



Machine Learning for Documents
Last Updated on January 11, 2023 by Editorial Team
Author(s): Sean Benhur
Originally published on Towards AI.
Documents carry the essential source of vital information. Much of the structured and unstructured information of the enterprises is available as Documents. These are available in the form of native PDF documents and scanned PDF documents such as Bank Invoices, Legal documents, and verification ID cards, over the time information on these documents is used for many applications using techniques such as Optical Character Recognition(OCR), Computer Vision(CV) and Natural Language Processing(NLP)
Document AI refers to the Artificial Intelligence techniques that are applied to analyze and understand documents for various tasks. Notable tasks include Form/Invoice extraction, Optical Character Recognition, Table Detection, and Table Extraction.
In this article, we will look on
- The major tasks and datasets that are prevalent in Document AI.
- The Methodologies such as recent research papers, pretrained models, and existing techniques for each task are discussed.
- Current issues in this domain.
Tasks and Datasets
Different types of tasks are prevalent in Document AI to solve many business use cases. In many cases, some of the tasks are used together to solve one use case. For example, for an invoice extraction task, it is common to use an OCR system to extract the text from the pdf and a Visual Information Extraction system to recognize the entities. In this section, we will look over each task and the common dataset that is used for that task.
Optical Character Recognition
Optical Character Recognition(OCR) refers to the texts in which we recognize and extract the text. It is an important task in the Document AI pipeline. OCR is also one of the hardest tasks since the text could be in different formats and quality of the scanned document can be low and the handwriting of the text can be in poor formats. There are many benchmarks and datasets available for this task; the famous dataset MNIST is a type of OCR dataset. Other benchmarks include IAM Handwriting which consists of handwritten document images, and ICDAR 2003, consisting of images of scene understanding.
Document Layout Analysis
This task refers to identifying the structure and layout of the document, such as the paragraphs, tables, and charts identified. ICDAR 2013 is one of the popular benchmarks for this task which includes text images of word-level annotations; another dataset is PubLayNet which consists of document images annotated on the structure level, such as text, table, figure, and other similar categories.
Visual Information Extraction
This refers to the task of extracting key information from the documents. In this task, only key entities are extracted, unlike OCR, where the entire text is extracted but here, only the text of the key entities and the spatial information of the same. Invoice extraction, Form extraction are some of the Visual Information Extraction tasks. Benchmarks include FUNSD, which consists of annotated forms with information on semantic entities, Named Entities, and Spatial Information. CORD is another benchmark that consists of images of receipts annotated on each text region with spatial-level information.
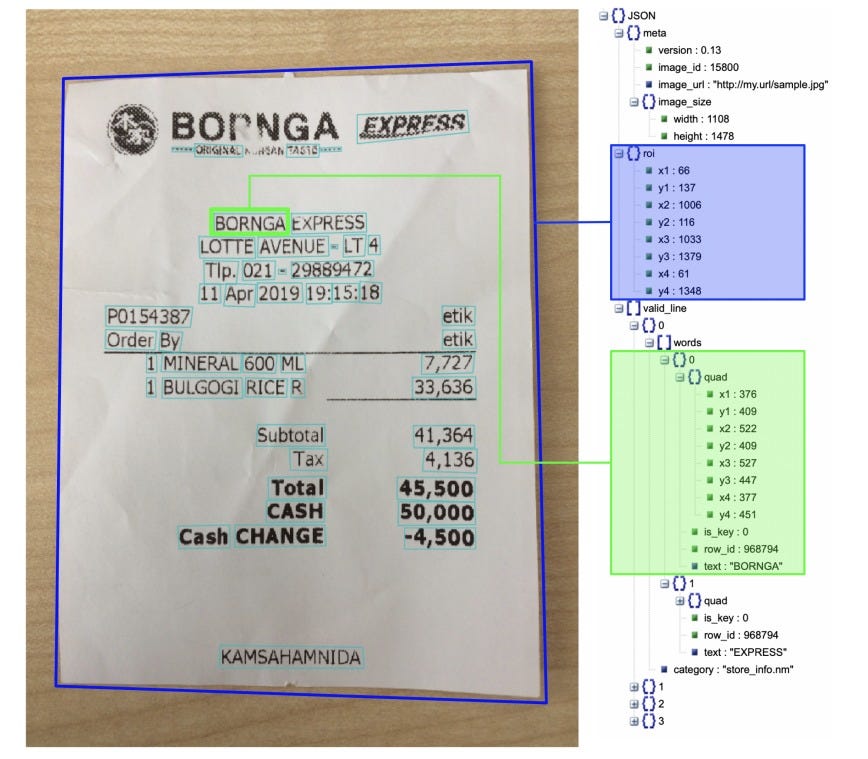
Document Visual Question Answering
This task refers to answering questions based on the text provided in the document. This task is different from the other Visual Question Answering tasks due to the complex nature of the document images. Usually, the text is extracted first with the OCR model, and then the modeling is done. DocVQA is the first dataset that introduced this task; it has two subtasks in which the first one contains a single document image and a question and the second one consists of a collection of document images and a single question.

