



Data Labeling: Why It’s So Important for Machine Learning Success
Last Updated on February 5, 2023 by Editorial Team
Author(s): Hrvoje Smolic
Originally published on Towards AI.
Are you tired of feeling like a tiny ant in a giant data jungle? You’re not alone. Businesses of all sizes struggle to make sense of the massive amounts of data they collect daily. But what if I told you there’s a way to turn that jungle into a beautiful, well-maintained garden? Enter no-code predictive analytics.
Imagine predicting customer behavior, optimizing marketing strategies, and making data-driven decisions without writing a single line of code. Sounds too good to be true? It’s not.
No-code predictive analytics software allows even the least tech-savvy person to harness the power of their data.
But why is this important? Let’s use the example of a small business owner. They’re busy running their business and don’t have the time or resources to learn how to code. But they still want to make data-driven decisions to improve their sales and customer satisfaction. With no-code predictive analytics, they can easily access their data and make predictions without needing to hire a team of data scientists.
But don’t just take my word for it. According to a recent survey, 72% of businesses reported a significant increase in revenue after implementing no-code predictive analytics. And it’s not just for small businesses — even large companies are jumping on the no-code train. By 2025, the no-code market is expected to reach $15 billion.
So don’t get left behind in the data jungle. Join the no-code revolution and turn your data into a beautiful garden. With no-code predictive analytics, anyone can become a data wizard and make informed decisions to drive their business forward.
Today, we’ll dive deeply into three compelling examples of how no-code predictive analytics can benefit your business.
First up, let’s talk about predictive lead scoring. Imagine you’re a salesperson trying to figure out which leads are the most promising to follow up with. It’s like trying to find a needle in a haystack, right? But with predictive lead scoring, you can use your data to identify which leads are most likely to convert into customers. It’s like having a treasure map that guides you straight to the golden nuggets.
Next, we’ll explore predictive churn. Churn is the bane of every business, but with predictive analytics, you can predict which customers are most at risk of leaving. Think of it like a weather forecast for your customer base — you can prepare and take action before the storm hits.
Last but not least, we’ll dive into predictive credit scoring. Credit scoring is essential for businesses that lend money, but it can be complex. With no-code predictive analytics, you can use your data to predict which customers are most likely to default on their loans. It’s like having a crystal ball that predicts the future of your loan portfolio.
So there you have it, three compelling examples of how no-code predictive analytics can benefit your business.
Whether you’re trying to identify the most promising leads, predict customer churn, or forecast loan defaults, no-code predictive analytics can help you make better decisions and achieve better outcomes.
Stay tuned for more insights on how to use no-code predictive analytics to your advantage!
Data labeling — why is it so important?
Data is the key ingredient to any successful machine-learning process. But like any cake recipe, the data ingredient needs to be appropriately labeled for the machine learning experiment to yield the best results.
Data labeling is the crucial process that enables computers to understand what data is being represented.
Without data labels, any given dataset could look like a jumble of numbers, words, and characters to machines, and understanding what each piece of data means is impossible.
So, how do you properly label data?
One of the most effective ways to label data is using human intelligence. By leveraging humans who understand the question and the data being analyzed, machines can be given the contextual understanding of data that is so important for a machine learning algorithm to comprehend. However, humans are only able to provide labels for data when there is a given context or understanding.
Data labeling services are designed to help supplement knowledge or context-based labels given by humans. These services provide the proper labels for either not contextual or inadequately labeled data. Data labeling services are often provided by third-party data labeling companies or through automated techniques like active learning.
Humans are most often used when the data being labeled has many classes that need to be identified and labeled.
Automated techniques are most commonly used for data with high volumes but are less complex.
Using data labeling to ensure that a machine learning algorithm is adequately trained is essential for getting accurate results. Data labeling gives machines the contextual understanding that is necessary for learning and making accurate predictions in machine learning experiments.
With data labeling, the machine can understand the information provided and accurately make predictions.
