



Improving Text-to-Image Models by Prompt Engineering with RLHF
Last Updated on August 1, 2023 by Editorial Team
Author(s): Nikita Pavlichenko
Originally published on Towards AI.
Text-to-image models like Stable Diffusion, DALL-E 2, and Midjourney can generate impressive, artistic images — if you’re good at prompt engineering.
However, many users simply want to generate aesthetically pleasing images to include in blog posts, presentations, and other materials. So, what about the rest of us who haven’t had the opportunity to learn all the magical keywords, such as “trending on Artstation,” and understand how they function in various contexts?
The Toloka team saw this gap and developed a solution to turn anyone into a prompt engineer. We trained a model to transform simple image descriptions into professional prompts for Stable Diffusion with consistently good results.
But we wanted our model to do more than just generate prompts — we wanted to get beautiful prompts that would elicit the most aesthetically pleasing images. To accomplish this, we integrated human preferences by using reinforcement learning from human feedback.
In this post, we share the technical details and results of our experiments. We have released our code and data, allowing anyone to replicate our approach or apply it to other text-to-image models with API access. You can also use this post as a practical Reinforcement Learning from Human Feedback (RLHF) tutorial to walk you through the steps from data collection to model training.
We release all the models, code, and data.
Approach
Our task is defined as follows: the model takes a human-readable image description, such as “a cat,” and generates a high-quality prompt, such as “a cat, trending on Artstation, 4k resolution, cinematic lighting.” This task is relatively simple (definitely not ChatGPT training), so we chose a small yet powerful enough model — GPT-2 Large. This model has 774M parameters and can be fine-tuned on a single GPU in a couple of hours.
So, the model takes the following text as input:
image_description[SEP]
We instructed the model to write a prompt after the [SEP] token since it is an autoregressive language model rather than a seq2seq model.
Overview of Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF) is a technique that allows us to switch from training on an unlabeled text corpus into training to produce human-preferred outputs. This technique has been widely used in the NLP community since it was applied to InstructGPT and ChatGPT.

According to the ChatGPT blog post, the RLHF pipeline includes three key parts:
- Supervised Fine-Tuning (SFT)
- Reward/preference Modeling (RM)
- Reinforcement Learning from Human Feedback (RLHF)
You can check out the Hugging Face article about StackLLaMA that inspired our post.
Step 1: Supervised Fine-Tuning
During supervised fine-tuning (SFT), we provide the model with demonstration data to guide its behavior. At this stage, the model is not required to optimize for human preferences. The aim is to learn the desired response format and relevant information contained in the demonstration data. To accomplish this, we collected an unlabeled dataset of text in the desired format, which, in our case, was “image_description[SEP]prompt”. We then trained the model on this dataset using a standard language modeling task.
We faced a challenge when we set out to collect the data because there were no publicly available datasets containing image descriptions and prompts constructed from them. We considered two options.
First, we could collect a dataset of image descriptions and then create prompts from them. The problem is that it’s not clear how to find image descriptions beyond just a list of objects, and we would need annotators who are experienced at writing prompts for Stable Diffusion, which is a difficult skill to find.
The second option was to find a dataset of prompts and then extract image descriptions from them, essentially capturing the user’s intended meaning. This is much easier than the first option because there are open datasets containing Stable Diffusion prompts. We opted to use prompts from Stable Diffusion Discord bots, where users send their prompts and receive a generated image from a bot.
Once we had a dataset of prompts, we needed to extract image descriptions from them. We accomplished this by employing the OpenAI API and asking the text-davinci-003 model to extract image descriptions through few-shot learning.
We were now ready to begin training the model. To do this, we chose to use a standard example script for LM fine-tuning from HuggingFace Transformers. However, we made several modifications to the script, the most significant of which involved calculating the loss only on prompts, rather than image descriptions. Prior to this change, the model produced severe artifacts, such as starting each generated prompt with the word “ilya.”

The training process takes around 90 minutes to complete on a single NVIDIA A100 80GB GPU.
Step 2: Reward Modeling
Reward modeling (RM) consists of two steps: preference collection and reward modeling itself. During preference collection, we generate several outputs of our model, show them to annotators, and ask them which one they prefer. During reward modeling, we train a model to predict these preferences: the reward model takes a generative model’s output and returns a single value representing how good this output is.
Preference Collection
To gather human preferences, we take each image description and generate three prompts for it. This means that for each image description, we have a total of four prompts, including the original one. For each prompt, we then generate four images using Stable Diffusion 1.5. We then sample pairs of prompts within each image description, take the generated images, and use the Toloka crowdsourcing platform to annotate these pairwise comparisons.
In the comparison task, annotators are presented with an image description, four images on the left, and four images on the right. They choose which set of images (left or right) looks better.

