



Machine Translation, but Unsupervised
Last Updated on July 25, 2023 by Editorial Team
Author(s): Yunzhe Wang
Originally published on Towards AI.
Decoding the Intricacies of Unsupervised Neural Machine Translation: A Deep Dive into its Mechanisms and Potential
In the ever-evolving landscape of machine translation, Unsupervised Neural Machine Translation (UNMT) is making waves as a game-changer for the industry. This innovative sub-field focuses on training translation models without the need for parallel data, utilizing the vast reservoirs of monolingual data now available. As large-scale language models become increasingly accessible, UNMT is poised to redefine the way we approach translation tasks.
In this post, we’ll explore the building blocks of UNMT, including word embedding pre-training and latent space alignment, as well as how techniques like back-translation can help refine the process.
Neural Machine Translation (NMT)
Neural Machine Translation (NMT) refers to the use of artificial neural networks to translate text from one language to another. It has achieved significant performance in recent years due to its ability to handle complex and variable sentence structures and to improve the quality of translations compared to traditional statistical machine translation methods. NMT typically involves large-scale neural networks trained on large parallel sentence-pair datasets in different languages. Nonetheless, parallel corpora are scarce resources for most language pairs, while it’s not the case for monolingual data, which are much more available for each language. Studies in Unsupervised Neural Machine Translation (UNMT) point toward a promising direction for machine translation research and even improving translation model performance in the absence of parallel data.
Most successful techniques for unsupervised machine translation require two steps. 1) separately pre-train source and target languages for word embeddings and 2) learn a transformation function that allows the alignment of word embedding. The aligned word embedding creates a synthetic dictionary between the two languages, where words with the same meaning can be matched through nearest neighbor search, thus enabling unsupervised word-to-word translation. Techniques such as Back-Translation then allow alignment at the sentence level and improve translation performance beyond word-to-word.
Word Embedding
Word embedding represents words in a continuous vector space, where semantically similar words are mapped to nearby points in the space. Most successful techniques for learning word representations are based on the linguistic distributional hypothesis of Harris, which states that a word that appears in the same context conveys a similar meaning.
One surprising aspect of deriving word embeddings through neural networks is that the resulting word vectors exhibit approximately additive compositionally. Check out an explanation post about word2vec by Vatsal.
Word2Vec Explained
Explaining the Intuition of Word2Vec & Implementing it in Python
towardsdatascience.com
Adding two-word vectors together often results in a vector closest to the vector representing the composite of the added words. For example, adding the vectors for “man” and “royal” results in a vector that is closest to the vector for “king.” This property allows us to use these vectors to answer word analogy questions using algebraic methods. For instance, to answer the question “Man is to the king as woman is to ?” one can return the word whose vector is closest to the vector obtained by subtracting the “man” vector from the “king” vector and adding the “woman” vector.
Matrix Factorization Methods
- Latent Semantic Analysis (LSA): This is a technique in natural language processing that analyzes relationships between a set of documents and the terms they contain. It does this by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text.
- Latent Dirichlet Allocation (LDA): LDA is a generative statistical model that allows sets of observations to be explained by unobserved groups. In the context of text modeling, these unobserved groups are topics, and the observations are the words in the documents. So, LDA helps in discovering topics that these documents contain.
- Global Vectors (GloVe): GloVe is an unsupervised learning algorithm for obtaining vector representations for words. It leverages both global statistical information (aggregated from the entire corpus) and local information (from the neighboring words) to create word vectors. These vectors capture the semantic meaning of words, whereas words with similar meanings have vectors that are close together in the vector space.
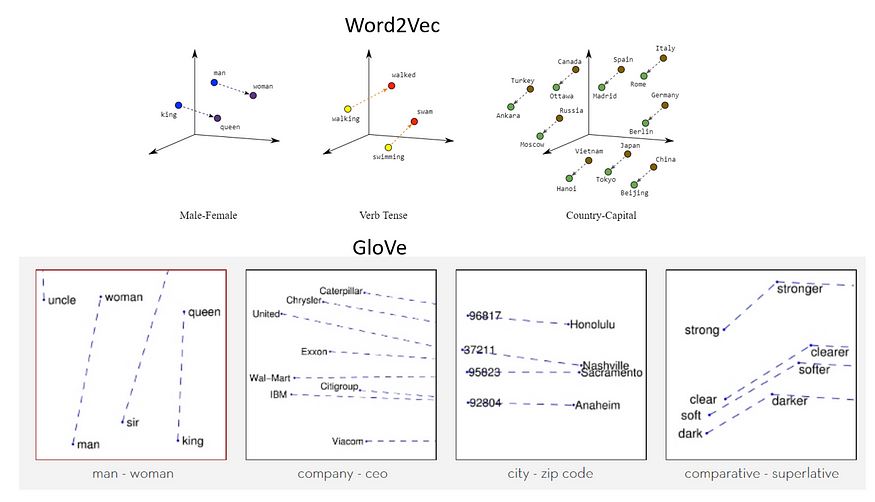
Local Context Window Methods
- Word2Vec: Word2Vec uses a shallow neural network with a single hidden layer. The input to the network is a one-hot encoded vector representing the input word, and the output is a set of probabilities for each word in the vocabulary. The hidden layer contains the word vectors, which are learned during training.
