



Key Phrase Extraction and Visualization : Python and Power BI
Last Updated on January 6, 2023 by Editorial Team
Last Updated on March 6, 2021 by Editorial Team
Author(s): Jayant Kumar Kodwani
Natural Language Processing
Key Phrase Extraction and Visualization: Python and Microsoft Power BI
Discover insights in unstructured text
Implementing RAKE algorithm in Python and Power BI integration
We live in an age where data is the new currency! This makes the Big tech giants the richest companies in the world. The best investment for the next few decades will be the investment in data. So, what do these companies do with this data? How can anyone handle pieces of textual and unstructured data from Facebook posts, Twitter or Linkedin? To a layman, scanning or sampling might sound like a good idea, however, data scientists know the risks of sampling and the pain of scanning text by text, row by row, and word by word 😬. This is where data experts use “Key-phrase Extraction”.
Key-phrase Extraction is the skill to evaluate unstructured text and returning a list of key phrases. For example, given input text “The food was delicious and there were wonderful staff”, the service returns the main talking points: “food” and “wonderful staff”.
What will we Discuss?
In this story, we will extract key-phrases using RAKE algorithm in Python on a sample set of data and then and visualize in Microsoft Power BI.
Here is the link for the sample data that we will use: Sample Data
What is RAKE?
RAKE is short for Rapid Automatic Keyword Extraction algorithm, it is a domain-independent keyword extraction algorithm that tries to determine key phrases in a body of text by analyzing the frequency of word appearance and its co-occurrence with other words in the text.
Resources Required
- Python instance (i.e. Spyder)
- Microsoft Power BI Desktop (Pro License)
- (OPTIONAL) Microsoft Azure Subscription (Free Trial or Paid) to correlate key-phrases together with sentiments.
Are you ready?? Here we go 🏄
Step 1: Install RAKE package and store stop wordlist
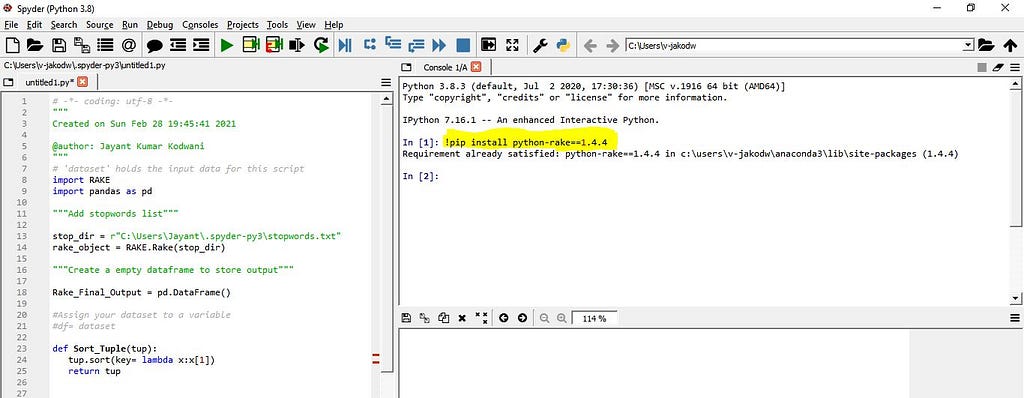
1.1 Installation: Open Python instance (i.e. Spyder 🐍 ) and issue below command to install the rake package.
!pip install python-rake==1.4.4
1.2 Create stop wordlist: Stop words are the words that generally do not help in text analysis and are typically dropped within all the informational systems and also not included in various text analyses as they are considered to be meaningless. Words that are considered to carry a meaning related to the text are described as the content bearing and are called content words. You can download the stopwords list here and customize the same as per your requirements. Save it at the desired location and copy the path for configuring the Python script.
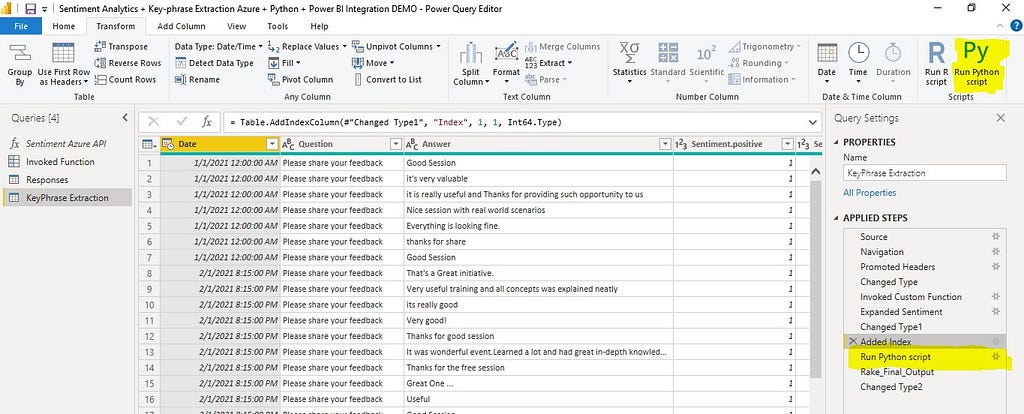
Step 2: Open Power BI, Import Data & Configure Python script
2.1 Power BI Data Import: Open a new instance of Power BI desktop>> Import Data from Excel (Sample Data) >>Browse the sample data file >> Import data >> Calling “Run Python script” in Power Query Editor (Under Transform)
2.2 Prepare your Python Script: You can use the below Python script and customize the same by replacing the path for stopwords list in row 11.
