


Multimodal Language Models Explained: Visual Instruction Tuning
Last Updated on August 10, 2023 by Editorial Team
Author(s): Ali Moezzi
Originally published on Towards AI.
An introduction to the core ideas and approaches to move from unimodality to multimodal LLMs
LLMs have shown promising results on both zero-shot and few-shot learning on many natural language tasks. Yet, LLMs are at a disadvantage when it comes to tasks that it requires visual reasoning. Meanwhile, large vision models, like SAM, achieved the same level of progress in perception as LLMs in textual reasoning.
Marrying LLMs with perceptional reasoning capability is moving towards an emerging field called MLLM. This field has a strong argument for enhancing the robustness of LLMs as we learn in a multisensory way, with each sensory being complementary to the other. As for the user experience, multi-modality can bring a higher level of conciseness. Users will be able to express their intention more effectively by just providing an image as input to the model instead of describing it as a long paragraph.
A picture is worth a thousand words — Henrik Ibsen
As an illustration for these exciting emerging use cases, MiniGPT-4 [1] creates websites based on handwritten text instructions or generates detailed recipes by observing appetizing food photos. Similarly, MM-ReAct [2] incorporates visual information in the forms of image captioning, dense captioning, image tagging, etc., inside the prompt to feed to the LLM. With this technique, an existing LLM can be augmented for understanding visual-conditioned jokes and memes, visual math and text reasoning and spatial and coordinate understanding, visual planning, and prediction.
This would be a series of articles covering multimodal zero-shot learning through instruction tuning, and few-shot learning using multimodal in-context learning. Then afterwards multimodal CoT and visual reasoning.
In this article, I go over what instruction tuning means in the context of multimodality, and then in the next post, I will discuss few-shot learning for MLLM using In-Context Learning.
Multimodal Zero-shot learning using Instruction Tuning
Fine-tuned LLMs showcase limited performance on unseen tasks, especially under distribution shifts. However, to generalize better on these downstream tasks, we can use instruction finetuning. Instruction finetuning is a technique to finetune a pre-trained LLM with an instruction dataset using reinforcement learning. In contrast, it was common to pre-trained LLMs with a masking task on a general-purpose dataset like C4 and then finetune it on a task-specific dataset such as translation (Bart) [5], code generation (CodeT5) [4] and parsing (ReportQL, HydraNet)[6, 7].
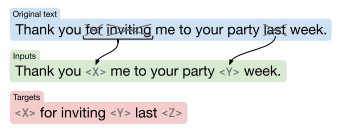
Instruction tuning learns a generalized understanding of how it should follow instructions to achieve a task rather than fitting it to a particular task. This gives the model higher generalization capabilities in a setting where enough instructions for every task have been provided.

On the other hand, finetuning a language model is data-hungry which makes the approach less applicable when domain-specific data is limited. Although synthetic data for finetuning seems promising, much research has revealed the approach is prone to bias and lacks generalization to unseen samples [8]. Prompting improves performance on few-shot learning, especially in low-data regimes.
Multi-modal instruction dataset generation
One of the major issues in extending instruction tuning to multi-modality is the lack of data. To provision a multi-modal instruction dataset researcher either adapts existing benchmarks or self-instruction. Zhu et al. [9] in their work “MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models,” found that using publicly available image-text datasets results in suboptimal performance. They argue the lack of coherency, repetition, and fragmented sentences affects language models’ dialog performance. Hence, MiniGPT-4 employs a two-step alignment process. In the first stage, they generate a verbose description of the image using prompting to the model derived from the first pretraining stage. They design a prompt specifically for conversational use cases to generate descriptions.
###Human: <Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see.
###Assistant:
Image features here incorporate features from a linear projection layer. When output length is below an 80 tokens threshold they precede the conversation with continue:
###Human: Continue
###Assistant:
Following this approach, they generated comprehensive descriptions for around 5,000 images from the Conceptual Caption dataset [10].
