



LangChain SQL Agent for Massive Documents Interaction
Author(s): Ruben Aster
Originally published on Towards AI.
I recently tackled a very interesting challenge involving AI’s ability to digitalize a vast amount of documents and enable a user to ask complex, data-related questions on these documents, like
- Data Retrieval Questions: These involve fetching specific data points or sets of data from the database, such as “How many products are in the ‘electronics’ category?” or “What were the total sales in Q4 2021?”
- Aggregation Queries: Questions that require summarizing data, like calculating averages, sums, counts, etc., for example, “What is the average price of all listed products?” or “What is the total number of customers in each region?”
- Data Relationship Exploration: Questions that probe the relationships between different data entities, such as “Which customers bought more than three different products?” or “List all suppliers who did not deliver any products last month.”
- Conditional Queries: These involve conditions or filters, like “List all transactions above $500 that occurred in 2022” or “Show me all the products that are out of stock.”
These aren’t the typical questions that you could solve by just using RAG. Instead, we will leverage LangChain’s SQL Agent to generate complex database queries from human text.
The documents should contain data with a bunch of specifications, alongside more fluid, natural language descriptions.
We’ll perform the following steps to finally be able to ask complex questions about a large collection of documents:
- Read all PDF documents.
- Analyze the content of each document using GPT to parse it into JSON objects.
- Write those objects into a SQLite Database, spread across multiple tables.
- Use LangChain SQL Agents to ask questions by automatically creating SQL statements.
Disclaimer: This article delves into concepts involving AI and data manipulation. To glean the most value, you should possess a foundational understanding of Python programming, GPT models, embeddings, vector search, and SQL databases.
I present to you: The Osram Product Datasheets
Check out the product datasheets from Osram. Their website is a treasure trove of such documents:
Specialty Lighting U+007C OSRAM PIA
Edit description
www.osram.de
Consider, for example, the product datasheet PDF for ‘XBO 1000 W/HS OF.’
It is a rich tapestry of text types: product names, descriptions, application areas, benefits, you name it.

Moreover, there’s a wealth of specifications of all kinds:

And let’s not overlook the specifications presented in multi-line tables:

All things considered, we’re set with an excellent foundation to start our AI-driven challenge!
Analyze Documents using Python, LangChain and GPT
What I would usually do now is to spin up an Azure AI Document Intelligence service to train a model on a small set of PDFs to detect content.
But I’ve opted for a different route this time.
We’ll work with Python and LangChain to read and analyze the PDF documents. I’m using Python 3.11.
First, we need to set up our environment by installing and importing the required libraries:
%pip install pypdf
%pip install langchain
%pip install langchain_openai
%pip install sqlite3
from pypdf import PdfReader
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
Now, let’s dive into the PDF parsing. We aim to extract meaningful content while ignoring less useful information like empty lines, headers, and footers using visitor_text:
document_content = None
def visitor_body(text, cm, tm, fontDict, fontSize):
y = tm[5]
if text and 35 < y < 770:
page_contents.append(text)
with open(f'./documents/ZMP_55852_XBO_1000_W_HS_OFR.pdf', 'rb') as file:
pdf_reader = PdfReader(file)
page_contents = []
for page in pdf_reader.pages:
page.extract_text(visitor_text=visitor_body)
document_content = "\n".join(page_contents)
print(document_content)
Let’s check out the parsed document:
Product family benefits
_
Short arc with very high luminance for brighter screen illumination
_
Constant color temperature of 6,000 K throughout the entire lamp lifetime
_
Easy to maintain
_
High arc stability
_
Instant light on screen thanks to hot restart function
_
Wide dimming range
Product family features
_
Color temperature: approx. 6,000 K (Daylight)
_
Wattage: 450…10,000 W
_
Very good color rendering index: Ra >
Product datasheet
XBO 1000 W/HS OFR
XBO for cinema projection U+007C Xenon short-arc lamps 450…10,000 W
[..]
Packaging unit
(Pieces/Unit)
Dimensions (length
x width x height)
Volume
Gross weight
4008321082114
XBO 1000 W/HS OFR
Shipping carton box
1
410 mm x 184 mm x
180 mm
13.58 dm³
819.00 g
[..]
