



MLOps 4: Data in production
Last Updated on July 25, 2023 by Editorial Team
Author(s): Akhil Theerthala
Originally published on Towards AI.
Hi everyone! This is Akhil Theerthala, back again in the MLOps series. I had to take a break last week due to a fest at my uni. Now, returning to the series, we have seen the different phases in the machine learning project lifecycle and explored the modeling and deployment standard procedures.
Finally, it is time to move to the next phase after painstakingly going across 3 different parts for modeling in detail. This phase is the data phase, where we focus on defining the data we use to develop a model and some tips for labeling and cleaning the data.
Why is defining data hard?
In article 1 of this series, we have described this phase as the step when we define the necessary data for the problem, label it, and pre-process it as needed. But checking if the data is defined and labelled correctly is a very tedious task.
The main reason for this is the different possible labels and definitions, where none is 100% correct. Each has its own reasoning. Let us look at this through examples, starting from an example with unstructured data.
Iguana Detection
Let’s say we have an image of 2 iguanas, one facing away from and one slightly towards the camera.

Now, we ask 3 people to label the iguanas in that particular image and draw bounding boxes around them. And we get these responses,

Now, in the above labeling, we can happily work with any one of the three labelings, and the models give very optimum results. However, what happens when we have a mixture of these different kinds of labels, each backed with other logic? The model gets confused, and we get subpar results.
This is not a big problem when our dataset is small. We can correct the labels quickly; however, imagine a dataset with more than 10000 images and a possibility of a variety of labeling logic. This verification takes a lot of time.
Let’s take a look at a second example with structured data.
Suppose you run a business like LinkedIn that lets people apply to different jobs by signing up with their email address, first name, and a few such details. After a few months, you start an app to reach more people. But this has also caused some of your existing customers to create duplicate accounts. Now, it’s your job to clean this duplicate data so that you can run further analysis.
During this maintenance, you have found 2 entries that are as follows,

So, when you first see it, you can directly guess that this is a duplicate entry, and you should remove it. But there is also that slight uncertainty from your inner perfectionist screaming that these might be 2 entirely different people living with the same names in the same locality.
And in some rare cases, that might also happen. All we know is that there is a possibility for 2 people with names Nova Ng to live in the same area. In such cases, what should you do?
Should you remove this entry in hopes of making sure that the data stays clean? or Should you leave this entry with the possibility that these two are different people?
Different people will think differently in such cases; some might merge these, while others might not. Similar examples can be found in problems with structured data like bot/spam account identification, Stolen account identification, etc.
Therefore, before we process this data, we set up some basic ground rules for the labeling, which is iteratively changed and updated over the course of data cleaning. In defining this set of rules, we generally brainstorm different possibilities that can go wrong. Well, you remember Murphy’s first law,
Anything that can go wrong will go wrong.
That is so true in the case of defining data. (At least from my experience in working with different datasets.)Hence, here are a few questions you can ask yourself to set up your rules.
- What is the input X?
— For images, it would be better to know about the lighting conditions, the contrast of the photos, the resolution of the images, etc.,
— For structured data, we should know more about the features available and their relevance to the project. - What is the target y?
— We should clarify what kind of output we want from the model.
— We should also brainstorm what could go wrong during the labeling so that clear instructions can be defined.
However, we must remember that the best practices for handling data of one type contradict the best practices for different kinds of data. Hence, we need a helpful framework that factors in the variety of data for machine learning projects.
Major types of data problems.
When there are multiple types of data, we need to generalize these kinds of data categories. There is one method where we use a 2×2 grid to generalize this. In this grid, one axis determines the type of data we are working with, while the other axis is the size of the dataset.