Document Image Classification
In this task, the images of the documents are classified into the type of documents such as invoices, legal documents, resumes, and many others.RVL-CLIP is a popular benchmark used for this task, it consists of images of sixteen categories, such as memos, emails, scientific reports, and file folders.
Table Detection and Table Extraction
Tables are an important source of information in any document, it mainly consists of numerical information. In this task, we focus on recognizing where the table is located on the document and extracting the information inside it. This task also has some subtasks, such as Table structure recognition, where the rows, the columns, and the cells of the table are identified, and another subtask, Table Functional Analysis, in which the key value is extracted. PubTables-1M is a recently released dataset that consists of 948K annotated PDFs for the tasks of Table Detection, Table Structure Recognition, and Table Functional Analysis.
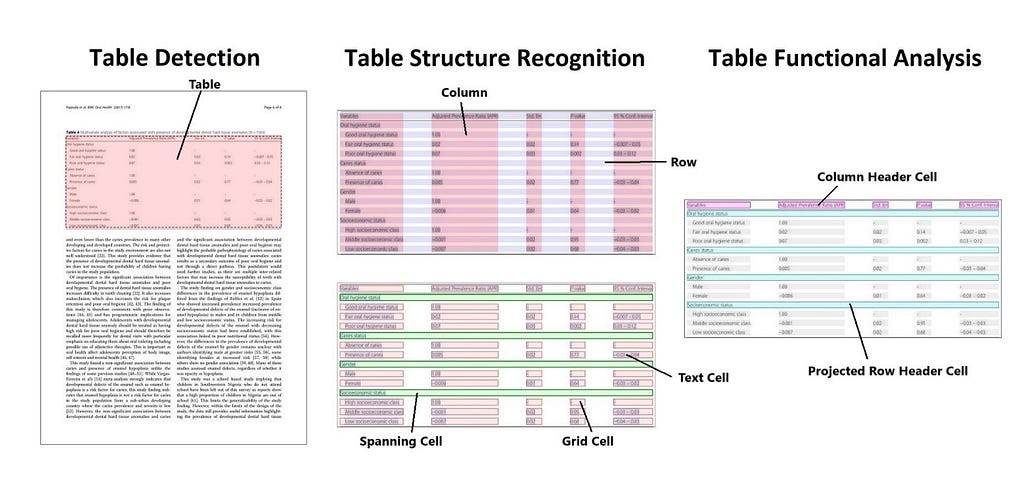
Methodologies
The images of the documents are different from the normal images as it contains some tables, numerical information, and text. The location of these texts is also needed for some of the tasks mentioned above. Before the advent of deep learning, most of the above tasks were solved through rule-based systems and heuristics with several Image processing algorithms and OCR techniques. In this section, we will go over an overview of some methods to solve these tasks as well as the recent research breakthroughs in this area.
Deep Learning based techniques
After the advent of Deep Learning and the rise of CNNs, many computer vision methods have been used for these tasks. Tasks such as Document Layout Analysis and Table Detection tasks are entirely treated as Object Detection tasks where object detection models such as RCNN, Faster-RCNN, and YOLO are used.
For Document Image Classification, the common approaches that are used for Natural Image Classification can be used. Some approaches, such as Dauphnee et al., used textual and visual content to classify the documents.
Tasks on which the text is also an important source of information such as Visual Document Extraction and Document Visual Question Answering. The baseline approach is to use a pipeline consisting of an Object Detection model for locating the word labels, a NER model for extracting the named entities, and an OCR model to extract the text. There are other approaches where an end-to-end model can be used, Palm-et-al used an end-to-end network composing a CNN with MLP blocks that extracts the required entities.
Though these models can achieve better results on Document AI tasks, these models often require a large amount of labeled data but human annotation is an intensive and expensive task for Document Intelligence problems. But due to the large availability of annotated documents, we can leverage the unannotated documents. After the success of Transformer architectures in transfer learning for NLP, Vision, and other areas, it also rose in popularity in Document AI.
Let’s look over some major Document AI pretrained models. These pretrained models are publicly available in Huggingface Hub to finetune for downstream tasks.