The generated dataset is still noisy and needs post-processing. The authors used ChatGPT to eliminate issues such as incoherent sentences and word repetition.
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
To verify correctness, they manually assessed the image description and refined the generated captions. Finally, they sub-selected almost 3,500 from 5,000 generated pairs that satisfied their quality criteria.
In contrast to MiniGPT-4, Liu et al. [11] only leveraged ChatGPT/GPT-4 to provision a multi-modal instruction dataset. The context of ChatGPT includes a symbolic representation consisting of captions and bounding boxes.
Context type 1: Captions
A group of people standing outside of a black vehicle with various luggage.
Luggage surrounds a vehicle in an underground parking area
People try to fit all of their luggage in an SUV.
The sport utility vehicle is parked in the public garage, being packed for a trip
Some people with luggage near a van that is transporting it.
Context type 2: Boxes
person: [0.681, 0.242, 0.774, 0.694], person: [0.63, 0.222, 0.686, 0.516], person: [0.444, 0.233,
0.487, 0.34], backpack: [0.384, 0.696, 0.485, 0.914], backpack: [0.755, 0.413, 0.846, 0.692],
suitcase: [0.758, 0.413, 0.845, 0.69], suitcase: [0.1, 0.497, 0.173, 0.579], bicycle: [0.282, 0.363,
0.327, 0.442], car: [0.786, 0.25, 0.848, 0.322], car: [0.783, 0.27, 0.827, 0.335], car: [0.86, 0.254,
0.891, 0.3], car: [0.261, 0.101, 0.787, 0.626]
Captions describe the scene from different perspective, while bounding boxes infers spatial information about objects. Using this context, they generate 3 types of instruction datasets. Firstly, conversation, which involves generating a set of a diverse set of questions asked about the content of images. The prompt also considers limiting questions to ones that can be confidently answered, given the context.
messages = [ {"role":"system", "content": f"""You are an AI visual assistant, and you are
seeing a single image. What you see are provided with five sentences, describing the same image you
are looking at. Answer all questions as you are seeing the image.
Design a conversation between you and a person asking about this photo. The answers should be in a
tone that a visual AI assistant is seeing the image and answering the question. Ask diverse questions
and give corresponding answers.
Include questions asking about the visual content of the image, including the object types, counting
the objects, object actions, object locations, relative positions between objects, etc. Only include
questions that have definite answers:
(1) one can see the content in the image that the question asks about and can answer confidently;
(2) one can determine confidently from the image that it is not in the image. Do not ask any question
that cannot be answered confidently.
Also include complex questions that are relevant to the content in the image, for example, asking
about background knowledge of the objects in the image, asking to discuss about events happening in
the image, etc. Again, do not ask about uncertain details. Provide detailed answers when answering
complex questions. For example, give detailed examples or reasoning steps to make the content more
convincing and well-organized. You can include multiple paragraphs if necessary."""}
]
for sample in fewshot_samples:
messages.append({"role":"user", "content":sample[‘context’]})
messages.append({"role":"assistant", "content":sample[‘response’]} )
messages.append({"role":"user", "content":‘\n’.join(query)})
The next type which is called “detailed description”, aims to generate a comprehensive explanation for an image. Given an image, they randomly sample one question from a list of predefined questions to generate a detailed description.
• "Describe the following image in detail"
• "Provide a detailed description of the given image"
• "Give an elaborate explanation of the image you see"
• "Share a comprehensive rundown of the presented image"
• "Offer a thorough analysis of the image"
• "Explain the various aspects of the image before you"
• "Clarify the contents of the displayed image with great detail"
• "Characterize the image using a well-detailed description"
• "Break down the elements of the image in a detailed manner"
• "Walk through the important details of the image"
• "Portray the image with a rich, descriptive narrative"
• "Narrate the contents of the image with precision"
• "Analyze the image in a comprehensive and detailed manner"
• "Illustrate the image through a descriptive explanation"
• "Examine the image closely and share its details"
• "Write an exhaustive depiction of the given image"
Finally, “complex reasoning” where here it refers to answering in-depth questions that require a step-by-step reasoning process that follows logic. To this end, they use a similar prompt to “conversation” but with more emphasis on reasoning.
