



Performance Analysis: YoloV5 vs YoloR
Last Updated on December 28, 2021 by Editorial Team
Author(s): Dhruv Gangwani
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Deep Learning
Object detection, Which one is the best ??
Table of Content
- Introduction
- YoloV5: Real or Fake??
- YoloR: You Only Look One Representation
- Performance Analysis
- Use Cases
Introduction
Object detection is the process of identifying and distinguishing objects present in an image over several predefined categories. The process of object detection is divided into two steps:
- Find the total number of objects in the image
- Classify the objects extracted in the first step and estimate their size
There are typically two types of object detection algorithms:
- Two-stage object detection: It involves object region proposal followed by object classification from region proposal and bounding box regression. This kind of detector achieves the highest accuracy but is slower as compared to other types of detectors. Some of such object detectors are RCNN, Faster-RCNN, and Mask RCNN.
- One-stage object detection: It predicts the bounding box from images and eliminates the step of object region proposal step. Such detectors are very fast as compared to two-stage detectors but find difficulties in detecting small objects. Fast inference speed makes one-stage detectors eligible for real-time applications. Some of such detectors are YOLO, SSD, and YoloR.
After learning about different types of object detectors, the question arises:
“Which one is the best ??”
It is very confusing to choose one algorithm out of so many. The decision relies on many factors and differs for every use case. Some applications may need more inference speed while some needs accurate detection. One should choose the one-stage detectors for the first case while the two-stage detectors for the latter one. But still, which one is best from the respective categories. To test the same, I conducted the performance analysis of two one-stage object detectors namely YoloV5 and YoloR.
YoloV5: Real or Fake ??
The release of YoloV5 by Ultralytics in 2020 was itself a big controversy. The first three versions of Yolo were published by Joseph Redmon and Ali Farhadi. Later, Joseph discontinued the computer vision research. Then, YoloV4 was introduced by Alexey Bochkovskiy who continued the legacy of Joseph Redmon. The first four versions of Yolo were published with peer-reviewed research papers which was not the same case with YoloV5. Ultralytics claimed that the YoloV5 has an inference speed of 140 FPS whereas the YoloV4 had the same of 50 FPS. They also claimed that the size of YoloV5 was about 90 percent less than that of YoloV4.
Alexey Bochkovskiy and several other AI researchers claimed it to be misleading as YoloV5 does not have any supporting documents and they stated the comparisons to be inaccurate. Later, Glenn Jocher, CEO and Founder of Ultralytics, stated that he and his team will soon publish the research paper to support YoloV5 which is yet to be done.
YoloR: You Only Look One Representation
YoloR was published in early 2021 by Chien-Yao Wang, I-Hau The, and Hong-Yuan Mark Liao. It is basically the concept of combining implicit and explicit knowledge. Humans gain explicit knowledge through vision, hearing, and experience, while implicit knowledge is gained from past experience and subconscious learning. As the name says, YoloR is developed to perform several tasks using one representation of the image. YoloR object detection gains explicit knowledge from the deep layer and implicit knowledge from shallow layers. The architecture combines both the representation to form one representation which can further be used to serve various tasks.
Performance Analysis
This is the performance analysis of YoloV5 (You Only Look Once) and YoloR (You Only Look One Representation). Both the models were trained on the same dataset with the same hyper-parameters.
Dataset
The dataset comprises blood-cell images originally open-sourced by cosmicad and akshaylambda. There are 364 images across three classes namely Red-blood cells, white blood cells, and platelets. There are around 4888 labels across three classes.
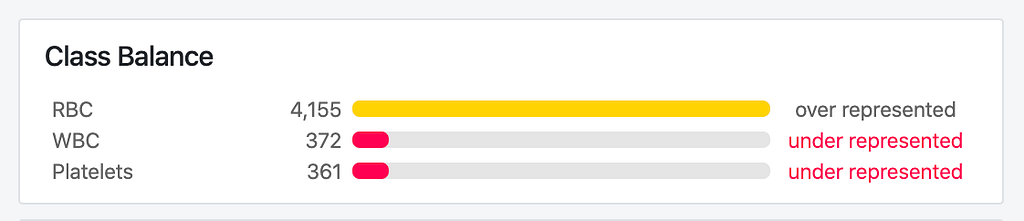
Hyperparameters
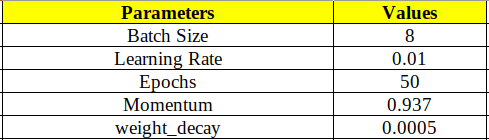
As mentioned below, Very few hyper-parameters were taken into account for both models.
Metrics
Mean Average Precision is the metric on which the performance of both models was evaluated. The first one is the MAP with 0.5 as the IOU threshold. Whereas, the second one is the average of MAPs with an IOU threshold varying from 0.5 to 0.95 with the step of 0.05.
It is very clear that both the models have performed equally well on the validation dataset. The Google collab GPU was used during training: Nvidia k80 with 12GB memory.

Analysis
YoloV5: Better performance on test dataset though having almost same MAP as YoloR
YoloR: Inference has more traits of False Negatives
Use Cases
In recent years, object detection has broken down into several useful use-cases for enterprises. Some of them are:
- Self-driving Car: To detect other vehicles and pedestrians on street and compute the distance between the car and other objects. Also, to detect the signboards on street to make sure that the self-driving bot is not breaking any driving rules.
- CCTV Surveillance: Object detection can enable smart video surveillance to detect suspicious activity without any human involvement. Also, memory is a big issue when it comes to storing continuous recording of CCTV cameras. This also can be resolved by object detection where recording is started when any human comes in the frame.
- Medical Science: Object detection helped the human race a lot, in times of the covid pandemic. Several industries adopted the mechanism to detect whether or not visitors are wearing masks and are at a safe distance from each other.
- Listing in brands: Companies pay a bomb to display their brand name and logo in an on-air sports match. In this case, object detection is used to analyze the timelines of the match during which brand name and logos were displayed to the audience.
Training Scripts and Inference Outputs can be found here
GitHub – DhruvGangwani/YoloV5_vs_YoloR
Thank you.
Performance Analysis: YoloV5 vs YoloR was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



