



Overfitting: Causes and Remedies
Last Updated on August 2, 2022 by Editorial Team
Author(s): Akash Dawari
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
In this article, we will understand the concept of overfitting with respect to the machine learning domain by answering the following question
- What are Bias and Variance?
- What is Overfitting?
- What are the reasons for Overfitting?
- How we can solve the problem of overfitting?
What are Bias and Variance?
Bias:
Bias is the measurement of the inability of a model to capture the true relationship between the dependent and independent variables. In more simple words, bias is the difference between our actual and predicted values.
High Bias: This means when the model is unable to capture the relevant relations between dependent and independent variables, which causes poor prediction results on training data itself.
Low Bais: This means when the model incorporates fewer assumptions about the dependent variable. In simple words, when the model is cramping the training data.
Variance:
Variance is the measurement of how much the estimate of the target function will alter if different data points. Variance is the very opposite of Bias.
High Variance: This means the model is performing well during the training data as it has seen the dependent variable, but when we introduce new data points, the model is underperforming.
Low Variance: This means the model is performing well when we introduce new data points, as the model may use a more generalized predictive function to predict.
As we understand bias and variance, ideally, for a good machine learning model, we would like to achieve low bias and low variance. But this is way more difficult to achieve as there is a trade-off between bias and variance.
The trade-Off between bias and variance:
The relationship between bias and variance is inversely proportional means when we try to decrease the bias, variance will automatically increase and vice versa. This phenomenon causes two major problems the first is underfitting, and the second is overfitting which is the major topic of this article.
What is Overfitting?
Overfitting is a problem, or you can say a challenge we face during the training of the model. This happens when the model is giving very low bias and very high variance. Let's understand in more simple words, overfitting happens when our model cramps the training data so well that it gets trained over the noise and inaccurate data entries in our data set as well, which give high accuracy and low loss over the training data set (ideal case of Low Bias). And when we introduce the same model with new test data, it results in very poor accuracy and very high loss(ideal case of High Variance).
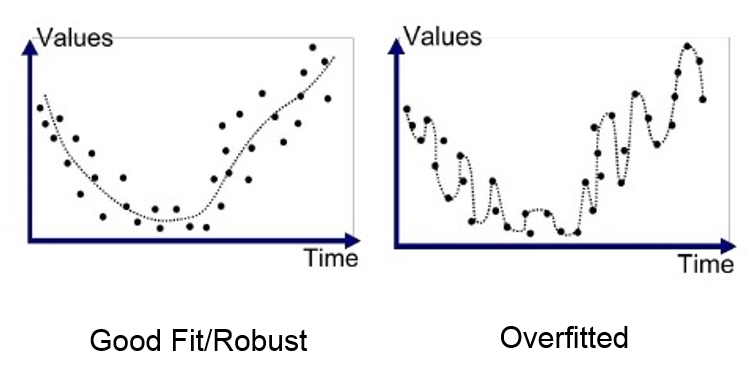
Overfitting is not good for any machine learning model as the final aim of the machine is to predict new upcoming scenarios which nobody has seen before. But overfitting causes the model to predict very poorly on new data points. So, we have to understand the causes that make the model overfits the training data.
What are the reasons for Overfitting?
1. Noisy data or Inaccurate data
If we train our model in noisy data or inaccurate data, then it may give good results on that data and also have low bias. But if we again introduce new unseen data to the model to predict, then it may decrease the accuracy and increases the variance.
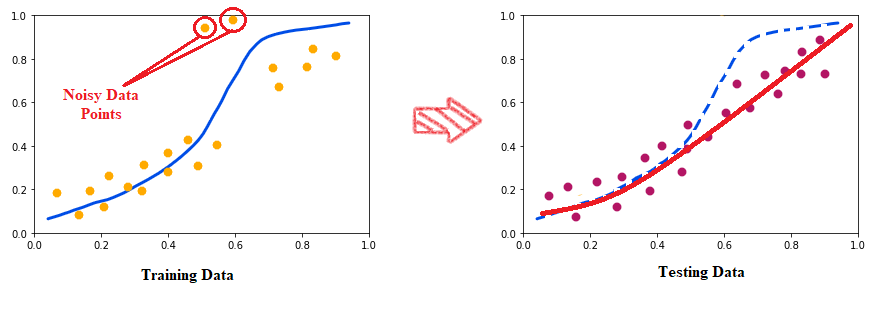
As we can observe in the above picture, in the training data, there are some noisy data points, and because of the overfitting tendency of the model, it is trying to fit even those points. But when we test that with test data, then the red line fits the data properly.
2. Low size of training data
Overfitting is caused by the size of the data. We know that the more the data more the model will learn hence, we try to give better predictions. If the training data is low, then the model will not get to explore all the scenarios or possibilities. This makes the model only fit the given data, but when we introduce it with unseen data, then the accuracy of the prediction will fall, and also the variance will increase.
3. Complexity of the model
Overfitting is also caused by the complexity of the predictive function formed by the model to predict the outcome. The more complex the model more it will tend to overfit the data. hence the bias will be low, and the variance will get higher.