Data labeling is the first step to successful machine learning. The more accurate and precise the labels, the more successful the machine learning results. So, suppose you want your machine learning experiment to be successful and accurate. In that case, you need to make sure you invest plenty of time into ensuring your data is labeled well.
Without data labeling, your machine-learning experiment will never be able to yield the results you want.
Labeled Dataset For Predictive Lead Scoring
Predictive lead scoring is like a crystal ball for businesses. It allows companies to predict which leads are most likely to convert into paying customers. But, it needs the correct information to give accurate predictions. That’s where data labeling comes in.
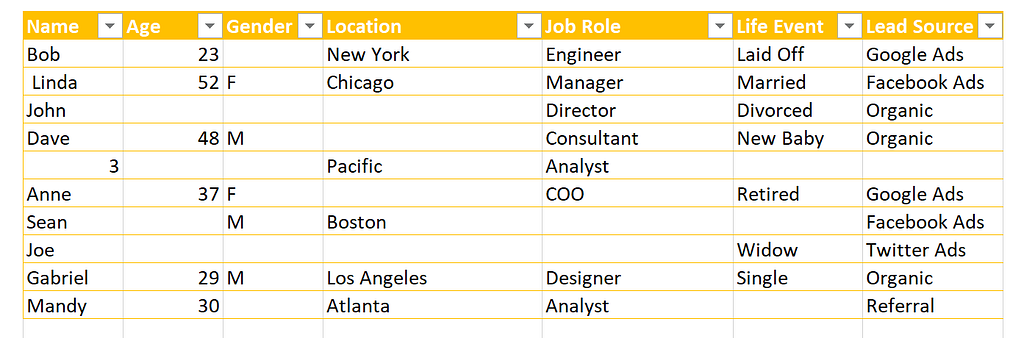
Imagine you’re a salesperson trying to predict which leads will convert. Your boss gives you a list of leads to work with, but it could be in better condition.
Some leads are missing information, and the “converted” column is inconsistent. Some say “yes,” some say “no,” and some say nothing at all. It’s like trying to predict the future with a cloudy crystal ball — you can make an educated guess, but you can’t be sure.
Now, imagine you have a team of data labelers cleaning up that list. They fill in missing information and ensure the “converted” column is consistent. Looking at that list, it’s like the crystal ball is finally clear. You have a foundation to see which leads are most likely to convert with much more accuracy.
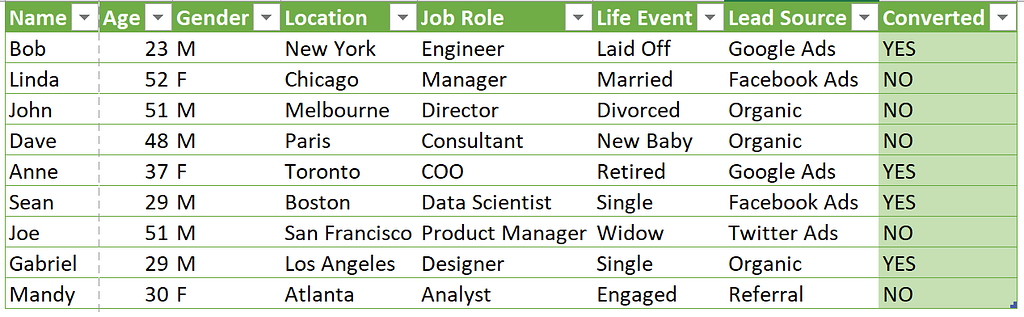
Proper data labeling is like giving your predictive lead scoring model a crystal clear view of the future. It provides clear and consistent labels, especially for the target column, which in this case is “converted.”
With an adequately labeled dataset, the predictive model can make accurate predictions and is now ready for predictive analytics.
The benefits of a properly labeled dataset with a target column are numerous. It allows businesses to prioritize their efforts, focusing on the leads that are most likely to convert. It also helps them identify patterns and trends in their customer base that they may have missed. Additionally, it allows for more efficient use of resources since companies can save time and money on leads that are unlikely to convert.