__
Upon reviewing the parsed content, it’s evident that it lacks structure — tables are disjointed, and related entities are scattered.
Here’s where we enlist GPT’s help to impose order:
- We’ll instruct GPT to format the parsed data into a structured JSON object.
- By supplying an example of the parsed data, along with strategic hints prefixed with
<<<, we can guide GPT's understanding and structuring of the document. - Utilizing the OpenAI Chat API, we’ll request GPT to generate a JSON object from a new set of parsed product data.
Let’s construct an insightful system message to initiate this process. We’ll begin with a clear directive for GPT, followed by presenting the parsed data as context, and interspersing targeted hints to refine the output:
Carefully observe how we integrate various hints to sculpt the precise JSON output we necessitate:
You analyze product descriptions to export them into a JSON format. I will present you with a product data sheet and describe the individual JSON objects and properties with <<<. You then create a JSON object from another product data sheet.
>>> Example product:
Product family benefits <<< benefits (string[])
_
Short arc with very high luminance for brighter screen illumination <<< benefits.[*]
_
Constant color temperature of 6,000 K throughout the entire lamp lifetime <<< benefits.[*]
[..]
_
Wide dimming range <<< benefits.[*]
Product family features <<< product_family (object)
_
Color temperature: approx. 6,000 K (Daylight) <<< product_family.temperature = 6000
_
Wattage: 450…10,000 W <<< product_family.watts_min = 450, product_family.watts_max = 10000
_
Very good color rendering index: Ra >
Product datasheet
XBO 1000 W/HS OFR <<< name
XBO for cinema projection U+007C Xenon short-arc lamps 450…10,000 W <<< description
[..]
Technical data
Electrical data <<< technical_data (object)
Nominal current
50 A <<< technical_data.nominal_current = 50.00
Current control range
30…55 A <<< technical_data.control_range = 30, technical_data.control_range = 55
Nominal wattage
1000.00 W <<< technical_data.nominal_wattage = 1000.00
Nominal voltage
19.0 V <<< technical_data.nominal_voltage = 19.0
Dimensions & weight <<< dimensions (object)
[..]
Safe Use Instruction
The identification of the Candidate List substance is <<< environmental_information.safe_use (beginning of string)
sufficient to allow safe use of the article. <<< environmental_information.safe_use (end of string)
Declaration No. in SCIP database
22b5c075-11fc-41b0-ad60-dec034d8f30c <<< environmental_information.scip_declaration_number (single string!)
Country specific information
[..]
Shipping carton box
1
410 mm x 184 mm x <<< packaging_unity.length = 410, packaging_unit.width = 184
180 mm <<< packaging_unit.height = 180
[..]
"""
My hints are a cluster of different approaches:
- <<< benefits (string[]) — Here starts a list of strings.
- <<< benefits.[*] — This line belongs to the list of strings.
- <<< product_family (object) — Here starts an object.
- <<< product_family.temperature = 6000 — This line is an int property of an object
- <<< product_family.watts_min = 450, product_family.watts_max = 1000 — This line is two int properties (e.g. when there’s a statement like Wattage: 450…10,000 W)
- and so on…
You can get totally creative here and try out whatever makes sense for you. Other cases that come to my mind are
- <<< Translate to another language.
- <<< Provide summary or provide full sentence from bullet point.
- <<< Split data like forename and lastname
- etc.
Testing the Prompt
Alright, time to put GPT to the test and see if it can ace turning our messy PDF text into a neat JSON object.
I’m leaning towards using GPT-3.5-Turbo 0125 this time around, rather than the more capable GPT-4, since Azure’s Document Intelligence service is pretty steep, and I’m all in for finding an alternative solution that keeps our wallets happy while still nailing the job.
At the time of writing, the pricing for GPT-3.5-Turbo is already looking pretty sweet:
- $0.0005 per 1K incoming tokens
- $0.0015 per 1K outgoing tokens
And even better, version 0125 of GPT-3.5-Turbo has a much higher accuracy at responding in requested formats like JSON, which is perfect for our case! And the cherry on top is the context window of 16,385 tokens.