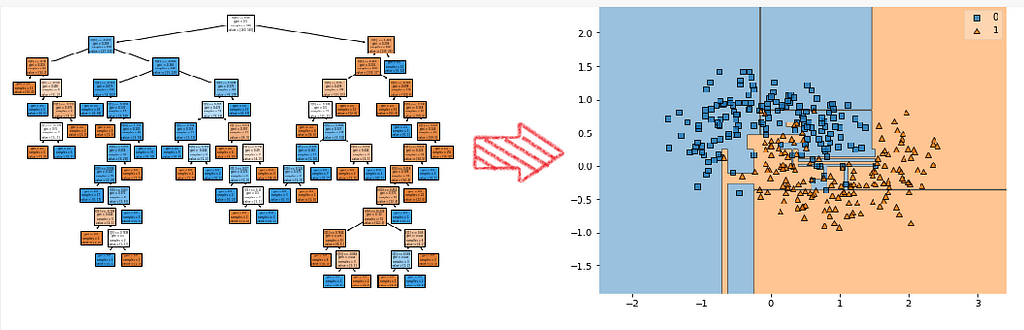
the above picture shows the decision boundary generated by a fully grown decision tree. As we can see, the boundaries are not that much smoother, and it clearly shows overfitting as the decision tree is very complex.
How we can solve the problem of overfitting?
1. Increasing the size of Training data
As we discuss above, low training data leads to overfitting as the model is unable to explore all the possibilities. So, by increase the size of the training data will help to reduce the overfitting problem.
2. Clean the data as much as you can
We always have to clean and pre-process the data before the training. Cleaning refers to removing outliers from the data, handling the multicollinearity between the independent variables, handling missing values, etc.
3. Using Regularization methods
Regularization is a technique used to limit the learning of a machine learning model by introducing some penalty term in the cost function. It helps to generalize the overall model’s function and hence reduces the overfitting problem.
There are three types of Regularization methods:
- L1 Regularization
- L2 Regularization
- Elastic net Regularization
L1 Regularization: It is also called LASSO Regularization. It stands for Least Absolute and Selection Operator. We can calculate it by multiplying with the lambda the weight of each individual feature. This term will be added to the cost function.
The equation for the cost function in ridge regression will be:
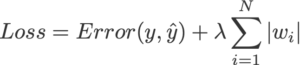
L2 Regularization: It is also called Ridge Regularization. We can calculate it by multiplying the lambda by the squared weight of each individual feature. This term will be added to the cost function.
The equation for the cost function in ridge regression will be:
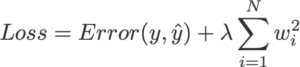
Elastic net Regularization: This regularization is nothing but combining both plenty of terms of L1 and L2 to the cost function. The equation for the cost function in ridge regression will be:
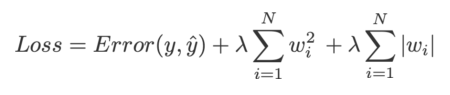
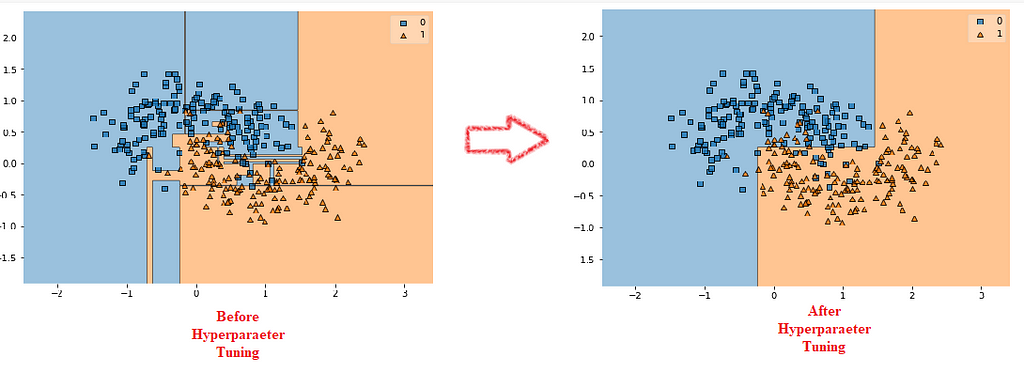
4. Hyperparameter Tuning
We can also solve the problem of overfitting just by turning the hyperparameter of the respective model. For example, Decision Tree most often faces the problem of overfitting. So, if we use the different hyperparameters provided by the model just as limiting the depth of the tree or limiting the child nodes of the tree, etc.
In cases of Deep Neural Networks, we can use techniques like early stopping and dropout to overcome Overfitting.
5. Adopting Ensemble Techniques
Ensemble Techniques help to reduce both bias and Variance hence, resulting reducing the overfitting problems. If you want to learn more about ensemble techniques, please click the below link.
Like and Share if you find this article helpful. Also, follow me on medium for more content related to Machine Learning and Deep Learning.
Overfitting: Causes and Remedies was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

