



Outline
Last Updated on July 24, 2023 by Editorial Team
Author(s): Sik-Ho Tsang
Originally published on Towards AI.
Review: DBPN & D-DBPN — Deep Back-Projection Networks For Super-Resolution (Super Resolution)
Iterative Up & Down Projection Units, Outperforms SRCNN, FSRCNN, VDSR, DRCN, DRRN, LapSRN, and EDSR
In this story, Deep Back-Projection Networks (DBPN) and Dense DBPN (D-DBPN), by Toyota Technological Institute, and Toyota Technological Institute at Chicago, is reviewed. In DBPN:
- it exploits iterative up- and downsampling layers, providing an error feedback mechanism for projection errors at each stage. Mutually-connected up- and down-sampling stages are constructed, each of which represents different types of image degradation and high-resolution components.
- By extending this idea to allow concatenation of features across up- and down-sampling stages (Dense DBPN) further improve the results.
This is a paper in 2018 CVPR with about 300 citations. (
Sik-Ho Tsang @ Medium)
- Comparisons of Deep Network SR
- DBPN: Projection Units
- D-DBPN: Dense Projection Units
- Overall D-DBPN Network Architecture & Some Details
- Ablation Study
- State-Of-The-Art (SOTA) Comparisons
1. Comparisons of Deep Network SR
- (a) Predefined upsampling: commonly uses interpolation as the upsampling operator to produce middle resolution (MR) image. This schema was firstly proposed by SRCNN.
- (b) Single upsampling: offers simple yet effective way to increase the spatial resolution. This approach was proposed by FSRCNN and ESPCN.
- (c) Progressive upsampling: was recently proposed in LapSRN. It progressively reconstructs the multiple SR images with different scales in one feed-forward network.
- (d) Iterative up and downsampling: is proposed in this paper. DBPN focuses on increasing the sampling rate of SR features in different depths and distribute the tasks to calculate the reconstruction error to each stage.
- This schema enables the networks to preserve the HR components by learning various up- and down-sampling operators while generating deeper features.
2. DBPN: Projection Units

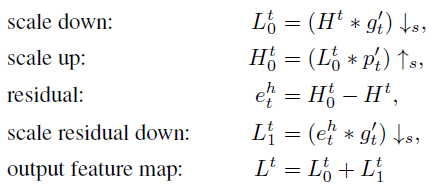
2.1. Up-Projection Unit
- This projection unit takes the previously computed LR feature map Lt-1 as input, and maps it to an (intermediate) HR map Ht0.
- Then it attempts to map it back to LR map Lt0 (“back-project”).
- The residual (difference) elt between the observed LR map Lt-1 and the reconstructed Lt0 is mapped to HR again, producing a new intermediate (residual) map Ht1.
- The final output of the unit, the HR map Ht, is obtained by summing the two intermediate HR maps.
- This step is illustrated in the upper part of the above figure.
2.1. Down-Projection Unit
- The down-projection unit is defined very similarly, but now its job is to map its input HR map Ht to the LR map Lt as illustrated in the lower part of the above figure.
2.3. Arrangements
- These projection units in a series of stages, alternating between H and L.
- These projection units can be understood as a self-correcting procedure which feeds a projection error to the sampling layer and iteratively changes the solution by feeding back the projection error.
- The projection unit uses large sized filters such as 8×8 and 12×12. Usually, the use of large-sized filter is avoided because it slows down the convergence speed and might produce sub-optimal results.
- In this paper, the iterative utilization of our projection units enables the network to suppress this limitation and to perform better performance on large scaling factor even with shallow networks.
3. D-DBPN: Dense Projection Units
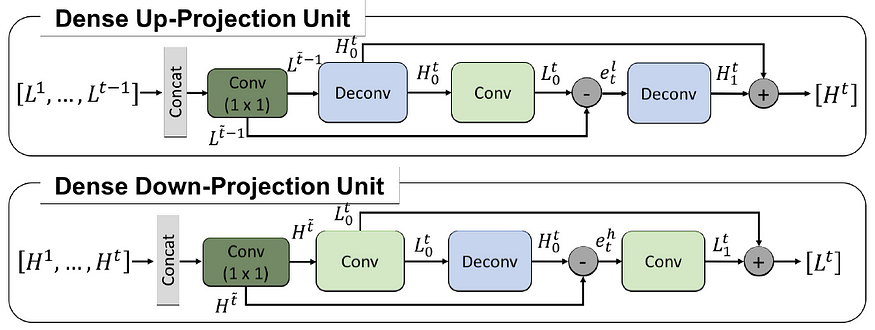
- Inspired by DenseNet, dense connections are introduced in the projection units called, yielding Dense DBPN (D-DBPN).
- But avoiding dropout and batch norm, since they are not suitable for SR.
- The input for each unit is the concatenation of the outputs from all previous units.
- 1×1 convolution layer is used as feature pooling and dimensional reduction before entering the projection unit.
4. Overall D-DBPN Network Architecture & Some Details