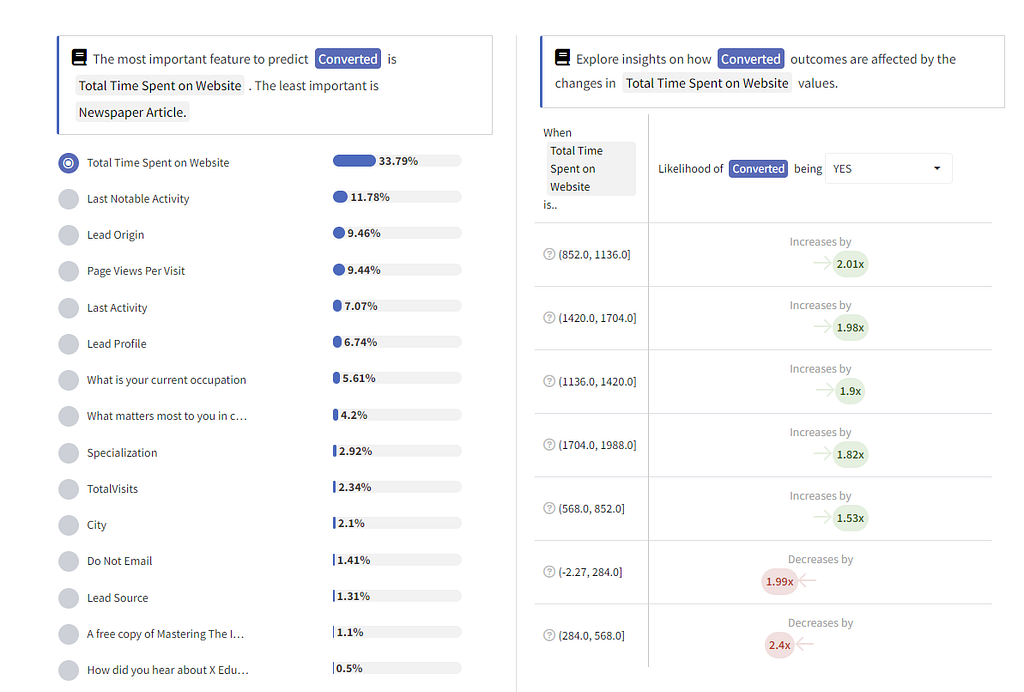
You can see a Live Demo of Predictive Lead Scoring here.
Labeled Dataset For Predictive Customer Churn
Predictive customer churn. It sounds like something out of a sci-fi movie, but it’s actually a valuable tool for businesses. Imagine having a tool that could predict which customers will likely leave your company soon. That’s exactly what predictive churn does.
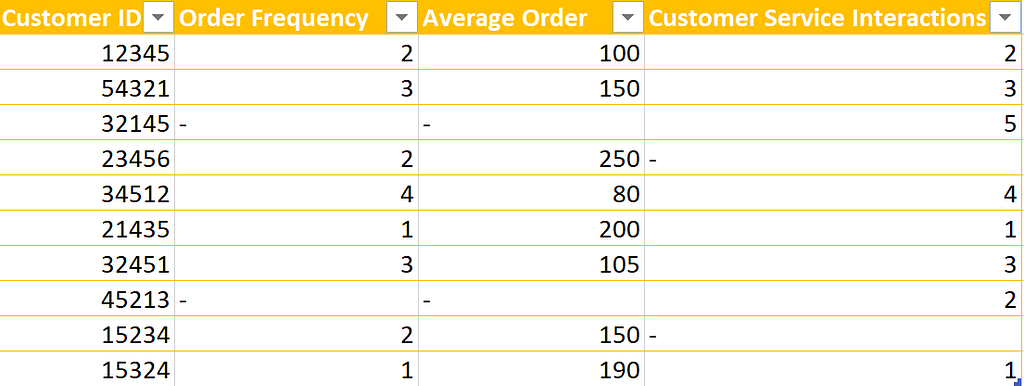
But before using this crystal ball, you need to ensure it’s properly calibrated. And that’s where data labeling comes in.