In the above image, we can see different examples for each significant type of data problem. In general, it is common to use manual labeling for unstructured types of data. As discussed in article 3, we can obtain more data using data augmentation. However, it is harder to get more data for unstructured data and even harder to label them manually.
When we have a relatively small dataset, having clean and consistent labels is critical for training a good model. However, it is more challenging to get clean labels for massive datasets. Hence, the emphasis is generally placed on data processing for large datasets.
Why is having consistent labels important in small data problems?
Let’s say we have a dataset with 5 examples where we are trying to map the voltage of the battery vs. the speed of the rotor (rpm) of a remote-controlled helicopter.
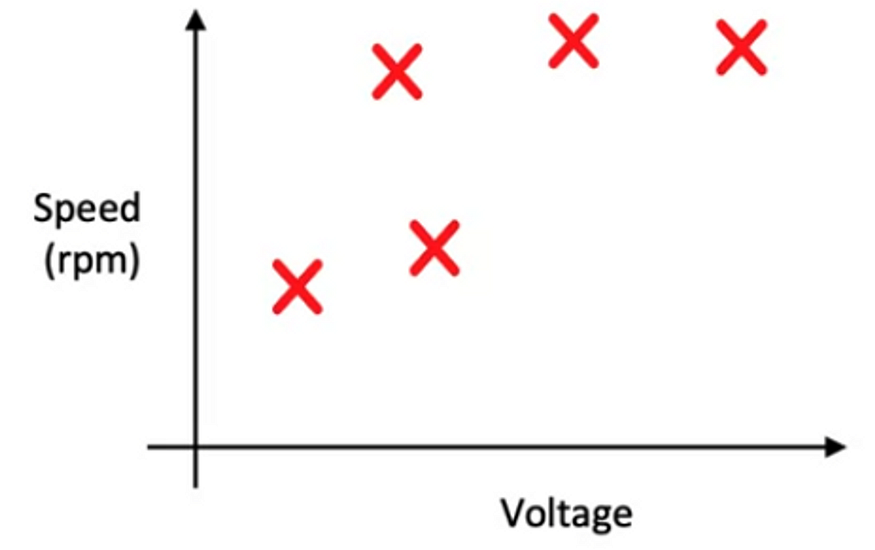
Now, it is tough for us to build a model to fit this data perfectly, as we can clearly see some noise in this dataset. (The point in the middle, where the speed is clearly low.) Now, imagine the same dataset but without noise.
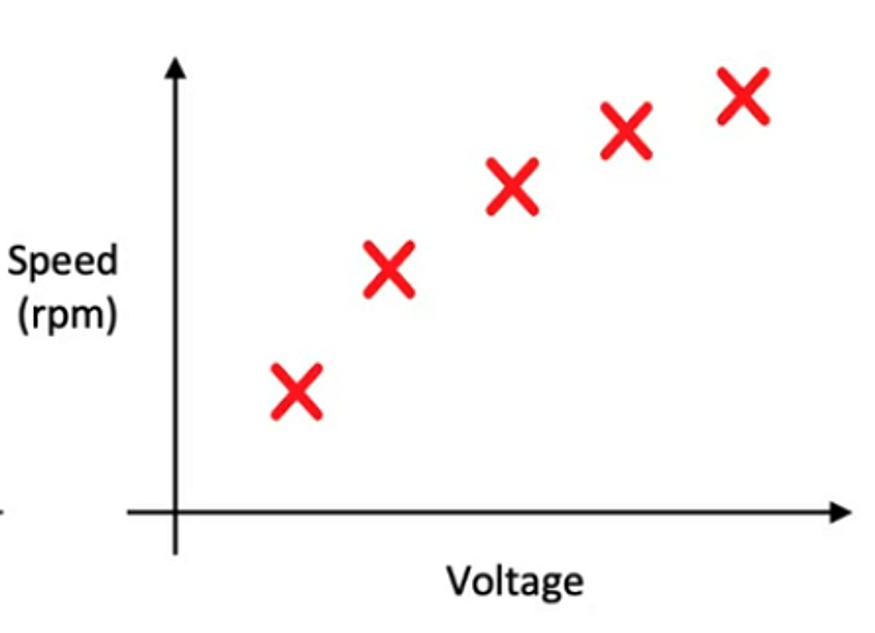
Here we can confidently fit the data to a model, and we can easily model the data. Some of the ongoing research problems in Mechanical Engineering, where the goal is defect identification, also use a few examples. I have seen a friend working on such a project. The key to such problems is to try to keep the labels consistent and clean.
If labeling instructions are unclear, then the labels will unconditionally be ambiguous. One thing to note is that we can also find big data problems with small data challenges.
For example, say that we are collecting data for developing a product recommendation system for shopping marts. The average marts generally have products belonging to thousands of different categories. We might find many products with very few sales. Such cases have shallow user interaction data. We need to ensure that this small data for each item, over a long tail of things, have consistent labeling.
Improving label consistency
One way to improve label consistency is to have clear and defined instructions. To achieve that, we can ask multiple labelers to label the same examples, and when there is a disagreement,
- We can identify it and discuss the definition of y to reach a new agreed definition.
- We might also encounter cases where we need to consider changing X as it might not have enough information.
After identifying the issues with the labels, we can use that information to update the labeling instructions. This process can be repeated until it is hard to increase agreement significantly.
Some results from such an iterative process can include,
- Standardizing the labels so that the labels become consistent.