4.1. D-DBPN Architecture
- The proposed D-DBPN can be divided into three parts: initial feature extraction, projection, and reconstruction.
- Let conv(f, n) be a convolutional layer, where f is the filter size and n is the number of filters.
- Initial feature extraction: Initial LR feature maps L0 from the input using conv(3, n0). Then conv(1, nR) is used to reduce the dimension from n0 to nR before entering the projection step.
- Back-projection stages: Alternating the up projection and down projection. Each unit has access to the outputs of all previous units.
- Reconstruction: Finally, the target HR image is reconstructed as Isr = fRec([H1,H2,…,Ht]) where fRec use conv(3, 3) as reconstruction and [H1,H2,…,Ht] refers to the concatenation of the feature-maps produced in each up-projection unit.
4.2. Some Details
- For a network with T stages, we have the initial extraction stage (2 layers), and then T up-projection units and T-1 down-projection units, each with 3 layers, followed by the reconstruction (one more layer).
- For the dense network, conv(1, nR) is added in each projection unit, except the first three units.
- For 2× enlargement, 6×6 convolutional layer with two stridings and two paddings are used.
- Then, 4× enlargement use an 8×8 convolutional layer with four striding and two paddings.
- Finally, the 8× enlargement use a 12×12 convolutional layer with eight striding and two paddings.
- PReLU is used.
- All networks are trained using images from DIV2K, Flickr, and ImageNet datasets without augmentation.
- To produce LR images, the HR images are downscaled on particular scaling factors using Bicubic. Batch size of 20 with size 32×32 for LR image is used.
5. Ablation Study
5.1. Depth Analysis

- Multiple networks are constructed as S (T = 2), M (T = 4), and L (T = 6) from the original DBPN. In the feature extraction, we use conv(3, 128) followed by conv(1, 32). Then, we use conv(1, 1) for the reconstruction. The input and output images are luminance only.
- The S network gives a higher PSNR than VDSR, DRCN, and LapSRN. The S network uses only 12 convolutional layers with a smaller number of filters than VDSR, DRCN, and LapSRN.
- The M network outperforms all VDSR, DRCN, LapSRN, and DRRN.
- In total, the M network uses 24 convolutional layers which have the same depth as LapSRN. Compare to DRRN (up to 52 convolutional layers), the M network undeniable shows the effectiveness of our projection unit.
- Finally, the L network outperforms all methods with 31.86 dB which better 0.51 dB, 0.33 dB, 0.32 dB, 0.18 dB than VDSR, DRCN, LapSRN, and DRRN, respectively.