Let’s say you have a dataset with customer information, including their purchase history and customer service interactions. But it’s missing important data, and the labels for whether or not a customer has churned are inconsistent.
This is like trying to predict the weather with a broken thermometer. You might get a general idea, but it will need to be more accurate.
Proper data labeling can improve the accuracy of your predictive churn model by providing precise and consistent labels. Imagine if your thermometer was working perfectly, you would be able to accurately predict the weather.
The same applies to predictive churn. By providing a consistent target column — Churn YES / NO — your model can predict customer churn with great accuracy.

Now let’s look at an example of a dataset after proper data labeling.
All customer information is complete and consistent, and the target column clearly indicates whether or not a customer has churned.
But the benefits of adequately labeled data continue beyond there. With a clear target column, your dataset is now ready for predictive analytics. You can use it to identify patterns and trends in customer behavior and make informed decisions about retaining your best customers.
So don’t let dirty data tarnish your predictions. Invest in proper data labeling for a successful predictive churn journey.
You can see Live Demo of Predictive Customer Churn here.
Labeled Dataset For Predictive Credit Scoring
Predictive credit scoring predicts which customers will most likely take out a loan or credit. It’s like having a superhero power to know who will most likely trust you with their money. But, like any superpower, it needs to be used correctly and with the right tools. That’s where data labeling comes in.
Imagine you’re a business trying to predict which customers will most likely take out a loan. You have a dataset with information about your customers — their income, credit score, etc. But something needs to be added.
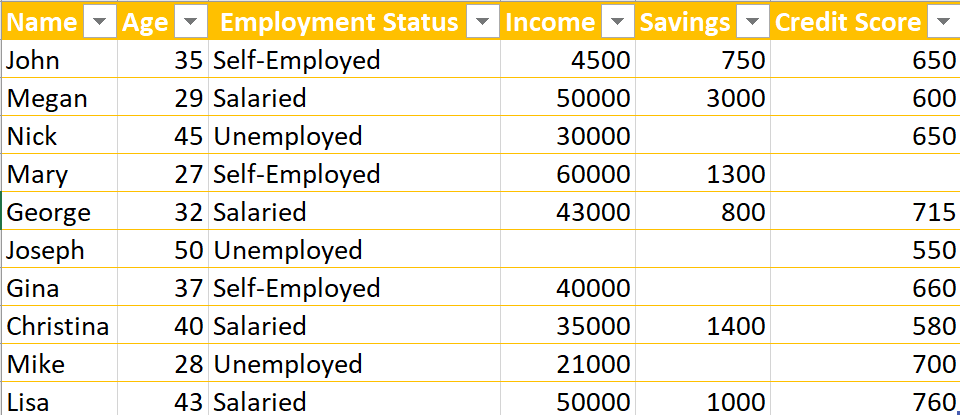
The target column — the one that tells you whether or not a customer has taken out a loan — is missing or inconsistent. It’s like trying to predict the weather without knowing whether it’s raining or sunny. You might make a guess, but you’re not going to be very accurate.
Now, imagine that same dataset but with proper data labeling. The target column is clear and consistent. It’s like having a weatherman who tells you whether it’s raining or sunny. You know exactly what to expect and can make much more accurate predictions.