- Merge some of the classes in y. To achieve cleaner labels.

- We also see cases where we add a new label to determine the uncertainty.
— In the above example of different kinds of scratches, we can try and assign the scratches with values between 0 and 1 to determine the class.
— Or, in the example of the transcription given earlier, we can add a new tag called ‘unintelligible’ as a Boolean value.
We can also have a voting mechanism to make the labels more consistent.
Human Level Performance
We have already seen why Human-Level Performance is important in the previous articles. One more interesting and important use for HLP is to estimate what is possible with the project.
Let us look at a scenario to understand more about this. Say you have ground truth labels for your project, and now your supervisor has given you the task of developing a model with an accuracy of 99%. To first check whether the 99% is possible, it is essential to see how a human performs on this task.
Suppose the HLP is only 85%; then, it is not easy for you to develop a model that can achieve 99% accuracy. This is one advantage of establishing a baseline before we start modeling without any direction. However, this entire premise depends on what the ground-truth label is.
When the ground truth is some actual drought-proof ground truth, then HLP can be used to measure the performance of a person and a model. However, when the ground-truth label is defined by another human, the HLP is actually a measure of one person predicting another person’s outcome.
In identifying HLP, if it is much worse than the perfect performance, then one of the most common causes is the ambiguity of the labeling instructions.
In summary,
- HLP is used in academia to establish and beat an excellent benchmark to support the publication.
- HLP is a more reasonable target for business or product performance than a random number like 99% or 98%
However, there can also be some misleading use of this baseline to support ML superiority over Human-Level Performance and the settings where the goal was to build a practical application.
Until now, we have seen how we define the data, set the baselines, and the common issues in that process. Let us look at how we actually go about obtaining the data.
Some of the common tips for obtaining data,
- Get into the modeling iteration as fast as possible in the initial stages of the product. Based on the error analysis, we can go back and see if we need more data than we have already collected.
- Instead of searching for the initial data indefinitely, set a small window, like a week, and try to find as quality data as possible within the window. However, if you have experience with a similar project, you know precisely how much time you need.
- Make an inventory data, where you brainstorm the list of possible data sources, the cost of attaining the data, the time needed, and the quantity of the data that can be obtained. Based on that, make necessary decisions. Other vital factors are data quality, privacy, and regulatory constraints.
There is no best data source for all projects, depending on the application, the quality of the data needed, and the source of the data chosen. For example, we might have to select in-house data or purchase data from factories for a project like a factory inspection or medical image diagnosis. Then let subject experts generate the labeling instructions or do the labeling. For Recommender systems, no matter the source, it is generally hard to label the data. Hence, there are many factors that go into choosing the source of the data and choosing the right person to label the data.
Managing Data Pipelines
Data pipelines or cascades refer to the multiple steps of data processing before reaching the final data required for modeling. However, when we speak about data processing, we need to be more detailed, as there are actually 2 areas where we process the incoming data.
- Pre-processing for modeling: The first phase is relatively simple, as we need to go through a few pre-processing steps, be it computer scripts or manual processing, and use that processed data to train an ML model.
- Pre-processing the input data in production: The processing of input data from users should be done to replicate the distribution of the data on which the model is trained. However, generating accurate replicate scripts for production is only partially possible. Hence, we try and approximate the distributions as much as possible.