Also, you can specify/restrict the # of key-phrases to be extracted by modifying the count in row 31 (i.e. replace [-1:] to [-5:] to get up to 5 key-phrases from 1 text input)
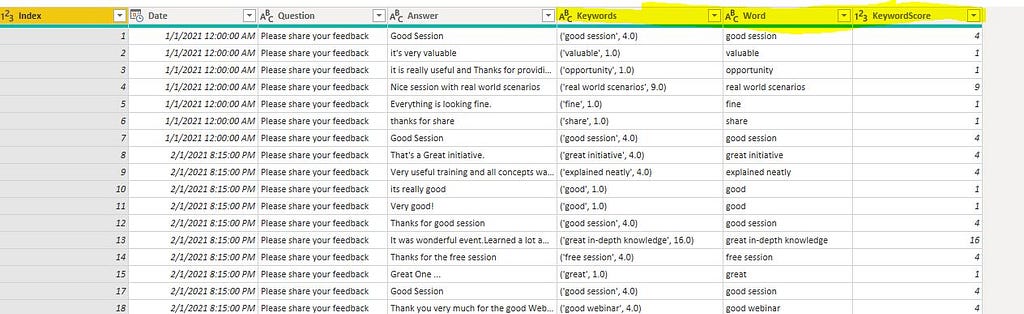
Once done with the customization, you can apply the script and expand the “Rake_Final_Output” dataset. You can Save and Close the Power Query Editor to apply the script. This is how your dataset looks like after new fields added for key-phrases and their scores.
Step 3: Power BI Integration and Visualization
Now comes the fun part that we all love, the visualizations! 💝
In order to visualize the key-phrases, I would recommend to use a Word Cloud ☁️ together with tables preferably with sentiment analysis 😃, so you can relate the key-phrases with positive, neutral and negative sentiments.
You can download a sample Power BI template which integrates Sentiment analysis as well as key-phrase extraction all packed together in a Power BI.
As you can see in the below example, we have “Top 10 Key phrases with negative sentiments” where phrases like “Slower Connections” and “restart 10 times” are directly correlated to negative sentiments 😢

Similarly, we have “Top 10 Key phrases with positive sentiments” where phrases like “explained neatly” and “great in depth knowledge” are directly correlated to positive sentiments 😃.
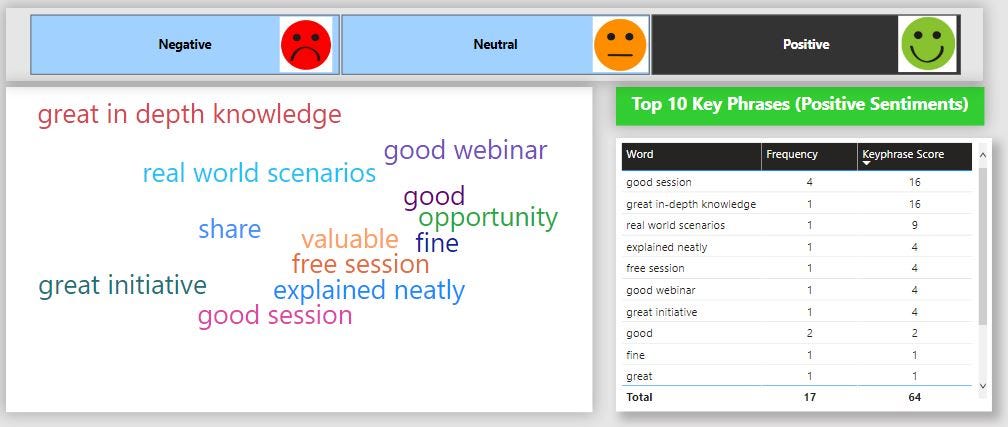
Conclusion
We learned 📘 how to apply RAKE algorithm to extract key-phrases and integrate the analysis in Microsoft Power BI to develop visualizations.
You could use other datasets and customize the code to see what suits your use case best! 👍
Came across a different approach for key-phrase extraction? Please drop it in the comments !
References
[3] Data source: prepared manually by the Author
Key Phrase Extraction and Visualization : Python and Power BI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