We’ve got our system_message ready and we’ll pair it with the document_content as human input:
chat = ChatOpenAI(model_name='gpt-3.5-turbo-0125', temperature=0)
def convert_to_json(document_content):
messages = [
SystemMessage(
content=system_message
),
HumanMessage(
content=document_content
)
]
answer = chat.invoke(messages)
return answer.content
json = convert_to_json(document_content)
print(json)
Alright, time to eyeball the JSON output we got:
{
"name": "XBO 1000 W/HS OFR",
"description": "XBO for cinema projection U+007C Xenon short-arc lamps 450…10,000 W",
"applications": [
"Classic 35 mm film projection",
"Digital film and video projection",
"Architectural and effect light (“Light Finger”)",
"Sunlight simulation"
],
"technical_data": {
"nominal_current": 50.00,
"control_range_min": 30,
"control_range_max": 55,
"nominal_wattage": 1000.00,
"nominal_voltage": 19.0
},
"dimensions": {
"diameter": 40.0,
"length": 235.0,
"length_base": 205.00,
"light_center_length": 95.0,
"electrode_gap": 3.6,
"weight": 255.00
},
"operating_conditions": {
"max_temp": 230,
"lifespan": 2000,
"service_lifetime": 3000
},
"additional_data": {
"base_anode": "SFa27-11",
"base_cathode": "SFcX27-8",
"product_remark": "OFR = Ozone-free version/H = Suitable for horizontal burning position/S = Short"
},
"capabilities": {
"cooling": "Forced",
"burning_position": "s20/p20"
},
"environmental_information": {
"declaration_date": "10-03-2023",
"primary_product_number": "4008321082114 U+007C 4050300933566",
"candidate_list_substance": "Lead",
"cas_number": "7439-92-1",
"safe_use": "The identification of the Candidate List substance is sufficient to allow safe use of the article.",
"scip_declaration_number": "22b5c075-11fc-41b0-ad60-dec034d8f30c"
},
"logistical_data": {
"product_code": "4008321082114",
"product_name": "XBO 1000 W/HS OFR",
"packaging_unit": {
"product_code": "4008321082114",
"product_name": "XBO 1000 W/HS OFR",
"length": 410,
"width": 184,
"height": 180,
"volume": 13.58,
"weight": 819.00
}
}
}
Pretty solid, I must say. The objects and properties it found are spot-on.
However, there is a notable omission: GPT has overlooked a few critical elements, such as the benefits and product_family, which are nowhere to be found.
So, what’s our game plan? Transition to GPT-4, which offers enhanced capabilities but at a higher cost and definitely slower response times, or adapt our strategy to incorporate Function Calling to optimize our resources while maintaining efficiency?
We opt for the latter, of course!
Improving the Prompt by providing a JSON Schema
Function Calling is MY favorite feature when utilizing GPT. It allows you to specify not only the functions itself that GPT can execute but also the exact JSON schema required for your function.
Consider the following example:
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
The latest models, gpt-3.5-turbo-0125 and gpt-4-turbo-preview, are trained to detect when to initiate a function call and to deliver JSON outputs that align well with the specified function signature — more accurately than their predecessors.
To capitalize on this, we refine our prompt to include the JSON schema we expect in return:
You analyze product descriptions to export them into a JSON format. I will present you with a product data sheet and describe the individual JSON objects and properties with <<<. You then create a JSON object from another product data sheet.
>>> Example product:
Product family benefits <<< benefits (string[])
[..]