You are an AI visual assistant that can analyze a single image. You receive five sentences, each describing the same image you are observing. In addition, specific object locations within the image are given, along with detailed coordinates. These coordinates are in the form of bounding boxes, represented as (x1, y1, x2, y2) with floating numbers ranging from 0 to 1. These values correspond to the top left x, top left y, bottom right x, and bottom right y.
The task is to use the provided caption and bounding box information, create a plausible question about the image, and provide the answer in detail.
Create complex questions beyond describing the scene.
To answer such questions, one should require first understanding the visual content, then based on the background knowledge or reasoning, either explain why the things are happening that way, or provide guides and help to user's request. Make the question challenging by not including the visual content details in the question so that the user needs to reason about that first.
Instead of directly mentioning the bounding box coordinates, utilize this data to explain the scene using natural language. Include details like object counts, position of the objects, relative position between the objects.
When using the information from the caption and coordinates, directly explain the scene, and do not mention that the information source is the caption or the bounding box. Always answer as if you are directly looking at the image.
By using this approach, they generated a total of 158K language-image multi-modal datasets of which 58k samples of conversations, 23k samples of detailed description, and 77k samples of complex reasoning.
Another line of work to provision a multi-modal instruction dataset is to apply instruction templates to already available language-image datasets. MultiInstruct by Xu et. al. [12] uses already available benchmarks for more than 47 tasks from 54 datasets to create a new multi-modal instruction dataset to allow LLMs to learn fundamental skills such as object recognition, visual relationship understanding, text-image grounding, and so on.
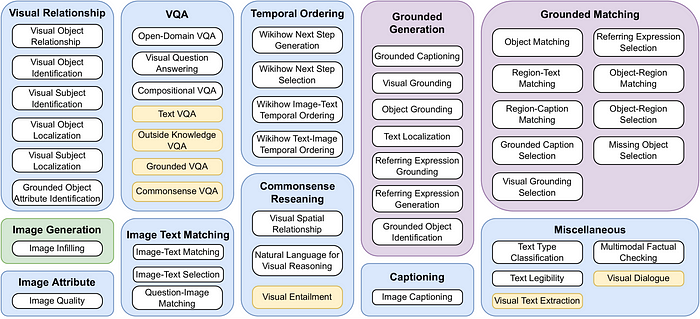
As you might guess some of these benchmarks might overlap with each other, hence the authors considered the possibility of decomposing complex tasks into simpler tasks.
For example, Visual Grounding requires the model to generate a caption for a given region in the image. We derive two additional tasks that are related to this complex skill: Grounded Caption Selection, which is a simpler skill that requires the model to select the corresponding caption from multiple candidates for the given region, and Visual Grounding Selection, which requires the model to select the corresponding region from the provided candidate regions based on a given caption [12].
Thereafter, 2–3 human annotators were assigned for each task to write 5 task-specific instructions for both training and evaluation. Instructions are formed in a unified format of <TEXT>, <REGION>, and <OPTION>. Here, <TEXT> is a placeholder for the instruction, <REGION> is the placeholder for region-specific information and <OPTION> is only used in classification tasks [12].
Otter [13], on the other hand, starts from MMC4 with the motivation to use context in the dataset. MMC4 consists of image-text pairs derived from webpages and “context” as the remaining text of the page. Similar examples are grouped to form a contextual example set.

In short, common methods in the literature to provision multi-modal instruction datasets are self-instruct, which involves using a pre-trained network to generate instruction data. On the contrary, others have adapted already existing benchmarks in visual and multimodal learning.
Moving forward, after dataset adaptation and generating visual instruction dataset for fine-tuning LLMs we need to create an interface to inject multi-modalities to LLMs.
