



Mastering the Bias-Variance Dilemma: A Guide for Machine Learning Practitioners
Last Updated on July 25, 2023 by Editorial Team
Author(s): Chinmay Bhalerao
Originally published on Towards AI.
The Yin and Yang of Machine Learning: Balancing Bias and Variance
The bias-variance tradeoff is a fundamental concept in machine learning and statistics that relates to the ability of a model to accurately capture the underlying patterns in a dataset. In essence, the bias-variance tradeoff refers to the balance between the complexity of a model and its ability to generalize to new, unseen data.
We have data that we use for training, and we also have data that we use for testing. There is very less chance that the prediction of the model or estimator is exactly the same as of real output because of many other things and unseen data involved. so how to decide whether these predictions are acceptable or not? for that, we can decide on a certain set of rules. But before going further, let's understand,
What is BIAS?
Bias refers to the degree to which a model is able to accurately capture the underlying patterns in a dataset.
“The diversion from original answer is known as Bias”
More the diversion, the higher the bias. Brut-forcibly speaking, the inability of the algorithm to capture the real relationship of the dataset distribution is called bias.
when We say our predictor is unbiased if
E(θ_estimator) = θ_original
The bias of the estimator is defined as
bias(θ_estimator) = Eθ(θ_estimator) − θ.
The difference between fits between data sets is called variance. A model with high bias is said to be underfitting the data, as it is not able to capture the complexity of the true underlying relationship. In other words, the model is too simplistic and cannot capture all the relevant features in the data. This can lead to poor performance on both the training data and new, unseen data.
What is VARIANCE?
Variance refers to the degree to which a model is able to adapt to new data.
The variance measures the “spread” of a distribution.
Let X be a random variable with mean µ. The variance of X — denoted by σ2 or σ2 X or V(X) or VX — is defined by
σ2 = E(X − µ) 2 =INTEGRATION(x − µ) **2dF(x)
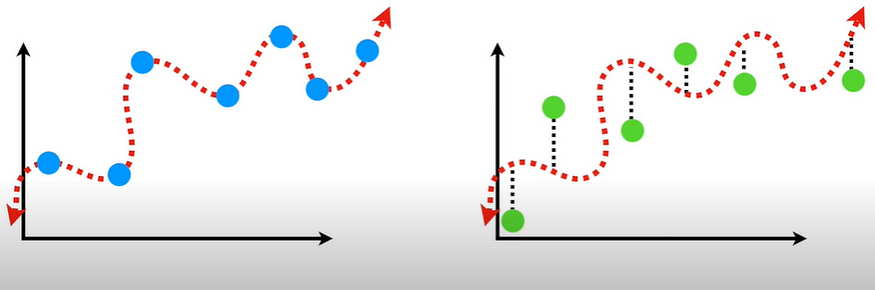
a variance is a measure of how far a set of data (numbers) are spread out from their mean (average) value. Variance means to find the expected difference of deviation from the actual value. A model with high variance is said to be overfitting the data, as it is too complex and has learned to fit the noise in the training data as well as the underlying patterns. In other words, the model is too flexible and captures all the irrelevant features in the data. This can lead to excellent performance on the training data but poor performance on new, unseen data.
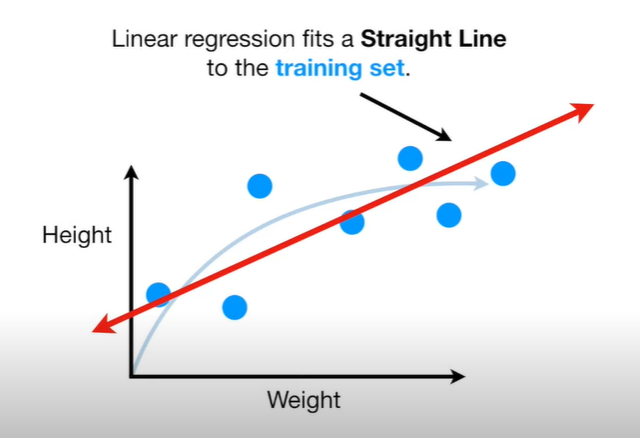
Bias-variance tradeoff
The bias-variance tradeoff arises because it is difficult to simultaneously minimize both bias and variance. As the complexity of a model increases, its bias decreases, but its variance increases. Conversely, as the complexity of a model decreases, its bias increases, but its variance decreases. The optimal level of complexity for a model depends on the specific problem and the available data.
To illustrate this tradeoff, consider the problem of fitting a polynomial curve to a set of data points.
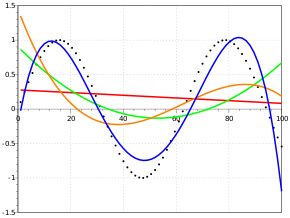
A simple linear model will have high bias, as it cannot capture the curvature of the data. However, a high-degree polynomial model will have high variance, as it will fit the noise in the data and be overly complex. The optimal degree of the polynomial model will depend on the specific data and problem at hand.
One way to visualize the bias-variance tradeoff is through the bias-variance decomposition of the mean squared error (MSE) of a model. The MSE is the average squared difference between the predicted values and the true values in the data. The bias-variance decomposition of the MSE separates the error into a bias component, a variance component, and an irreducible error component that cannot be reduced by the model.
More specifically, we can use mathematical terms to define bias and variance.

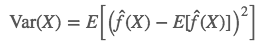
Bias is the difference between the true label and our prediction, and variance is defined in Statistics as the expectation of the squared deviation of a random variable from its mean. Here, f represents the model in the true world. There exists random noise that we cannot avoid, which we represent ϵ. The true label is represented by

And we can compute the error.