-----
Provide your JSON in the following schema:
{
"type": "object",
"properties": {
"name": {
"type": "string"
},
"description": {
"type": "string"
},
"applications": {
"type": "array",
"items": {
"type": "string"
}
},
"benefits": {
"type": "array",
"items": {
"type": "string"
}
},
"product_family": {
"type": "object",
"properties": {
"temperature": {
"type": "number"
},
"watts_min": {
"type": "number"
},
"watts_max": {
"type": "number"
}
}
},
"technical_data": {
"type": "object",
"properties": {
"nominal_current": {
"type": "number"
},
"control_range_min": {
"type": "number"
},
"control_range_max": {
"type": "number"
},
"nominal_wattage": {
"type": "number"
},
"nominal_voltage": {
"type": "number"
}
}
},
"dimensions": {
"type": "object",
"properties": {
"diameter": {
"type": "number"
},
"length": {
"type": "number"
},
"length_base": {
"type": "number"
},
"light_center_length": {
"type": "number"
},
"electrode_gap": {
"type": "number"
},
"weight": {
"type": "number"
}
}
},
"operating_conditions": {
"type": "object",
"properties": {
"max_temp": {
"type": "string"
},
"lifespan": {
"type": "number"
},
"service_lifetime": {
"type": "number"
}
}
},
"logistical_data": {
"type": "object",
"properties": {
"product_code": {
"type": "string"
},
"product_name": {
"type": "string"
},
"packaging_unit": {
"type": "object",
"properties": {
"product_code": {
"type": "string"
},
"product_name": {
"type": "string"
},
"length": {
"type": "number"
},
"width": {
"type": "number"
},
"height": {
"type": "number"
},
"volume": {
"type": "number"
},
"weight": {
"type": "number"
}
}
}
}
}
}
}
After tweaking our approach and , let’s examine the new output:
{
"name": "XBO 1000 W/HS OFR",
"description": "XBO for cinema projection U+007C Xenon short-arc lamps 450…10,000 W",
"applications": [
"Classic 35 mm film projection",
"Digital film and video projection",
"Architectural and effect light (“Light Finger”)",
"Sunlight simulation"
],
"benefits": [
"Short arc with very high luminance for brighter screen illumination",
"Constant color temperature of 6,000 K throughout the entire lamp lifetime",
"Easy to maintain",
"High arc stability",
"Instant light on screen thanks to hot restart function",
"Wide dimming range"
],
"product_family": {
"temperature": 6000,
"watts_min": 450,
"watts_max": 10000
},
"technical_data": {
"nominal_current": 50,
"control_range_min": 30,
"control_range_max": 55,
"nominal_wattage": 1000.00,
"nominal_voltage": 19.0
},
"dimensions": {
"diameter": 40.0,
"length": 235.0,
"length_base": 205.00,
"light_center_length": 95.0,
"electrode_gap": 3.6,
"weight": 255.00
},
"operating_conditions": {
"max_temp": "230 °C",
"lifespan": 2000,
"service_lifetime": 3000
},
"logistical_data": {
"product_code": "4008321082114",
"product_name": "XBO 1000 W/HS OFR",
"packaging_unit": {
"product_code": "4008321082114",
"product_name": "XBO 1000 W/HS OFR",
"length": 410,
"width": 184,
"height": 180,
"volume": 13.58,
"weight": 819.00
}
}
}
Isn’t that a beauty!
The output thoroughly maps out names and descriptions, categorizes benefits and applications into string lists, and discerns ranges with min and max values — all aligned perfectly with our JSON schema expectations. Perfect!
Cost-wise, we’re looking at a great deal: around 3,000 tokens for input and 500 tokens for output tally up to approximately 0.22 cents. This rate means we can analyze almost five full PDF documents for just a penny — a fantastic bargain, especially when considering the consistent price drops (and efficiency gains) of these models over time.
I didn’t count how many dozens and dozens of documents I parsed during the development, but my total bill was below $1.
Exploring LangChain QA Capabilities
While the primary focus of this article leans more toward PDF Analysis and SQL Agents, if you already want to play around a bit you could try out the LangChain Q&A with RAG, especially since it dovetails nicely with our broader objectives.
I’ll provide some code and the output without much further ado, so we can quickly move forward to the real stuff, subsequently.
Let’s start by gathering a bit more product data. Downloaded some additional, random PDF documents from Osram and store them inside the designated documents folder.