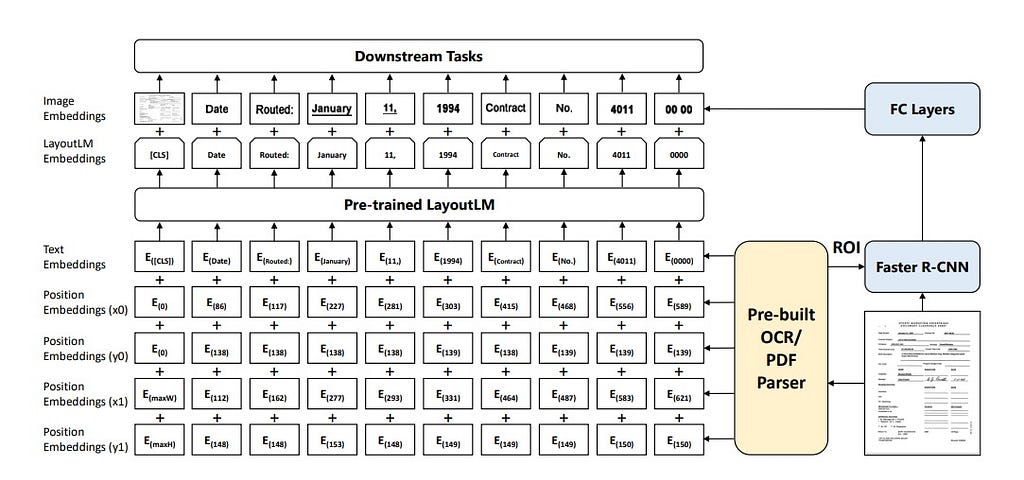
LayoutLM
LayoutLM is the first model that explored the technique of jointly pretraining the textual layout and visual information of the document. It used the pretrained BERT model for the text backbone, 2D Position embedding representing the entity positions, and an Image embedding extracted from Faster-RCNN. The model was pretrained on the Masked Visual Language Modelling Task and Multi-Label Document Image Classification task on a large set of unannotated documents. To check the downstream efficiency, the model was finetuned on FUNSD, a Form Understanding Task, SROIE — Receipt Understanding Task, and RVL-CLIP — Document Image Classification task. The model achieved higher results compared to previous techniques and SOTA models. Subsequently, LayoutLM was improved, and a LayoutLMV2 and LayoutLMV3 were released. LayoutLMV3 does not rely on any text or vision backbone to extract text or image embeddings which significantly saves a lot of parameters. It uses a unified MultiModal Transformer architecture with three different pretraining techniques; it also achieved better results on multiple tasks such as Receipt understanding, Form understanding, Document Image Classification, and Document Visual Question Answering.
TrOCR
TrOCR is the first OCR model that used an end-to-end Transformer based architecture for Optical Character Recognition. Previous approaches leveraged CNN for Image Understanding and RNN for character generation. The model uses a Transformer architecture where the encoder uses a pretrained Vision Transformer, and the decoder uses a pretrained BERT leveraging the advantage of the unlabelled data that the model has trained on it since it does not use any CNN; the TrOCR model archives better results for character recognition on many types of documents and scene images as well.
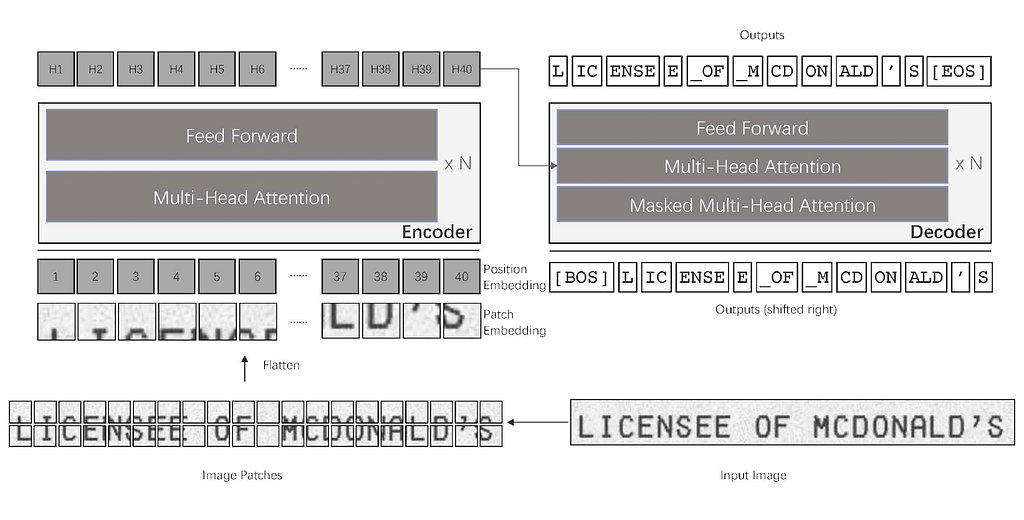
Table Transformer
Tables carry much essential information that is available in a structured format; due to the coherent structure of rows, columns, and cells, it is hard to detect and extract the values inside the cells. Table Transformer introduced in the paper, PubTables-1M: Towards comprehensive table extraction from unstructured documents achieved State of the performance when an object detection based transformer architecture DETR is applied for the task. Previous solutions used CNN-based models with a set of pre-processing or post-processing steps to locate the values.
Conclusion
Thus with the recent availability of pre-trained models in Document AI, many tasks involving the documents can be solved using the rich information on the documents. Some of the prevalent issues in this field is the availability of datasets for public use; since document contains private information, many of the datasets are used only for private use cases. But nonetheless, research in the field has been rapidly increasing in recent years.
References:
- https://www.microsoft.com/en-us/research/project/document-ai/
- https://huggingface.co/blog/document-ai
Machine Learning for Documents was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

