


Probability theory: Explaining prediction of uncertainty
Last Updated on June 28, 2023 by Editorial Team
Author(s): Abhijith S Babu
Originally published on Towards AI.
Our future, as we all know, is uncertain. Using the techniques available right now, it is nearly impossible to predict the future. But we still make plans for the future, assuming things will go in a certain way. But how can we make that assumption? Humans have limited knowledge about many things happening around us. To predict the outcome of an action without complete knowledge about the thing is not possible. But we can still make some assumptions based on the available amount of knowledge. This assumption is based on probability.
Probability is the measure of the uncertainty of an event, i.e., it measures the likeliness of an uncertain event to happen. Using probability theories, we can make predictions about the future from the limited information that we have.
The whole probability theory starts from the basic equation of probability. To calculate the probability of an event x, P(x), we use the formula.
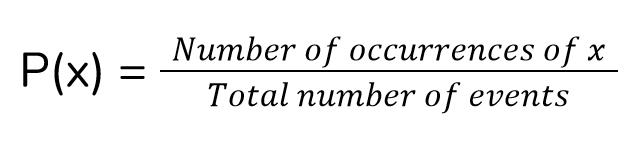
One thing to note is that to use this formula, all the events should have equal probability.
From this simple equation, we can derive a lot of results in probability theory.
Conditional probability
Conditional probability deals with two or more events that depend on each other. Let us take a simple situation. There are two classrooms, class-X, and class-Y. Class-X has 10 boys and 20 girls, and class-Y has 30 boys and 15 girls. The headmaster wants to choose a random student from these for a task. We have to find the probability of whether he chooses a boy or a girl.
Let us find the probability that he chose a boy. There are a total of 40 boys out of 75 students. So the probability of choosing a boy is 40/75. Let us use the notation:
XB — Number of boys in X
XG — Number of girls in X
YB — Number of boys in Y
YG — Number of girls in Y
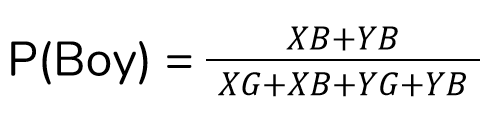
Let us have a look at three different equations. Firstly, what is the probability that the headmaster chose a boy from class-X?
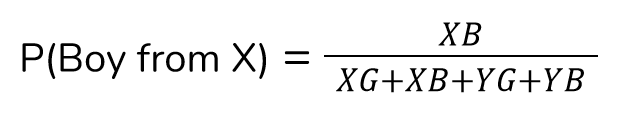
Now, when a random student is chosen, what is the probability that he/she is from class-X?
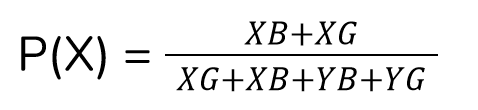
Now, the headmaster decided to take a student from class-X itself. Now, the probability of choosing a boy given class-X is chosen, denoted by P(BU+007CX), changes to
here we notice that if we multiply the last two equations, we get the first equation P(Boy from X) = P(X) x P(BU+007CX) This is called the product rule in probability theory.
The product rule states that the probability of two events happening together is the product of the probability of one event and the probability of the second event given the first event.
Here we want to find the probability of two things happening together, the student should be a boy and he should be from class X. We see that there is no ordering between the two of them. So the equation is symmetric.
P(X) * P(BU+007CX) can also be written as P(B) * P(XU+007CB). We can use this to find P(XU+007CB)
This is called Baye’s theorem. Here P(XU+007CB) is the probability that a student is chosen from class X, given that the chosen student is a boy.
In the above example, the whole process of choosing a boy was broken down into a situation where class-X is chosen. The process actually comprises two situations, choosing class-X and choosing class-Y.
We can find the probability of choosing a boy from class-Y
Now adding both of them, we can get the probability of choosing a boy. This is called the sum rule.
The sum rule states that the probability of an event is the sum of the probabilities of the event occurring after each of the possible situations.
Using these two rules, we can derive the complex theorems in probability.
So far, we have found the probabilities of discrete variables. What if the variable is continuous? Suppose you are throwing a stone in an empty ground, the stone can reach the distance x. What is the probability that it will reach 53.48 meters? Here distance x is a continuous value. We can define a function of x that gives the probability. This function is called the probability density function. This function has some properties. It can only output a value in [0,1]. If we want to find the probability of x being in between two values, say a and b, we can integrate the function from a to b. If we integrate the function from negative infinity to positive infinity, we will always get 1.
This concept gets a bit complicated when we do a transformation on the variable. Here the variable x is the distance covered by the stone. Instead, if we took y, the maximum height obtained by the stone, we can write x in terms of y, using a relationship between x and y, say x = g(y). Now the density function f(x) can be written as a new function f(g(y)) = h(y). These two functions correspond to each other and we can say that the small change in f(x) is comparable to a small change in h(y). This can be written as

The cases we have seen so far are classical probability problems, which can be solved using the above equations. What about the distance traveled by the stone? The probability of getting a particular range of distance can be found by counting the number of times we get a favorable output by repeating the experiment (while other conditions remain constant). The more we do the experiment, more we get close to the actual probability.
Now, consider this. What is the probability that Australia will win a cricket world cup in 2075? It depends on a lot of complex factors, which we don’t have an idea about. Repeatedly trying it out is also not possible. In such cases, how can we find the probability of an event happening? This is a case of uncertainty and it was earlier considered as an extension to boolean logic, for situations that involved uncertainty. By numerically quantifying the factors affecting an event, rules of probability were followed. This type of probability is called Bayesian probability.
In machine learning, the basic aim of the supervised learning algorithm is to find the weights. The weights are estimated from the input data we receive. We can use Bayesian probability to find the actual values of the weights. Before going into that, consider the school student example mentioned earlier. In that, the probability of the chosen student being from class X was 0.4. But if it was given that the student is a boy, then the probability of him being from class X is 0.25. Here we can see that the probability of a class has some relation to the gender of the student and it changes when we get some additional information. Similarly, in the case of machine learning, the weights are dependent on data and we can use our knowledge of data to change the weights according to Baye’s theorem.
In this equation, P(DU+007Cw) is the probability of getting the actual output with the given weights. This term is called the likelihood of getting D from w. It is conventional to choose the w that maximizes the likelihood of D. But this has a problem.
The likelihood of an event is found by repeated experimentation. Suppose we want to find the probability of getting a head while tossing a coin. We tossed the coin 3 times and all the 3 times it landed on Heads. If the probability of getting a head is p, then the likelihood that the result we got is Heads is p³. To maximize this function, p should have the largest possible value, which is 1 (since p is a probability). But we know that the probability of getting a head is definitely not 1. If we used some prior information, we could have prevented this. Bayesian probability uses prior information to solve this problem. In the above equation, P(w) and P(D) incorporates the prior known values into the probability function.
Machine learning problems can be solved by Bayesian probability using a concept called Bayesian networks. Conditional probability is also used in other such applications to make accurate predictions. These topics will be discussed in upcoming articles. Follow me to get more articles on such topics. Give your suggestions as a response and they will be considered in the upcoming articles. Happy reading!!!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