- For the results of 8× enlargement, there is no significant performance gain from each proposed network especially for L and M networks where the difference only 0:04 dB.
5.2. Number of Parameters

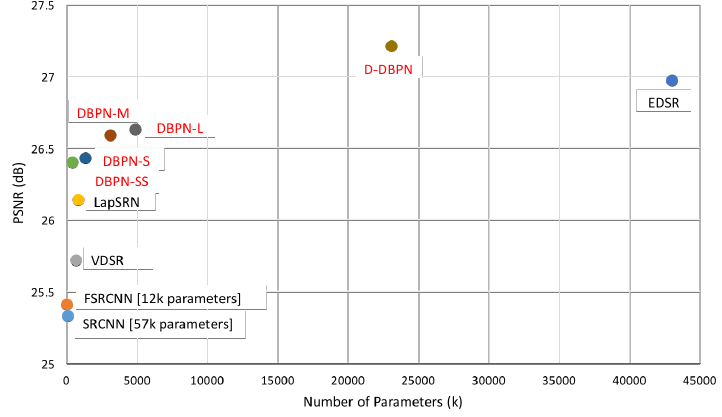
- The SS network is constructed, which is the lighter version of the S network, (T = 2), with only the use of conv(3, 64) followed by conv(1, 18) for the initial feature extraction.
- The results outperform SRCNN, FSRCNN, and VDSR on both 4× and 8× enlargement.
- The SS network performs better than VDSR with 72% and 37% fewer parameters on 4× and 8× enlargement, respectively.
- The S network has about 27% fewer parameters and higher PSNR than LapSRN on 4× enlargement.
- And D-DBPN has about 76% fewer parameters, and approximately the same PSNR, compared to EDSR on 4× enlargement.
- On the 8× enlargement, D-DBPN has about 47% fewer parameters with better PSNR compare to EDSR.
5.3. Deep Concatenation

- Deep concatenation is also well-related with the number of T (back-projection stage), which shows more detailed features generated from the projection units will also increase the quality of the results.
- In the above figure, it is shown that each stage successfully generates diverse features to reconstruct SR image.
5.4. Dense Connections