Adapting LLMs for Multi-modal Prompts
As it’s challenging and costly to heavily change the architecture of LLMs and train them from scratch, we can see the dominance of methods similar to parameter-efficient fine-tuning [14] to inject visual embedding.
Soft prompt along with a projection layer is one of the PEFT methods used in MiniGPT-4 [11] for embedding visual information. MiniGPT-4 leverages Vicuna as a language decoder and employs a ViT coupled with a pre-trained Q-Former.
Soft prompting, in general, refers to prepending a trainable tensor to the model’s input embedding to be optimized using backpropagation for a particular task. This tensor can have a length of roughly 1 to 150 tokens.
def soft_prompted_model(input_ids):
x = Embed(input_ids)
x = concat([soft_prompt, x], dim=seq)
return model(x)
Another variant of soft prompting is prefix-tuning. Unlike the previous approach, the trainable tensor will be prepended to hidden states of all layers. As we directly manipulate all layers, Li and Liang [15] found instability in optimizing the prepended tensor. As such, they use an intermediate FFN before directly prepending the tensor to the network.
def transformer_block_for_prefix_tuning(x):
soft_prompt = FFN(soft_prompt)
x = concat([soft_prompt, x], dim=seq)
return transformer_block(x)
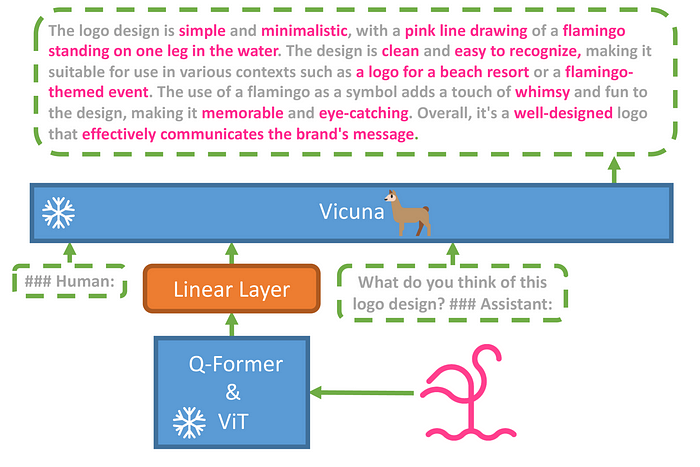
Switching back to MiniGPT-4, the authors inject the output of the pre-trained vision encoder as a soft prompt to the Vicuna through an FFN. During their first stage of training, both the vision encoder and language decoder networks are frozen while only one projection layer is trained.
@registry.register_model("mini_gpt4")
class MiniGPT4(Blip2Base):
def __init__(...):
self.llama_proj = nn.Linear(
self.Qformer.config.hidden_size, self.llama_model.config.hidden_size
)
def encode_img(self, image):
...
with self.maybe_autocast():
image_embeds = self.ln_vision(self.visual_encoder(image)).to(device)
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(device)
query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
query_output = self.Qformer.bert(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
)
inputs_llama = self.llama_proj(query_output.last_hidden_state)
atts_llama = torch.ones(inputs_llama.size()[:-1], dtype=torch.long).to(image.device)
return inputs_llama, atts_llama
def forward(self, samples):
image = samples["image"]
img_embeds, atts_img = self.encode_img(image)
if hasattr(samples, 'question_split'): # VQA dataset
print('VQA Batch')
vqa_prompt = '###Human: <Img><ImageHere></Img> '
img_embeds, atts_img = self.prompt_wrap(img_embeds, atts_img, vqa_prompt)
elif self.prompt_list:
prompt = random.choice(self.prompt_list)
img_embeds, atts_img = self.prompt_wrap(img_embeds, atts_img, prompt)
...
to_regress_embeds = self.llama_model.model.embed_tokens(to_regress_tokens.input_ids)
inputs_embeds = torch.cat([bos_embeds, img_embeds, to_regress_embeds], dim=1)
attention_mask = torch.cat([atts_bos, atts_img, to_regress_tokens.attention_mask], dim=1)
with self.maybe_autocast():
outputs = self.llama_model(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
return_dict=True,
labels=targets,
)
loss = outputs.loss
return {"loss": loss}
To align this projection layer, they use image-text pair datasets such as Conceptual Caption, SBU, and LAION for almost 20,000 training steps with a batch size of 256, covering approximately 5 million samples [9].