After that, we’ll need to bring in a few extra classes:
import os
from langchain.chains.question_answering import load_qa_chain
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
The next step involves reading and converting all the downloaded PDF documents, then aggregating their JSON outputs into a singular array.
pdf_files = [f for f in os.listdir('./documents') if f.endswith('.pdf')]
json_documents = []
for pdf_file in pdf_files:
with open(f'./documents/{pdf_file}', 'rb') as file:
pdf_reader = PdfReader(file)
page_contents = []
for page in pdf_reader.pages:
page.extract_text(visitor_text=visitor_body)
json = convert_to_json("\n".join(page_contents))
json_documents.append(json)
Now, we transition to using the OpenAI Embedding Model, specifically the new text-embedding-3-large (bye bye, ada-002). This model has a price of $0.00002 per 1k token. So don’t worry about importing one or the other document.
Moreover, we’ll incorporate the FAISS Similarity Search library, aligning it with our document content and the embedding model to facilitate content vectorization.
FAISS was developed by Meta back in 2017 and is the open-source alternative in Azure Machine Learning for Azure AI Search — and it does quite a decent job in comparing the embedded vectors. Easy choice!
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
docsearch = FAISS.from_texts(documents, embeddings)
With the groundwork laid, we proceed to the interactive segment — asking questions:
chain = load_qa_chain(chat, chain_type="stuff", verbose=True)
query = "Can I fit the XBO 1000 W/HS OFR into a box with 350mm length and 200mm width?"
docs = docsearch.similarity_search(query)
chain.run(input_documents=docs, question=query)
Observe the response which is grounded with the most relevant document content:
‘No, the XBO 1000 W/HS OFR has dimensions of 410mm in length and 184mm in width, which are larger than the box dimensions of 350mm length and 200mm width.’
Yes, that looks about right. Here’s the PDF file:

It’s shaping up nicely. Now let’s dive into the more advanced applications.
SQLight and LangChain SQL Agent
RAG is an established technique to enable users to chat with their own data. It’s super powerful for scenarios that require some internal, unstructured pieces of information.
While RAG excels in navigating through unstructured information, how would you ask for information that is much more data related? Like, give me all products that have at least 4.000 Watts. Or, provide the size of a shipping carton box that would be sufficient for all products?
When it comes to data-centric queries the precision and structure of SQL come into play.
Manage our Data in a SQLite Database
To manage our data it needs to be systematized within a database. The intuitive step here involves structuring our data into relational tables within SQLite, so we can perform some more complex queries.
While not mandatory, I advocate for the following, additional preparatory step: defining classes that mirror the structure of our JSON outputs.
By integrating these classes prior to database insertion, we not only streamline the data validation process but also ensure our data conforms to expected formats. Should the parsed JSON dictionary lack essential properties that are not marked as optional, there’s probably something wrong.
import json
from typing import Any, List, Optional
from dataclasses import dataclass, field
@dataclass
class ProductFamily:
watts_min: int
watts_max: int
temperature: Optional[int] = field(default=0)
@staticmethod
def from_dict(obj: Any) -> 'ProductFamily':
_watts_min = int(obj.get("watts_min"))
_watts_max = int(obj.get("watts_max"))
_temperature = obj.get("temperature")
return ProductFamily(_watts_min, _watts_max, _temperature)
# [..]
@dataclass
class Product:
name: str
description: str
benefits: List[str]
product_family: ProductFamily
@staticmethod
def from_dict(obj: Any) -> 'Product':
_name = str(obj.get("name"))
_description = str(obj.get("description"))
_benefits = obj.get("benefits")
_product_family = ProductFamily.from_dict(obj.get("product_family"))
return Product(_name, _description, _benefits, _product_family)
After establishing these classes, we revisit our PDF documents. This time we convert them into JSON format and create instances of Product objects. Moreover, I relocate all processed documents to a processed folder.
import traceback
pdf_files = [f for f in os.listdir('./documents') if f.endswith('.pdf')]
products = []
for pdf_file in pdf_files:
json_content = None
try:
with open(f'./documents/{pdf_file}', 'rb') as file:
pdf_reader = PdfReader(file)
page_contents = []
for page in pdf_reader.pages:
page.extract_text(visitor_text=visitor_body)
document_content = "\n".join(page_contents)
json_content = convert_to_json(document_content)
json_data = json.loads(json_content)
product = Product.from_dict(json_data)
products.append(product)
except Exception as e:
print("{filename} has a problem: {e}".format(filename=pdf_file, e=e))
print(traceback.format_exc())
print(json_content)
else:
os.rename(f'./documents/{pdf_file}', f'./processed/{pdf_file}')
Perfect, now we’ve assembled a robust list of Product instances, ready to be inserted into database tables.
