



Multi-Query Attention Explained
Last Updated on November 18, 2023 by Editorial Team
Author(s): florian
Originally published on Towards AI.
Multi-Query Attention (MQA) is a type of attention mechanism that can accelerate the speed of generating tokens in the decoder while ensuring model performance.
It is widely used in the era of large language models, many LLMs adopt MQA, such as Falcon, PaLM, StarCoder, and others.
Multi-Head Attention(MHA)
Before introducing MQA, let’s first review the default attention mechanism of the transformer.
Multihead Attention is the default attention mechanism of the transformer model, as shown in Figure 1:
However, there is an issue with autoregressive language models based on transformer decoders when it comes to text generation.
During training, we have access to the true target sequence and can efficiently implement parallelism.
However, during inference, each position’s query attends to all the key-value pairs generated at or before that position. In other words, the output of the self-attention layer at a specific position affects the generation of the next token. Due to the inability to perform parallel computation, decoding becomes slower.
Below is the decoding process of a self-attention layer in an autoregressive language model based on transformer decoders:
def MHAForDecoder(x, prev_K, prev_V, P_q, P_k, P_v, P_o):
q = tf.einsum("bd, hdk−>bhk", x, P_q)
new_K = tf.concat([prev_K, tf.expand_dims(tf.einsum ("bd, hdk−>bhk", x, P_k), axis = 2)], axis = 2)
new_V = tf.concat([prev_V, tf.expand_dims(tf.einsum("bd, hdv−>bhv", x, P_v), axis = 2)], axis = 2)
logits = tf.einsum("bhk, bhmk−>bhm", q, new_K)
weights = tf.softmax(logits)
O = tf.einsum("bhm, bhmv−>bhv", weights, new_V)
Y = tf.einsum("bhv, hdv−>bd", O, P_o)
return Y, new_K, new_V
Variables:
- x: the input tensor at the current step, which is m+1 step, with a shape of [b, d]
- P_q, P_k: the query and key projection tensors, with a shape of [h, d, k]
- P_v: the value projection tensor, with a shape of [h, d, v]
- P_o: the learned linear projections, with a shape of [h, d, v]
- Prev_K: the Key tensor from the previous step, with a shape of [b, h, m, k]
- Prev_V: the Value tensor from the previous step, with a shape of [b, h, m, v]
- new_K: the Key tensor with the addition of the current step, with a shape of [b, h, m+1, k]
- new_V: the Value tensor with the addition of the current step, with a shape of [b, h, m+1, v]
Dimensions:
- m: the number of previous steps performed
- b: batch size
- d: dimension of the input and output
- h: number of heads
- k: another dimension of the Q, K tensors
- v: another dimension of the V tensor
Multi-Query Attention(MQA)
Multi-Query Attention is a variation of multi-head attention.
The approach of MQA is to keep the original number of heads for Q, but have only one head for K and V. This means that all the Q heads share the same set of K and V heads, hence the name Multi-Query, as shown in Figure 2:

The code of the decoding process for MQA is essentially the same as the code for MHA, except that the letter “h” representing the dimension of the heads is removed from the tf.einsum equation for K, V, P_k and P_v:
def MQAForDecoder(x, prev_K, prev_V, P_q, P_k, P_v, P_o):
q = tf.einsum("bd, hdk−>bhk", x, P_q)
new_K = tf.concat([prev_K, tf.expand_dims(tf.einsum ("bd, dk−>bk", x, P_k), axis = 2)], axis = 2)
new_V = tf.concat([prev_V, tf.expand_dims(tf.einsum("bd, dv−>bv", x, P_v), axis = 2)], axis = 2)
logits = tf.einsum("bhk, bmk−>bhm", q, new_K)
weights = tf.softmax(logits)
O = tf.einsum("bhm, bmv−>bhv", weights, new_V)
Y = tf.einsum("bhv, hdv−>bd", O, P_o)
return Y, new_K, new_V
Performance
How much can MQA actually improve speed? Let’s take a look at the results chart provided in the original paper:
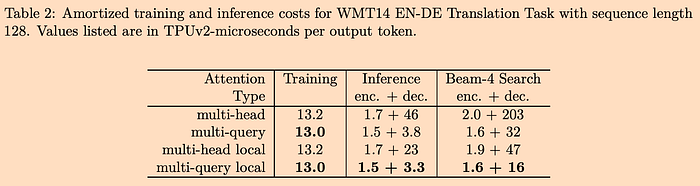
From the table above, it can be seen that the speed improvement of MQA on the encoder is not very significant, but it is quite significant on the decoder.
There are also experiments about quality in the paper, which show that MQA only has a slightly lower performance compared to the baseline. Please refer to the paper for more details, the link is at the bottom of this article.
Why can MQA achieve inference acceleration?
More Memory Efficient
In MQA, the size of the key and value tensors is b * k and b * v, while in MHA, the size of the key and value is b * h * k and b * h * v, where h represents the number of heads.
Lower computational complexity
By using KV cache, the computational cost of calculating tensor Key and Value in each step of MQA is 1/h of MHA, where h represents the number of heads.
Summary
In general, MQA achieves inference acceleration through the following methods:
- The KV cache size is reduced by a factor of h(number of heads), which means that the tensors that need to be stored in the GPU memory are also reduced. The space saved can be used to increase the batch size, thereby improving efficiency.
- The amount of data read from memory is reduced, which reduces the waiting time for computational units and improves computational utilization.
- MQA has a relatively small KV cache that can fit into the cache (SRAM). MHA, on the other hand, has a larger KV cache that cannot be entirely stored in the cache and needs to be read from the GPU memory (DRAM), which is time-consuming.
Conclusion
It is worth mentioning that MQA was proposed in 2019, and its application was not as extensive at that time. This is because the previous models did not need to concern themselves with these aspects, for example, LSTM only needed to maintain one state, without the need to preserve any cache.
When the transformer was initially proposed, it was mainly used in Seq2Seq tasks, specifically in Encoder-Decoder models. However, the models were not very large in scale and there wasn’t much practical demand for them, so MQA didn’t attract much attention.
Later on, the representative model BERT, which is also based on the transformer encoder structure, made a direct forward pass.
It was only when recent large language models based on transformer decoder, like GPT, gained widespread application that the bottleneck of inference was discovered. As a result, people revisited tricks from a few years ago and found them to be very useful. In other words, it is mainly due to the practical demand for large-scale GPT-style generative models.
Finally, if there are any errors or omissions in this text, please feel free to point them out.
References
MQA paper: Fast Transformer Decoding: One Write-Head is All You Need
https://paperswithcode.com/method/multi-query-attention
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