Similarly, X-LLM [16] aligns multiple frozen single-modal encoders for images, speech, and videos and a frozen LLM using dedicated interfaces for each modality. Moreover, instead of soft prompting, they adapt Q-Former to convert visual information into a sequence with quasi-linguistic embeddings as a part of the prompt.
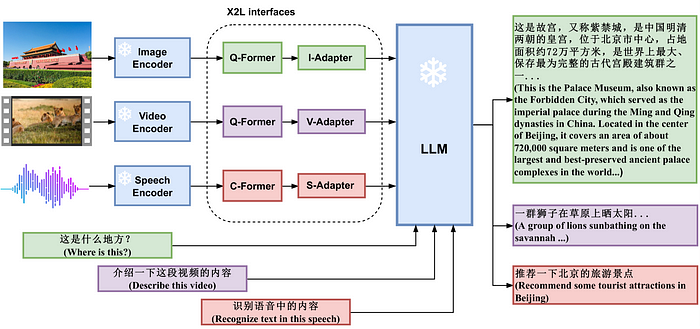
Q-Former from BLIP-2 is used as the interface for image and video modalities and needs to be adapted to convert the aforementioned modalities into languages. This is done in the first stage of the training where they used image-caption pairs and video-caption pairs to pre-train the module. As these two modalities are close to each other, they reused the parameter of the image interface but further fine-tuned it on video-text data [16]. For the speech interface, they used the CIF mechanism introduced in [17] to convert speech utterances into language. However, they found that although BLIP2 used English data for pre-training, it still performs well in the second stage. As a result, the authors choose to reuse the pre-trained parameters of the Q-Former and only train a CIF-based ASR model as their speech encoder.
The Q-former module is accompanied by an adapter module to align the dimensions of the quasi-linguistic embeddings and the embedding dimension of the LLM [16].
In the second stage, each interface module is aligned further to the frozen LLM through 14 million Chinese image-text pairs and AISHELL-2 and the VSDial-CN dataset as the ASR training dataset.
Conversely, Otter was trained with a few cross-gated attention layers to connect visual and language information and established attention between in-context examples, leaving the vision encoder and language decoder frozen [13].
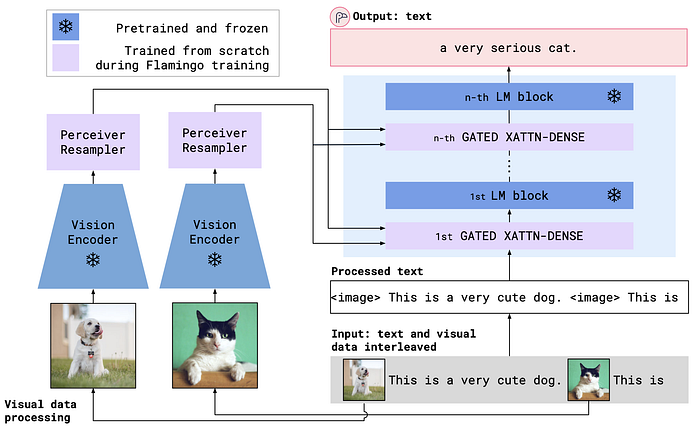
In Flamingo, text generation by the LLM decoder is conditioned on the visual information embeddings produced by Perceiver Resampler. It takes an arbitrary number of image or video features encoded from a vision encoder model and produces a fixed-sized output to help reduce the complexity of the vision-text cross-attention module that interleaves the frozen LM blocks.
def gated_xattn_dense(
y, # input language features
x, # input visual features
alpha_xattn, # xattn gating parameter — init at 0.
alpha_dense, # f fw gating parameter — init at 0.