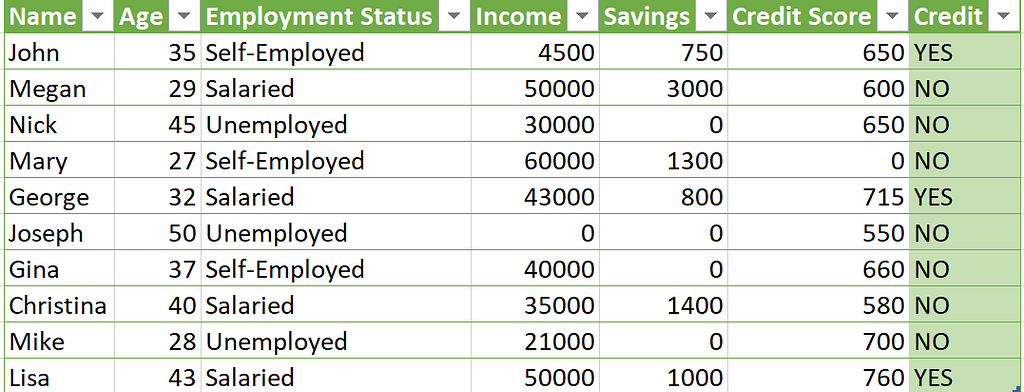
Data labeling is like adding a compass to your predictive credit scoring journey. It helps you navigate through the data and find the patterns you need to make accurate predictions. With proper data labeling, your dataset is like a treasure map — it shows you where the gold is.
Predictive credit scoring is like a superpower for businesses, and data labeling is the key to unlocking its full potential. It’s like having a weatherman and a compass on your journey — it helps you navigate through the data and find the patterns you need to make accurate predictions. With proper data labeling, your dataset is like a treasure map, and you can use predictive analytics to dig deeper and find even more valuable insights. Don’t let your predictive credit scoring journey be like a wild goose chase — invest in proper data labeling and turn it into a treasure hunt.
Conclusion
Data labeling may seem like an insignificant part of the machine learning journey, but it’s essential for success. Think of it like cooking — before you can whip up a tasty dish, you need to know what ingredients you have and how to prepare them. It’s the same with your ML project — you must understand the data you’re working with before doing anything else.
Data labeling is the process of sorting and categorizing vast amounts of raw data into uniform labels, allowing the ML algorithm to identify patterns and make accurate predictions. Labeling data specifically for a machine learning project ensures that the data is of higher quality and accuracy. By ensuring specific attributes or features are tagged or labeled, ML algorithms can more efficiently make sense of vast amounts of data.
More accurate data labeling also means more accurate and valuable machine learning results. Properly labeled data give the ML project a basis to study, while improper labeling can lead to unfounded results or invalid conclusions. The ML algorithm then relies on these correctly labeled components to recognize objects properly and make valuable predictions.
Not only will data labeling make your machine learning results more accurate, but it can also save you significant development time. By properly labeling your data, you can easily adjust the ML algorithms used in your project for results that more closely match your needs. For instance, you can use different labels for different customer segments or market sizes to pull insights more quickly and accurately.
Investing in proper data labeling for ML projects will lead to accurate and trustworthy results. If data labels are not properly applied, the ML algorithms can be misled by distracting or irrelevant data patterns and cannot effectively discern meaningful information.
With reliable, correctly labeled data, ML algorithms can jump-start the predictive process more confidently.
Don’t let bad data labeling be the floor tile of your ML journey.
Good data labeling provides the foundation for success and will make all the difference in guaranteeing accurate and meaningful machine-learning results. Invest in proper data labeling and make sure it stands as the foundation of your ML project.
Data labeling is an essential part of machine learning success. It ensures that the data used to train models is accurate and relevant and can prevent errors and improve the performance of machine learning models. With the latest technologies, such as artificial intelligence and deep learning, data labeling is evolving and can help improve the accuracy of data labeling.
Investing in proper data labeling is key to achieving the best results from machine learning models. If you’re looking to get the most out of your machine learning models, consider trying no-code machine learning tools to predict your labeled data without writing a single line of code.
Reach out if you need any help!
Like the content? Let’s connect.
If you believe this article is worth sharing, spread the word and help others discover its value.
Fun tip: Try clicking the clap button for the magic to happen! ❤️
You can get in touch with me on LinkedIn.
Originally published at Graphite Note Blog on January 16, 2023.
Data Labeling: Why It’s So Important for Machine Learning Success was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