Two main algorithms are used in word2vec: the continuous bag-of-words (CBOW) model and the skip-gram model. The CBOW model tries to predict the current word given the surrounding words, while the skip-gram model tries to predict the surrounding words given the current word. Both algorithms can be effective, but the skip-gram model is generally considered to perform better with larger datasets. - FastText: FastText is a similar word representation learning technique as compared to Word2Vec. It is particularly useful for working with large text datasets because it is computationally more efficient. Unlike Word2Vec, FastText uses hierarchical softmax, a faster method for training word vectors than the traditional softmax approach. Also, FastText uses sub-word information, which allows it to create vectors for out-of-vocabulary words by combining the vectors of their component subwords. This makes FastText effective at handling rare words and words with spelling variations. For example, the embedding of the word “cat” would be represented as a single vector if using Word2Vec, whereas FastText uses a combination of the character n-grams “c,” “ca,” “cat,” “a,” “at,” and “t.”
Denoising Auto-Encoding
A de-noising autoencoder (DAE) is trained to reconstruct a clean “repaired” input from a corrupted version of it. This is done by corrupting the initial input by adding text noises. Common noises include:
- Token Masking: Randomly replace word tokens in a sentence with a mask token [MASK]. The task is commonly known as Masked Language Modeling (MLM).
- Token Deletion: Randomly delete word tokens in a sentence. Note the difference between token masking and token deletion is that the former preserves sentence length while the latter does not.
- Token Permutation: Randomly shuffle word orders in a sentence.
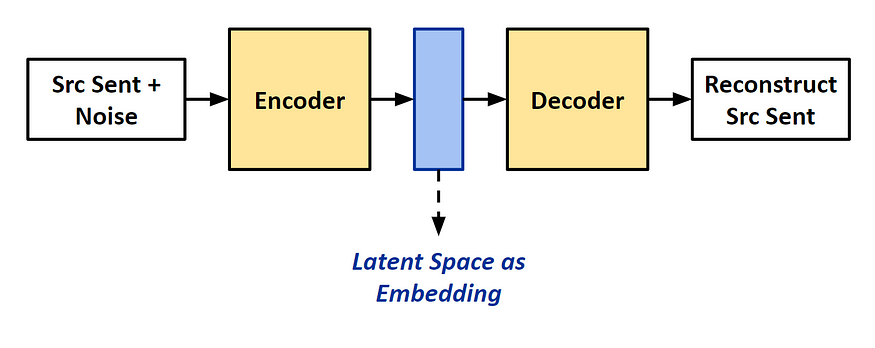
Latent Space Alignment
Mikolov observed that the structures of continuous word embedding spaces are similar across languages, including those that are distantly related, such as English and Vietnamese. They proposed using a linear mapping from a source to a target embedding space based on this similarity.

To learn this mapping, they used a parallel vocabulary of 5,000 words as anchor points and evaluated their approach to a word translation task. Since then, various efforts have been made to improve cross-lingual word embeddings, such as the iterative method of Artetxe, which reduces the needed dictionary size to as little as 25 words. Nonetheless, all of these alignment methods rely on bilingual word lexicons.
Recent attempts at creating cross-lingual word embeddings without any parallel data utilize Adversarial approaches. The aligned word embeddings create a synthetic dictionary that enables word-to-word translation completely unsupervised.
More advanced techniques that utilize sequence models, such as LSTM, and iterative Back-Translation, enable the alignment of latent embedding at the sentence level.
Adversarial Domain Adaptation
Adversarial domain adaptation is a machine learning technique that involves adapting a model trained on one dataset (the source domain) to perform well on another dataset (the target domain) that has a different underlying distribution. This is often necessary because, in many real-world applications, the data available for training a model may not represent the data the model will encounter when deployed in the real world. Check out an explanation of Domain Adaptation by Maheshwari:
Understanding Domain Adaptation
Learn how to design a deep learning framework enabling them for domain adaptation
towardsdatascience.com
The key idea behind adversarial domain adaptation is to use an adversarial training process in which two neural networks are trained simultaneously: a feature extractor and a domain discriminator (see figure below). The feature extractor network is trained to extract useful features from the input data, while the domain discriminator is trained to predict the domain (source or target) of the input data.