):
# 1. Gated Cross Attention
y = y + tanh(alpha_xattn) * attention(q=y, kv=x)
# 2. Gated Feed Forward (dense) Layer
y = y + tanh(alpha_dense) * ffw(y)
# Regular self-attention + FFW on language
y = y + frozen_attention(q=y, kv=y)
y = y + frozen_ffw(y)
return y # output visually informed language features
The mentioned gated dense cross-attention module uses the tanh-gating mechanism used in LSTM [19]. It controls adding the result of attention to y from the residual connection through the learned alpha_xattn parameter. As of initialization, the output of attention and ffw are merely random and might cause training instability. Whereas with the gating mechanism alpha is initialized with 0 and has no effects at the beginning of the training.
To recap, traces of PEFT are the major approach in the literature to adapt LLMs for multi-modality. In some cases, visual embeddings are directly represented in the prompt or the same as Flamingo, the architecture of LLM is more manipulated to trade-off for better accuracy. This field is relatively new and there are many lines of work that haven’t been explored yet.
In the next post from this series, I will be focusing on Multimodal few-shot learning using In-Context Learning.
I will write more articles in CS. If you’re as passionate about the industry as I am ^^ and find my articles informative, be sure to hit that follow button on Medium and continue the conversation in the comments U+1F4AC. Don’t hesitate to reach out to me directly on LinkedIn!
[1] Zhu, D., Chen, J., Shen, X., Li, X., & Elhoseiny, M. (2023). Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.
[2] Yang, Z., Li, L., Wang, J., Lin, K., Azarnasab, E., Ahmed, F., … & Wang, L. (2023). Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381.
[3] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1), 5485–5551.
[4] Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., … & Zettlemoyer, L. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
[5] Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., … & Zettlemoyer, L. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
[6] Moezzi, S. A. R., Ghaedi, A., Rahmanian, M., Mousavi, S. Z., & Sami, A. (2023). Application of deep learning in generating structured radiology reports: a transformer-based technique. Journal of Digital Imaging, 36(1), 80–90.
[7] Lyu, Q., Chakrabarti, K., Hathi, S., Kundu, S., Zhang, J., & Chen, Z. (2020). Hybrid ranking network for text-to-sql. arXiv preprint arXiv:2008.04759.
[8] Ravuri, S., & Vinyals, O. (2019). Classification accuracy score for conditional generative models. Advances in neural information processing systems, 32.
[9] Zhu, D., Chen, J., Shen, X., Li, X., & Elhoseiny, M. (2023). Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.
[10] Changpinyo, S., Sharma, P., Ding, N., & Soricut, R. (2021). Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3558–3568).
[11] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual instruction tuning. arXiv preprint arXiv:2304.08485.
[12] Xu, Z., Shen, Y., & Huang, L. (2022). Multiinstruct: Improving multi-modal zero-shot learning via instruction tuning. arXiv preprint arXiv:2212.10773.
[13] Li, B., Zhang, Y., Chen, L., Wang, J., Yang, J., & Liu, Z. (2023). Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726.
[14] Lialin, V., Deshpande, V., & Rumshisky, A. (2023). Scaling down to scale up: A guide to parameter-efficient fine-tuning. arXiv preprint arXiv:2303.15647.
[15] Li, X. L., & Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190.
[16] Chen, F., Han, M., Zhao, H., Zhang, Q., Shi, J., Xu, S., & Xu, B. (2023). X-llm: Bootstrapping advanced large language models by treating multi-modalities as foreign languages. arXiv preprint arXiv:2305.04160.
[17] Dong, L., & Xu, B. (2020, May). Cif: Continuous integrate-and-fire for end-to-end speech recognition. In ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6079–6083). IEEE.
[18] Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, & Wanrong Zhu. (2023). OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models.
[19] Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735–1780.
[20] Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., … & Le, Q. V. (2021). Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


