



Parametric ReLU | SELU | Activation Functions Part 2
Last Updated on July 25, 2023 by Editorial Team
Author(s): Shubham Koli
Originally published on Towards AI.
Parametric ReLU U+007C SELU U+007C Activation Functions Part 2
What is Parametric ReLU ?
Rectified Linear Unit (ReLU) is an activation function in neural networks. It is a popular choice among developers and researchers because it tackles the vanishing gradient problem. A problem with ReLU is that it returns zero for any negative value input. So, if a neuron provides negative input, it gets stuck and always outputs zero. Such a neuron is considered dead. Therefore, using ReLU may lead to a significant portion of the neural network doing nothing.
Note: You can learn more about this behavior of ReLU here.

Researchers have proposed multiple solutions to this problem. Some of them are mentioned below:
- Leaky ReLU
- Parametric ReLU
- ELU
- SELU
In this Answer, we discuss Parametric ReLU.
Parametric ReLU
The mathematical representation of Parametric ReLU is as follows:
Here, yi is the input from the i th layer input to the activation function. Every layer learns the same slope parameter denoted as αi. In the case of CNN, i represents the number of channels. Learning the parameter, αi boosts the model’s accuracy without the additional computational overhead.
Note: When αi is equal to zero, the function f behaves like ReLU. Whereas, when αi is equal to a small number (such as 0.01), the function f behaves like Leaky ReLU.
The above equation can also be represented as follows:
f (yi) = max (0, yi) + αi min (0, yi)
Using Parametric ReLU does not burden the learning of the neural network. This is because the number of extra parameters to learn is equal to the number of channels. This is relatively small compared to the number of weights the model needs to learn. Parametric ReLU gives a considerable rise in the accuracy of a model, unlike Leaky ReLU.
If the coefficient αi is shared among different channels, we can denote it with a α.
f (yi) = max (0, yi) + α min (0, yi)
Parametric ReLU vs. Leaky ReLU
In this section, we compare Parametric ReLU with the performance of Leaky ReLU.
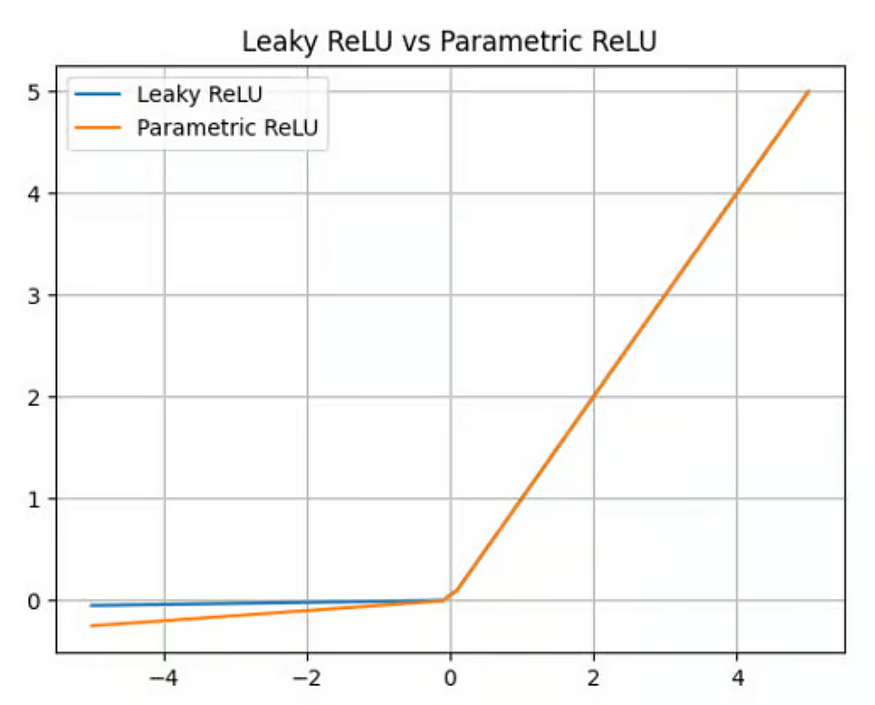
Here, we plot Leaky ReLU with α = 0.01 and have Parametric ReLU with α = 0.05. In practice, this parameter is learned by the neural network and changes accordingly.
Implementation with Python
import numpy as np
def PReLU(z,α) :
fn =np.max(αz,z)
return(fn)
Advantages:
1. Increase inaccuracy of the model and faster convergence when compared with the model having LReLU and ReLU.
Disadvantages:
1. The user has to manually modify the parameter α by trial and error.
2. For different applications, different α would be required, finding which is time-consuming
3. For every negative input, the gradient remains the same irrespective of the magnitude. This implies during backpropagation, learning occurs equally for the whole range of negative inputs.
What is SELU?
SELU is a self-normalizing activation function. It is a variant of the ELU . The main advantage of SELU is that we can be sure that the output will always be standardized due to its self-normalizing behavior. That means there is no need to include Batch-Normalization layers.
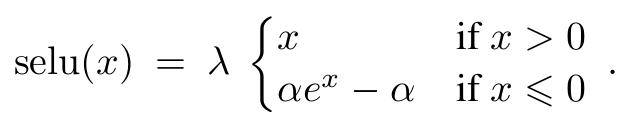
Where λ and α are constants with values:
λ ≈ 1.0505
α ≈ 1.6732
Implementation with Python
# Implementation of SELU in Python
import numpy as np
import matplotlib.pyplot as plt
# initializing the constants
λ = 1.0507
α = 1.6732
def SELU(x):
if x > 0:
return λ*x
return λ*α*(np.exp(x) - 1)
x = np.linspace(-5.0, 5.0)
result = []
for i in x:
result.append(SELU(i))
plt.plot(x, result)
plt.title("SELU activation function")
plt.xlabel("Input")
plt.ylabel("Output")
plt.grid(True)
plt.savefig('output/selu_plot.png')

What is normalization?
SELU is known to be a self-normalizing function, but what is normalization?
Normalization is a data preparation technique that involves changing the values of numeric columns in a dataset to a common scale. This is usually used when the attributes of the dataset have different ranges.
There is 3 types of normalization:
- Input normalization: One example is scaling the pixel values of grey-scale photographs (0–255) to values between zero and one
- Batch normalization: Values are changed between each layer of the network so that their mean is zero and their standard deviation is one.
- Internal normalization: this is where SELU’s magic happens. The key idea is that each layer keeps the previous layer’s mean and variance.
Advantages of SELU
- Like ReLU, SELU does not have vanishing gradient problem and hence, is used in deep neural networks.
- Compared to ReLUs, SELUs cannot die.
- SELUs learn faster and better than other activation functions without needing further procession. Moreover, other activation function combined with batch normalization cannot compete with SELUs.
Disadvantages of SELU
- SELU is a relatively new activation function so it is not yet used widely in practice. ReLU stays as the preferred option.
- More research on architectures such as CNNs and RNNs using SELUs is needed for wide-spread industry use.
“Activation Functions” in Deep learning models. How to Choose?
Sigmoid, tanh, Softmax, ReLU, Leaky ReLU EXPLAINED !!!
medium.com
The Dying ReLU Problem, Causes and Solutions
Keep your neural network alive by understanding the downsides of ReLU
medium.com
If you liked this Blog, leave your thoughts and feedback in the comments section, See you again in the next interesting read!
U+1F600 Happy Learning! U+1F44F
Until Next Time, Take care!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