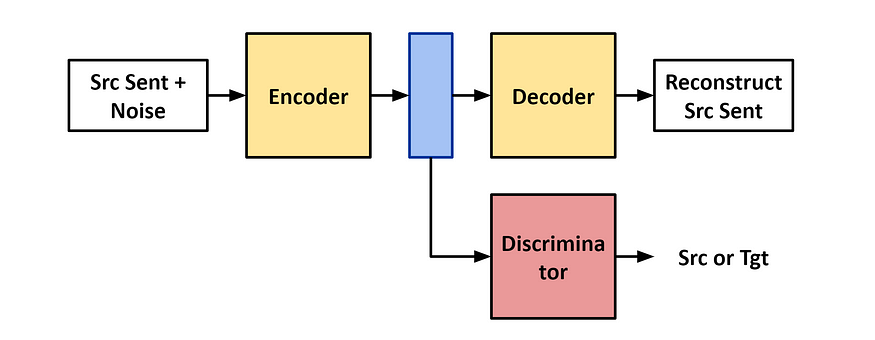
the latent embedding. The encoder’s training objective is to reconstruct the corrupted sentence and to
confuse the discriminator. Figure by Author
During training, the feature extractor is given input data from both the source and target domains, and it is trained to extract features that are useful for predicting the correct output in both domains. Meanwhile, the domain discriminator is trained to predict the domain of the input data, using the features extracted by the feature extractor network as input.
Formally, the discriminator has trained to classify the language source by minimizing the cross-entropy loss:
The encoder and the decoders are trained to reconstruct the original sentence:
The encoder is also trained to fool the discriminator.
Back-Translation
Back-Translation infers to provide the monolingual training data with a synthetic source sentence that is obtained by automatically translating the target sentence into the source language. It pairs the monolingual training sentences with the corresponding synthetic source sentence from which the context vector could be derived.
Iterative Algorithm
Guillaume (2018) proposed an Iterative algorithm, mainly consisting of two architectures: Denoising Auto-Encoding and Back-Translation, respectively. As shown in the Figure below, the upper part stands for the process of the Denoising Auto-Encoding, and the lower part represents the Back Translation

architecture which means it could achieve sentence translation after training instead of word-to-word
any more. Figure by Author
The logic behind the Iterative algorithm is described as follows, which concentrates on the sequence-sequence translation. This algorithm highly relies on an iteration process starting from an initial translation model M¹ in the pseudocode line 3. This M¹ is learned through the achievement from the model proposed by Conneau (2017), and thus derived M could be used to translate the available monolingual data, which is a necessary step in back-translation. Next, the for loop in lines 4–8 will update the encoder and decoder with the parameters needed and minimize their objective function. In the end, M^{t+1}, consisting of the newest encoder and decoder, will be returned. The specific process is in the algorithm below:

Limitations and Challenges
Many existing works focus on modeling UNMT systems, but there is a lack of research on why UNMT works and the scenarios where it is effective. In particular, UNMT still has limited performance when dealing with distant language pairs, domain-specific scenarios, and efficiency.
Distant Languages
The performances of UNMT commonly do not perform better in distant language pairs such as Chinese/Japanese-English than similar language pairs such as German/French-English. This could be due to two reasons:
- The syntactic structures of distant language pairs are very different. Therefore, syntactic correspondence is very difficult to learn without parallel supervision for UNMT.
- The distant language pair may not have enough shared words/subwords to learn the shared latent representation.
Efficiency
Compared to NMT, UNMT has a rapid increase in training time. Furthermore, sharing latent representations between the two translation directions can affect performance, especially for distant language pairs. Denoising can also slow convergence by continuously modifying the training data. The efficient training of UNMT is a major issue that needs to be addressed.
Conclusion
We have thoroughly discussed two main aspects of Unsupervised Neural Machine Transition(UNMT): Word Embedding Pretraining and Aligning Embedding Latent Space. Word Embedding Pre-training essentially constructs a vector space where points around the same area denote semantically similar words. The main insights of this procedure are built upon Harris’ distributional hypothesis. This paper discusses three methodologies that produce word embeddings built upon this hypothesis: Matrix Factorization Methods (e.g., Latent Semantic Analysis, Latent Dirichlet allocation, Global Vectors), Local Context Window Methods (e.g., Word2Vec, FastTexT), and Denoising Auto-Encoding. Latent Space Alignment essentially constructs a linear mapping between source and target embedding space based on the insights that the structures of continuous word embedding spaces are similar across languages. Specifically, UNMT leverages Adversarial approaches, such as Adversarial domain adaptation, Back-Translation, and Iterative Algorithm, to create cross-lingual word embeddings using monolingual data so that the aligned word embeddings create a synthetic dictionary that enables word-to-word and, subsequently sentence to sentence translation.
Further Reading
Major Breakthroughs in… Unsupervised Neural Machine Translation (V)
In this post, we continue our exciting journey of discussing various research lines across the Machine Translation (MT)…
mt.cs.upc.edu
Unsupervised machine translation: A novel approach to provide fast, accurate translations for more…
Automatic language translation is important to Facebook as a way to allow the billions of people who use our services…
engineering.fb.com
Word Translation Without Parallel Data
State-of-the-art methods for learning cross-lingual word embeddings have relied on bilingual dictionaries or parallel…
arxiv.org
Unsupervised Machine Translation Using Monolingual Corpora Only
Machine translation has recently achieved impressive performance thanks to recent advances in deep learning and the…
arxiv.org
Related Article From Author
Unveiling and Addressing Bias in Natural Language Processing
Understanding and mitigating bias in word embeddings and their implications on AI fairness
pub.towardsai.net
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