For our demonstration, a SQLite database will suffice. We’ll craft three tables to accommodate our dataset:
- Product — Basic specifications of a product (name, description, length).
- ProductApplication — List of applications linked to a specific product.
- ProductBenefit — List of benefits linked to a specific product.
We’ll perform the following steps:
- Initialize the database and establish the tables.
- Create tuples for each table that contain the relevant product data.
- Execute the data insertion process.
Initiate the database and table creation:
import sqlite3
if(os.path.exists('./db') == False):
os.makedirs('./db')
db_file = './db/products.db'
db_connection = sqlite3.connect(db_file)
db_cursor = db_connection.cursor()
db_cursor.execute('''CREATE TABLE IF NOT EXISTS Product
(name TEXT PRIMARY KEY,
description TEXT,
temperature INTEGER,
watts_min INTEGER,
watts_max INTEGER,
dimension_diameter REAL,
dimension_length REAL,
dimension_weight REAL,
packaging_length INTEGER,
packaging_width INTEGER,
packaging_height INTEGER,
packaging_weight REAL) WITHOUT ROWID
''')
db_cursor.execute('''
CREATE TABLE IF NOT EXISTS ProductApplication (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product TEXT,
text TEXT NOT NULL,
FOREIGN KEY (product) REFERENCES Product(name)
)
''')
db_cursor.execute('''
CREATE TABLE IF NOT EXISTS ProductBenefit (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product TEXT,
text TEXT NOT NULL,
FOREIGN KEY (product) REFERENCES Product(name)
)
''')
db_connection.commit()
Proceed to create the tuples:
products_sql_tuples = [(
p.name,
p.description,
p.product_family.temperature,
p.product_family.watts_min,
p.product_family.watts_max,
p.dimensions.diameter,
p.dimensions.length,
p.dimensions.weight,
p.logistical_data.packaging_unit.length,
p.logistical_data.packaging_unit.width,
p.logistical_data.packaging_unit.height,
p.logistical_data.packaging_unit.weight,) for p in products]
applications_sql_tuples = []
for product in products:
applications_sql_tuples.extend([(product.name, application) for application in product.applications])
benefits_sql_tuples = []
for product in products:
benefits_sql_tuples.extend([(product.name, benefit) for benefit in product.benefits])
And finally insert the data:
db_cursor.executemany('''
REPLACE INTO Product (name, description, temperature, watts_min, watts_max, dimension_diameter, dimension_length, dimension_weight, packaging_length, packaging_width, packaging_height, packaging_weight)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', products_sql_tuples)
db_cursor.executemany('''
REPLACE INTO ProductApplication (product, text)
VALUES (?, ?)
''', applications_sql_tuples)
db_cursor.executemany('''
REPLACE INTO ProductBenefit (product, text)
VALUES (?, ?)
''', benefits_sql_tuples)
db_connection.commit()
Don’t forget to close both, cursor and connection:
db_cursor.close()
db_connection.close()
Let’s check out our database tables. A few fields here and there are NULL, simply because that information didn’t exist on the product data sheet. So all good.
But all critical information was parsed and converted successfully. So I’m really satisfied with the result!
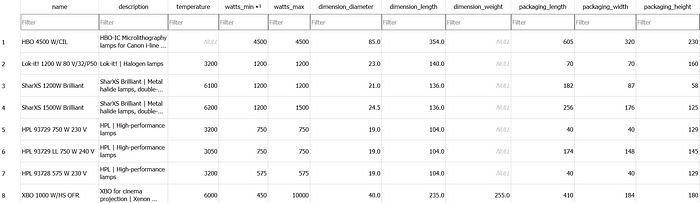
Use LangChain SQL Agent to query information
Now, we’ve arrived at a well deserved part: Asking questions to the LangChain SQL Agent!
LangChain’s SQL Agent provides a dynamic way of interacting with SQL Databases. It’s adept at interpreting table structures and crafting SQL queries based on user prompts, which is nothing short of impressive.