We used this process to collect a dataset containing 135,400 preferences for 3,919 prompts. A complete guide for running this annotation process can be found on our GitHub.
Reward Modeling
We opted to use a distilroberta-base as our reward model due to its fast training speed and performance similar to other BERT-like models and GPT-2 Large, with a scalar prediction head. This model is designed to take a text input in the form of “image description[SEP]prompt” and predict a single number. To implement this, we used AutoModelForSequenceClassification from Transformers and set num_labels=1. However, the training procedure differs from fine-tuning for text classification. We iterated through pairs of prompts for a single image description and predicted two numbers: r̂(a)and r̂(b), for the left and right prompts, respectively. The predicted probability of the left prompt being better than the right prompt is calculated as
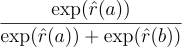
We used a binary cross-entropy loss function where the target is the comparison’s result: 1 if the left prompt is better than the right prompt and 0 otherwise.
The training process takes approximately 15 minutes on a single NVIDIA A100 80GB. The resulting model achieves an accuracy of 0.63 on the validation set. While this accuracy may appear low, it is adequate for RLHF fine-tuning. This is because the task is subjective and even human annotators may disagree with each other.

We released the reward model weights on HuggingFace Hub.
Step 3: Reinforcement Learning from Human Feedback
The final step involves training the fine-tuned GPT-2 Large model to maximize the rewards predicted by the reward model. We used the PPO implementation provided by Carper AI’s trlx library, which is a convenient package for fine-tuning any language model with RL on any reward function.
We faced challenges during the hyper-parameter sweep, as the training process is very sensitive to specific hyper-parameter values, particularly the learning rate and init_kl. We found that low values of these parameters worked best.
It is important to note that both value and policy losses should remain below 1.0 at all times. If one or both losses significantly increase, it indicates that something has gone wrong. We observed the same behavior as described in the StackLLaMA blog post, where the policy loss can sometimes experience extreme spikes.
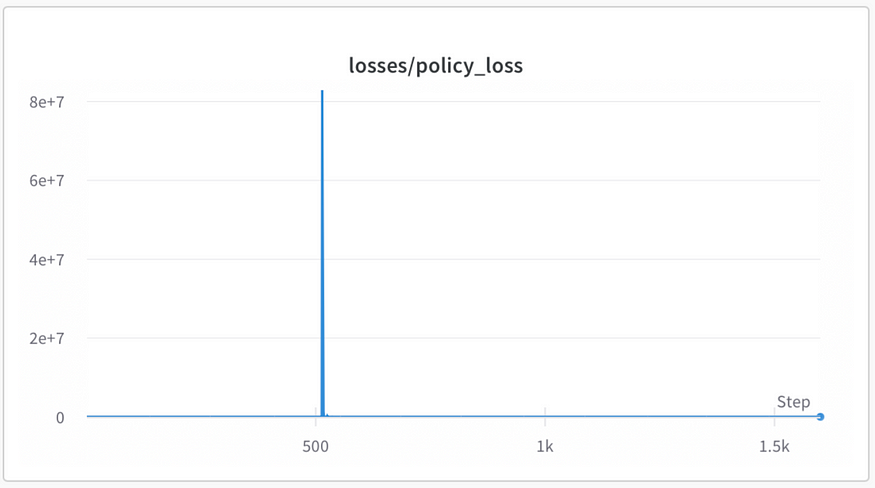
In our experiments, the value loss consistently decreased, which is a positive sign.
The reward model’s predicted reward significantly increased during the training process. However, this does not necessarily mean that the model is perfect or even improving, as the reward model itself may have imperfections that PPO could exploit.

Visual Results
Here are some examples of simple prompts and the results generated by Stable Diffusion via our model.



All images in this article were generated by the author using Stable Diffusion 1.5 unless stated otherwise.
What’s next
We have made all the code and data available for the open-source community to build upon our results and create similar solutions for other models like DALL-E 2 and Midjourney.
In the meantime, you can experiment with our model on Hugging Face Hub and in our Space.
We welcome your feedback!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



