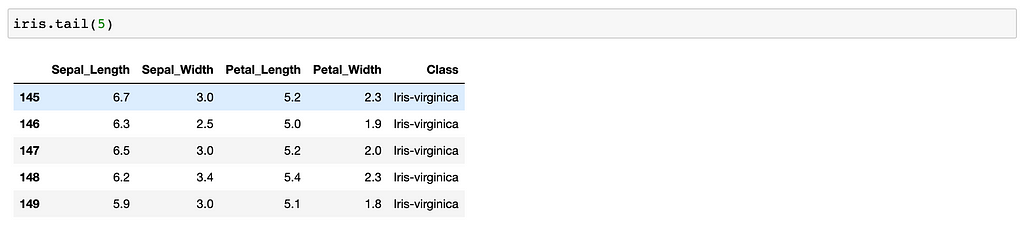
Tail
Looking at the last “n” rows of your Data frame.
df.tail(5)
Looking last 5 rows of your df.
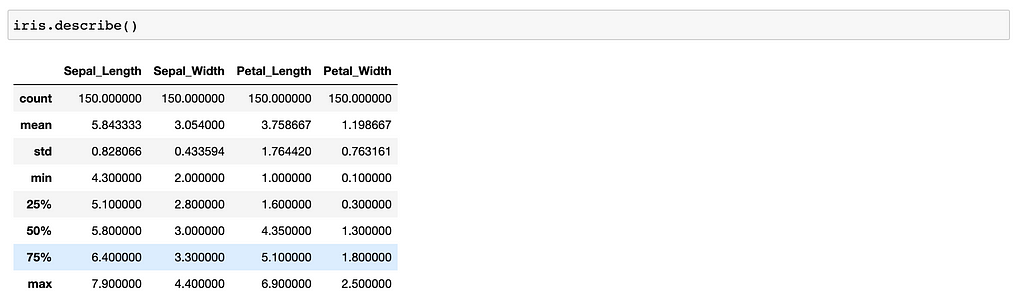
Describe
Shows a summary of numerical features.
df.describe()
Shows a summary of a numerical features.
Value Counts
Looking at your categorical column types.
df["Column"].value_counts()
Looking this values data types.

How to select your pre-defined row?
By using the loc method.
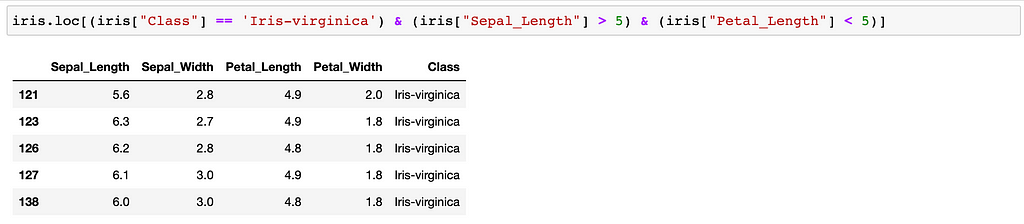
Now you want to see Iris-virginica class and Iris-virginica class only.
In addition to that, if you want your sepal length to be bigger than five and petal length to be smaller than five, then your code will be like that;
How to select multiple columns?
First Two Columns
Now first “:” means all rows, and 0:2 means start from the first column, end from the third column but do not select the third one.

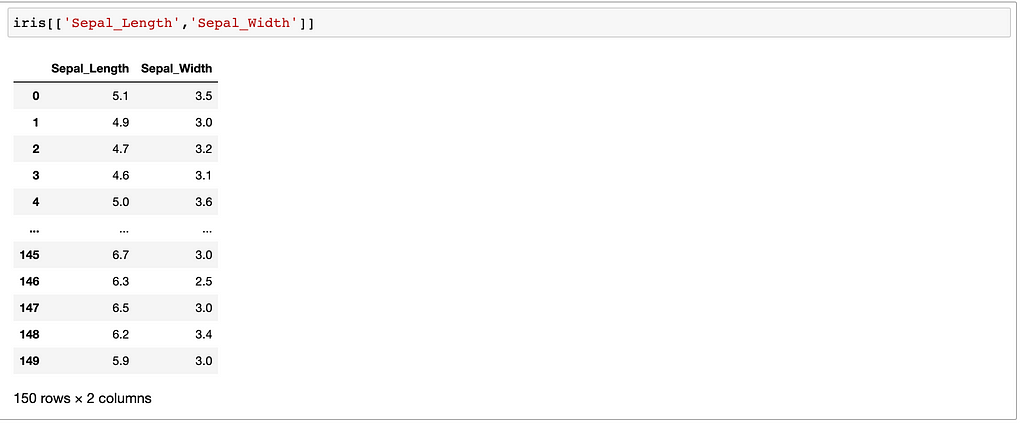
Select Columns with Name
By using two brackets.
Select Column with their Indexes
Selecting the first and third columns by using the index method;