The main advantages of using the SQL Agent are:
- It can answer questions based on the databases’ schema as well as on the databases’ content (like describing a specific table).
- It can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
- It can query the database as many times as needed to answer the user question.
- It will save tokens by only retrieving the schema from relevant tables.
As you would expect from LangChain, the code is very clear, even as it performs complex operations behind the scenes.
For querying with SQL Agent I want to leverage GPT-4 this time. The data volume is manageable compared to the extensive processing required for importing a multitude of documents. That’s why I allow myself a little more power here.
from langchain_community.utilities import SQLDatabase
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
from langchain_community.agent_toolkits import create_sql_agent
db = SQLDatabase.from_uri("sqlite:///db/products.db")
llm = ChatOpenAI(model="gpt-4-0125-preview", temperature=0)
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)
With everything in place, it’s time to ask some questions. Let’s start with something straightforward, like how many products we currently have.
prompt = "How many products do you have?"
result = agent_executor.invoke({"input": prompt})
And it gave a perfectly correct answer, including the SQL statement:
Invoking: `sql_db_query` with `SELECT COUNT(*) AS NumberOfProducts FROM Product` [(20,)]
There are 20 products in the database.
While it may appear simple, the SQL Agent’s ability to not only formulate the SQL query but also discern the existing tables is really remarkable.
Now, let’s escalate the complexity. I want to find a packaging size that would work for all products.
prompt = "I need to find a packaging size that works for all products. What size would that package have?"
result = agent_executor.invoke({"input": prompt})
The result is spot-on:
To accommodate all products, the packaging size would need to have the following dimensions:
Length: 605 mm
Width: 420 mm
Height: 900 mm
Weight: 7177.0 grams
This size would work for all products in the database.
Here’s the query SQL Agent devised to retrieve the necessary information:
sql_db_query` with `SELECT MAX(packaging_length) AS max_length, MAX(packaging_width) AS max_width, MAX(packaging_height) AS max_height, MAX(packaging_weight) AS max_weight FROM Product
Okay, we want more! Let’s ask for the product with the highest possible temperature and its applications — which, by the way, we stored in a different table:
prompt = "Provide the product with the highest possible temperature and it's applications."
result = agent_executor.invoke({"input": prompt})
And again, the answer is exactly right:
The SharXS 1500W Brilliant is a state-of-the-art metal halide lamp, double-ended, designed to deliver exceptional lighting performance.
With an impressive maximum temperature of 6200°C, it is perfect for applications that demand high-intensity and reliable lighting.
This lamp is particularly suited for concert and effect lighting, where vibrant and dynamic illumination is essential.
Perfect, “SharXS 1500W Brilliant” is definitely the product with the highest possible temperature:
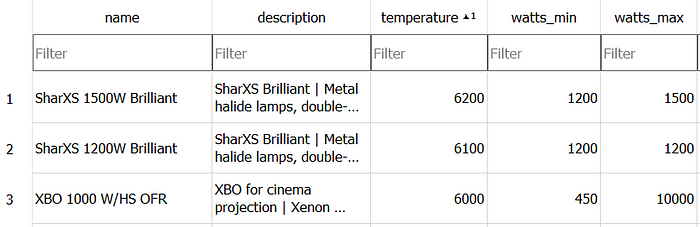
And SQL Agent was even clever enough to find the reference on the ProductApplication table:

Conclusion
As so often, I find myself impressed by the seamless interplay of these technologies after some tweaking here and there and applying the learnings gained with Large Language Models during the last years.
Also GPT version 0125 works perfectly well to provide data in JSON format. It’s evident that OpenAI is committed to enhancing Function Calling and ensuring it meets the standard use cases for creating computer-readable formats.
Would I entrust SQL Agent with a production enterprise database? ONLY if it was design for exactly this case and ONLY for internal staff! Allowing a language model to autonomously execute queries still strikes me as overly risky.
However, for public scenarios, I am open to exploring safer alternatives, such as formulating GraphQL requests.
Well, maybe next time…
I hope this exploration has been as engaging for you as it has been enlightening for me.
Enjoy developing and see you next time.

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