In practice, it is recommended to follow 2 phases for any ml project. The first phase is the POC phase (as discussed in our previous notes) and the production phase. For the POC phase, it is recommended that you do whatever processing steps necessary to get the model to work without worrying about the ability to replicate. (Of course, you should maintain extensive notes.)
After the project utility is established, we should use more sophisticated tools to make the data pipeline replicable. Some libraries/tools, like TensorFlow Transform, Apache Beam, etc., are recommended based on preference.
Metadata, Data Provenance, and Lineage
Most of the pipelines in production are so large and complex, unlike the simple systems we have seen until now. For each application, we have to move through different systems while trying to maintain the quality of our results.
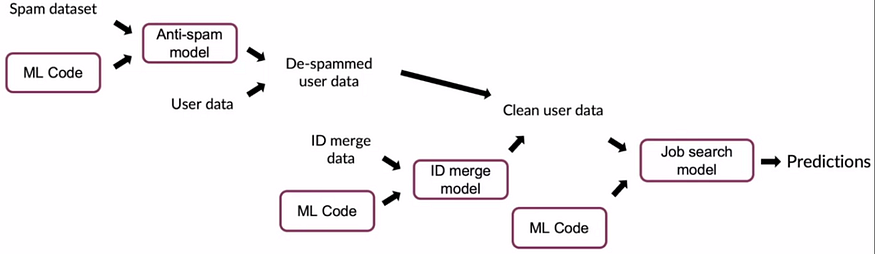
The above image is an example where multiple systems are linked and trained so that we can get a job recommendation. There are far more complex systems that are currently used in production, which have even deeper trees. In this case, imagine what we must do if we find that some part of the initial steps (say in the spam dataset) needs to be changed due to recently discovered errors. What should we do?
To go back and fix this problem, we need to go through files developed by different people and teams. Hence, to ensure the system is maintainable, it is helpful to keep track of data provenance and lineage.
- Data provenance — Where the data comes from
- Data lineage — Sequence of steps in the pipeline.
For managing data pipelines and error analysis for the projects, it is also recommended to maintain extensive metadata for each project step. For example,
- In a visual inspection project, the data would be pictures about different devices; the meta-data store information about the time the photo was taken, the factory at which it was taken, device model, Inspector id, etc.,
- In a speech recognition system, the data would be recorded audio in mobile phones, whereas meta-data would be the model of the phone, the version of the VAD model, Network conditions for audio file transmission, etc.,
Maintaining and keeping track of meta-data, data provenance, and data lineage is recommended for better analysis and sustainability of the model pipeline.
Man! Even writing about this topic was dry for me! In actual practice, it feels way more interesting as you can directly see different problems arising in the data. (It will also be frustrating, though!). If you think this is a drag, imagine how many hours were spent training the models behind the current, everyone’s favorite ChatGPT! When I think about that, my appreciation for OpenAI rises to a new level.
Even when reading this short article, you can find many grammatically ambiguous statements and punctuation that need to be corrected. But, these people have trained a model that can generate statements without ambiguity while maintaining punctuational accuracy.
Anyway! I would originally have divided this long article into 2 different parts, but I wanted to compensate for my last week’s delay and cover the entire phase in a single step so that I won’t be behind my schedule. Hope you like this one, and if you haven’t read my previous articles in this series, I hope you will go ahead and check them. Meanwhile, follow me for more frequent updates, and stay tuned for more articles!
By the way, feel free to checkout my website, NeuroNuts! I plan to add all my ideas and some detailed articles here!
Originally published at https://www.neuronuts.in on February 5, 2023.
MLOps 3.3: Data-Centric Approach for Machine learning modelling.
Learn about the “Data-centric” machine learning modelling approach and its standard procedures here.
pub.towardsai.net
NeuroNuts
For those with a burning desire to put their enthusiasm for ML and Data Science to a good use, there must be clear and…
www.neuronuts.in
Akhil Theerthala – Medium
Read writing from Akhil Theerthala on Medium. Machine Learning Enthusiast U+007C Data Enthusiast U+007C AI Enthusiast U+007C. Every…
medium.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