How can I sort the values?
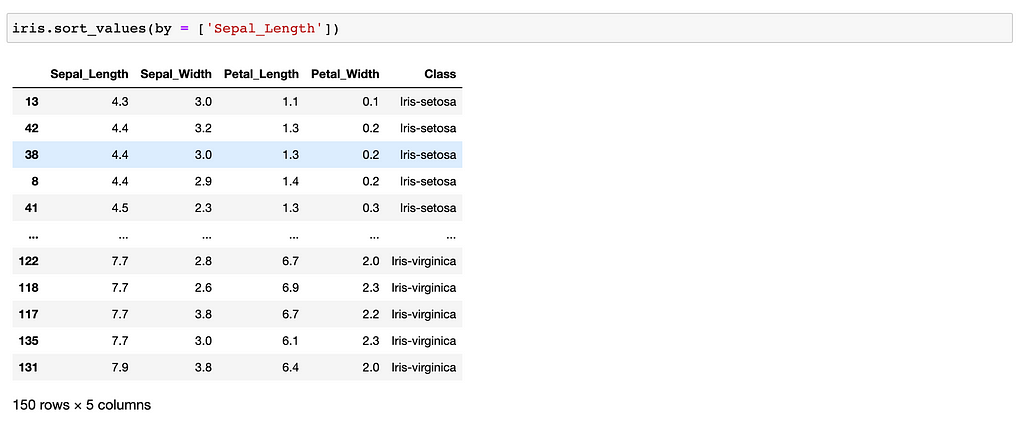
- by = The column you want to sort
If you want that order to be different, then you should add the following argument:
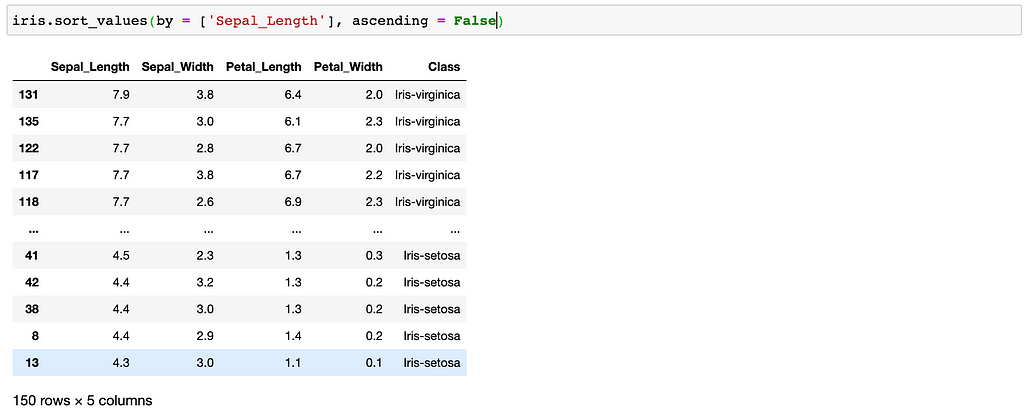
For more, visit here
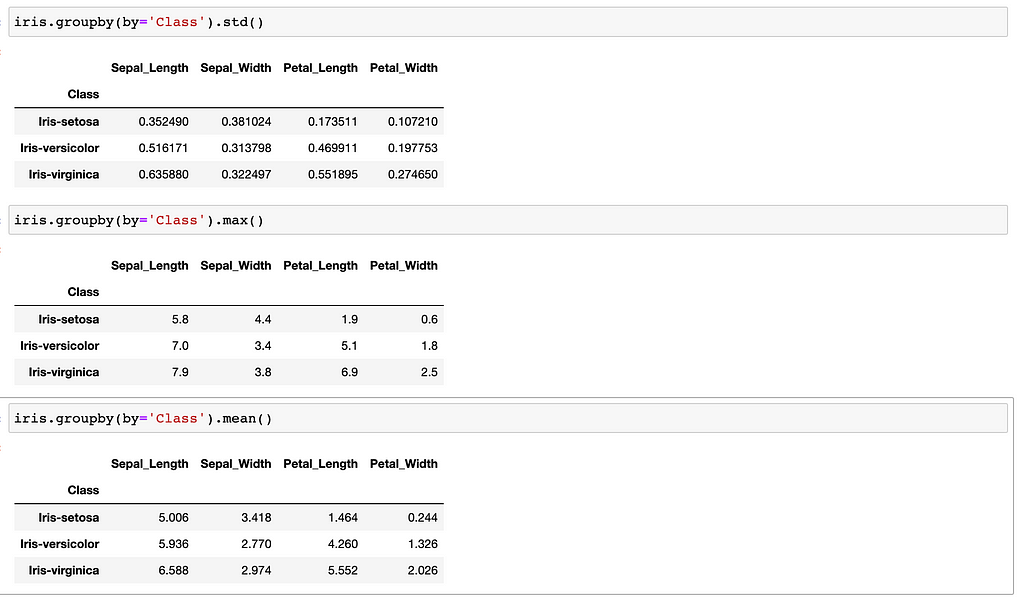
How can I look at the mean/standard deviation/max of one column per its categories?
Now, if you want to be a good programmer, you should start reading documents today.
Here is the explanation;
A group by operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
You can look up the arguments of this method, visit here and start reading documents from this library.
How can I drop the NA Values?
Now there are too many approaches to do that.
You can fill the mean of the column to the NA Values if your dataset is small and you do not want to lose your data.
df.dropna()
Now, I can not give a real-life explanation to you because my dataset does not contain NA values, however, as I mentioned earlier, it will be good for you to read library documents.
Here you can find other examples here, official document.
Conclusion
I try to be brief as much as I can.
Although there are too many other methods that may have helped you along the machine learning journey, I think this prior knowledge would be okay to launch your first Machine Learning Model.
In addition to all of these, thank you for your support of my previous articles, your reactions really motivate me to keep writing tutorials and articles.
If you want to be noticed in my upcoming articles via e-mail, here ;
Get an email whenever Gencay I. publishes.
I actually mentioned to you guys before about my preparation for E-Book, in this one, I will plan to explain to you guys all concepts in detail, not briefly this time, and with real-life explanations and datasets.
Machine learning is the last invention that humanity will ever need to make.” Nick Bostrom
Thanks.
Python Prior Machine Learning Part 2 & Data Analysis was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