- On 4× enlargement, the dense network, D-DBPN-L, gains 0.13 dB and 0.05 dB higher than DBPN-L on the Set5 and Set14, respectively.
- On 8×, the gaps are even larger. The D-DBPN-L has 0.23 dB and 0.19 dB higher than DBPN-L on the Set5 and Set14, respectively.
6. State-Of-The-Art (SOTA) Comparisons
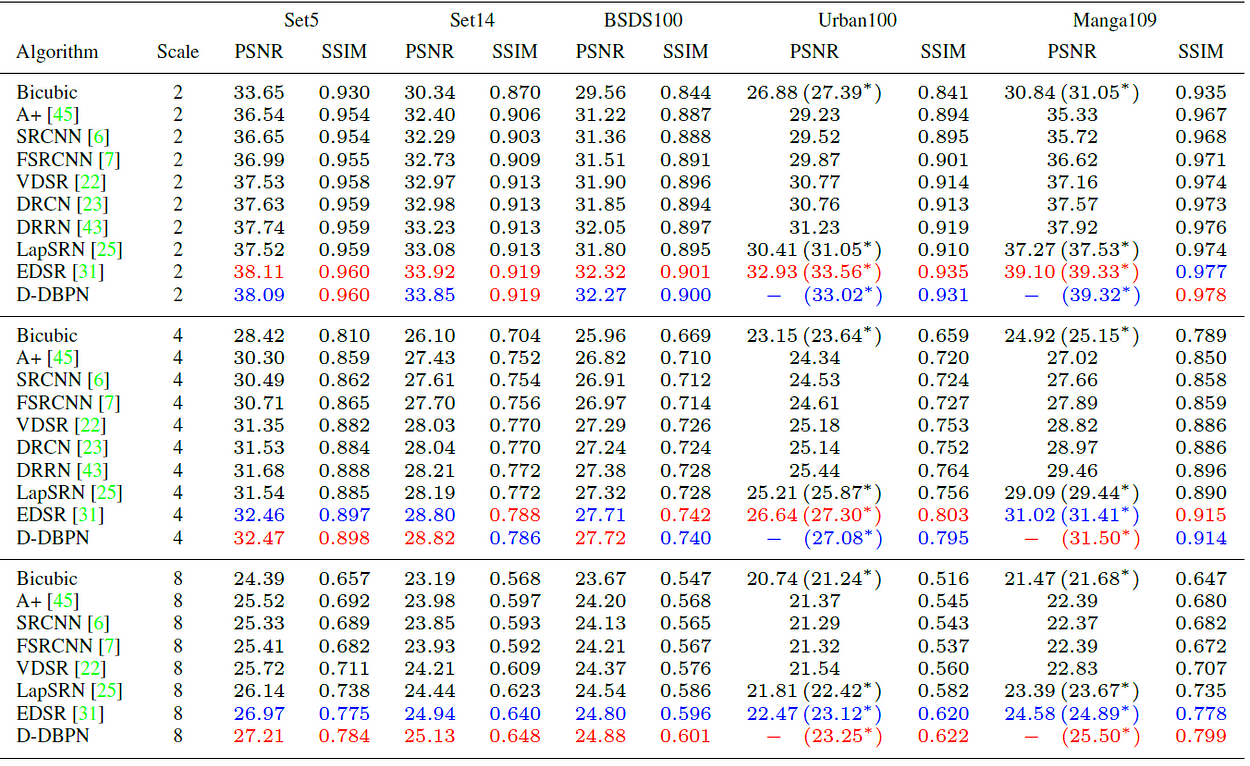
- 5 datasets are evaluated: Set5, Set14, BSDS100, Urban100 and Manga109.
- The final network, D-DBPN, uses conv(3, 256) then conv(1, 64) for the initial feature extraction and t = 7 for the back-projection stages. In the reconstruction, conv(3. 3) is used. RGB color channels are used for input and output image. It takes less than four days to train.
- As shown above, D-DBPN outperforms the existing methods, including SRCNN, FSRCNN, VDSR, LapSRN, by a large margin in all scales except EDSR.
- For the 2× and 4× enlargement, comparable PSNR is obtained with EDSR. However, the result of EDSR tends to generate stronger edge than the ground truth and lead to misleading information.
- In Urban100 with 2× enlargement, EDSR has 0.54 dB higher than D-DBPN.
- But D-DBPN shows it’s effectiveness in the 8× enlargement. The D-DBPN outperforms all of the existing methods by a large margin.
- Interesting results are shown on Manga109 dataset where D-DBPN obtains 25.50 dB which is 0.61 dB better than EDSR.
- While on the Urban100 dataset, D-DBPN achieves 23.25 dB which is only 0.13 dB better than EDSR.

- The result of EDSR for eyelashes in the above figure shows that it was interpreted as a stripe pattern. On the other hand, D-DBPN’s result generates softer patterns that subjectively closer to the ground truth.
- On the butterfly image, EDSR separates the white pattern which shows that EDSR tends to construct regular patterns such as circle and stripe, while D-DBPN constructs the same pattern as the ground truth.

- Qualitatively, D-DBPN is able to preserve the HR components better than other networks.
- It shows that D-DBPN can extract not only features but also create contextual information from the LR input to generate HR components in the case of large scaling factors, such as 8× enlargement.
During the days of coronavirus, let me have a challenge of writing 30 stories again for this month ..? Is it good? This is the 6th story in this month. Thanks for visiting my story..
Reference
[2018 CVPR] [DBPN & D-DBPN]
Deep Back-Projection Networks For Super-Resolution
Super Resolution
[SRCNN] [FSRCNN] [VDSR] [ESPCN] [RED-Net] [DnCNN] [DRCN] [DRRN] [LapSRN & MS-LapSRN] [MemNet] [IRCNN] [WDRN / WavResNet] [MWCNN] [SRDenseNet] [SRGAN & SRResNet] [EDSR & MDSR] [MDesNet] [RDN] [SRMD & SRMDNF] [DBPN & D-DBPN] [RCAN] [SR+STN]
My Other Previous Reviews
Published by Towards AI
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