The bias-variance tradeoff has important implications for model selection, regularization, and ensemble methods in machine learning. One common approach to minimizing the tradeoff is to use a regularization technique such as L1 or L2 regularization to penalize overly complex models. Another approach is to use ensemble methods such as bagging or boosting, which combine multiple models to reduce the variance while maintaining low bias.
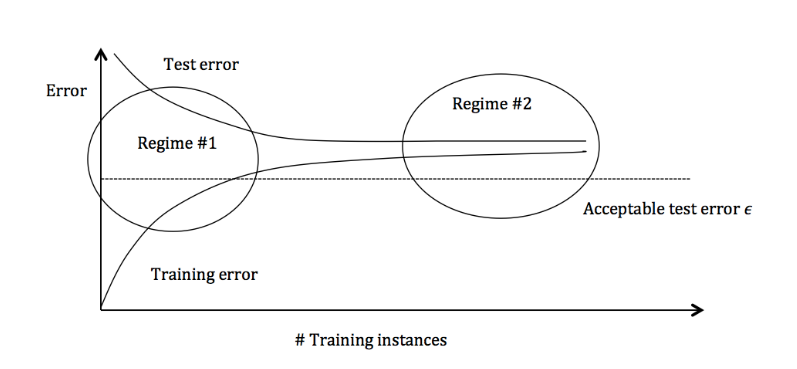
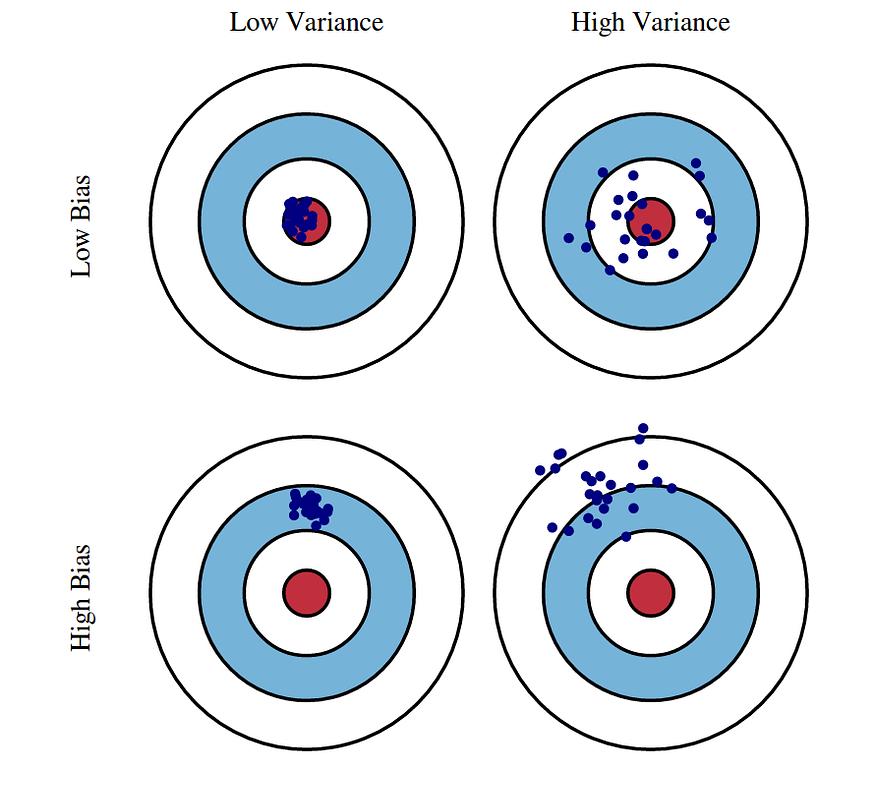
Detecting High Bias and High Variance
High Variance
The cause of the poor performance is high variance.
Symptoms:
- Training error is much lower than test error
- Training error is lower than the desired error threshold
- Test error is above the desired error threshold
Remedies:
- Add more training data
- Reduce model complexity — complex models are prone to high variance
- Bagging
High Bias
the model being used is not robust enough to produce an accurate prediction.
Symptoms:
- Training error is higher than the desired error threshold
Remedies:
- Use more complex model (e.g., kernelize, use non-linear models)
- Add features
- Boosting
If you want more detail and with python code explanation then you can refer blog of machinelearningmastery
In summary,
The bias-variance tradeoff is a fundamental concept in machine learning and statistics that relates to the balance between the complexity of a model and its ability to generalize to new, unseen data. A model with high bias is too simplistic and underfits the data, while a model with high variance is too complex and overfits the data. The optimal level of complexity for a model depends on the specific problem and the available data and can be managed through techniques such as regularization and ensemble methods.
References :
- Lecture 12: Bias-Variance Tradeoff
- machinelearningplus
- k-nearest-neighbors-and-bias-variance-tradeoff-
- the-bias-variance-tradeoff-
- 5minutesengineering
If you have found this article insightful
It is a proven fact that “Generosity makes you a happier person”; therefore, Give claps to the article if you liked it. If you found this article insightful, follow me on Linkedin and medium. You can also subscribe to get notified when I publish articles. Let’s create a community! Thanks for your support!
You can read my other blogs related to :
Unlock Your Data’s Potential with Data Science
A bird-eye view introduction of everything about data science
pub.towardsai.net
Comprehensive Guide: Top Computer Vision Resources All in One Blog
Save this blog for comprehensive resources for computer vision
medium.com
YOLO v8! The real state-of-the-art?
My experience & experiment related to YOLO v8
medium.com
Feature selection techniques for data
Heuristic and Evolutionary feature selection techniques
medium.com
Signing off,
Chinmay
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

