



Data Exploration of Zero To One by Peter Thiel
Last Updated on March 6, 2021 by Editorial Team
Author(s): sk7
Natural Language Processing
“Brilliant thinking is rare, but courage is in even shorter supply than genius.” — Zero to One by Peter Thiel.
Known as the ultimate startup playbook and less-so as a political manifesto, Zero to One by Peter Thiel takes you on a journey from his Law degree at Stanford to his ultimate success at PayPal and beyond. Thiel emphasizes the importance of product differentiation in a globalized society. He demonstrates slim profit-margins by analyzing the highly competitive Manhattan restaurant marketplace and extols the omnipotent Monopoly in business. He slashes the education system for numbing curiosity. He makes large concepts so digestible that by the end of the book you want to get up and start brainstorming new business ideas.
After finishing the business book phenomenon, I decided to apply text analysis and NLP principles to analyze Zero to One. I bought an e-version of his book and converted it to a text file. Analyzing 40,867 words and 207,012 characters (no spaces), here is what I found:
Tools used: Python 3.9 in Jupyter notebooks
Libraries used: NLTK, Gensim, PyLDAvis & Spacy
Key steps: Text Preprocessing, Tokenization, Lemmatization & Topic Modeling
Preprocessing:
I used the Regex library to strip the text file of digits and newline characters. I then used the NLTK library to tokenize, remove stop words and lemmatize the data. This preprocessing step was essential to my analysis.
Most Common Words/Word Cloud:
Finding the most common words was useful in setting the pace for the rest of the analysis. Although no conclusions can be drawn from this step alone, I wanted to find the 20 most common words in the book as a stepping stone for future investigation. I used the Counter function from the collections library to create a tuple of the most frequent words using a preprocessed list of the corpus. As seen from both the word cloud and the bar graph, the big picture ideas such as ‘company’, ‘people’, and ‘business’ were reiterated throughout the book. Interestingly, ‘monopoly’ isn’t even in the top 20.
Bigram:
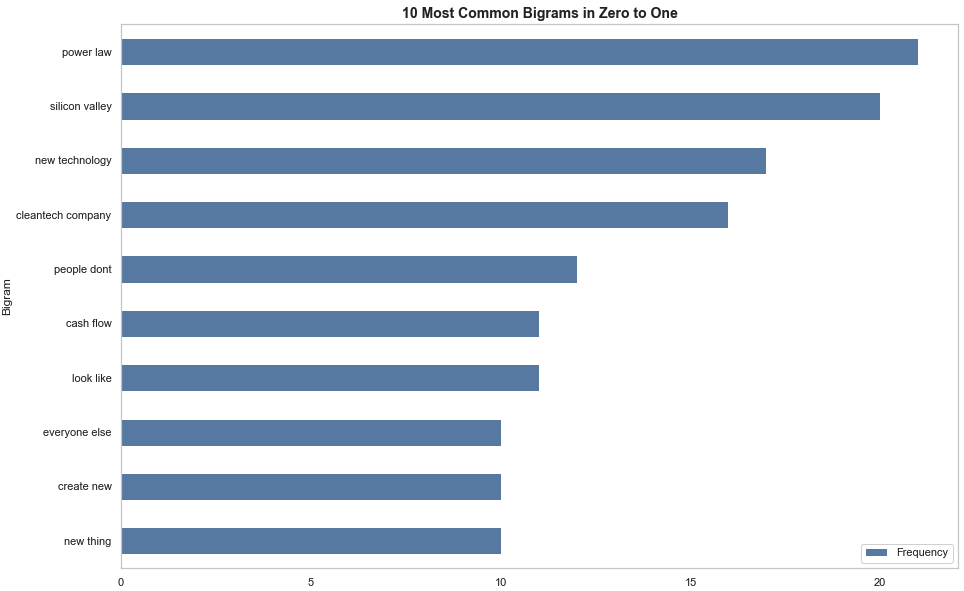
In this step, I used the CountVectorizer function from the sklearn library to convert the raw text into a sparse vector of ngram range (2, 2). I then used the transform method to create a dictionary from the corpus. After that, I plotted the graph to see the most frequently occurring bigrams in the book.
The results from the bigram clearly show Peter Thiel’s devotion to the Power Law. Interestingly, the graph also highlights the influence of novel technology and Silicon Valley in the book. This makes sense because, throughout the book, Thiel reiterates the importance of creating a differentiated product and urges readers to create value using technology. Although, it is unclear whether these results are anecdotes from his time at PayPal or reflect his ideologies on technology. Additionally, ‘cleantech company’ was mentioned 20 times. This is interesting because it poses the question of whether Peter Thiel believes clean technology should be the main focus of founders today.
Named Entity Recognition:
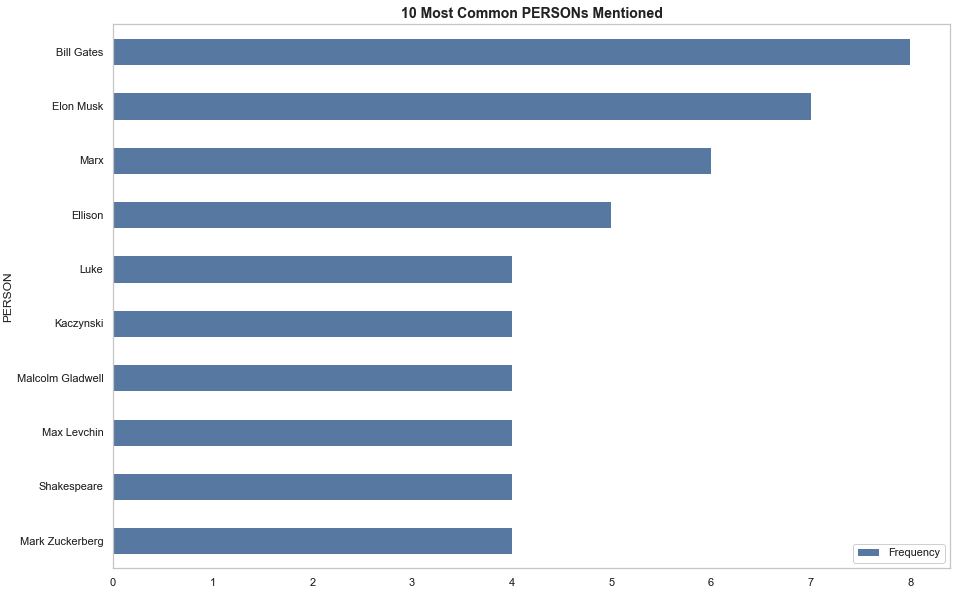
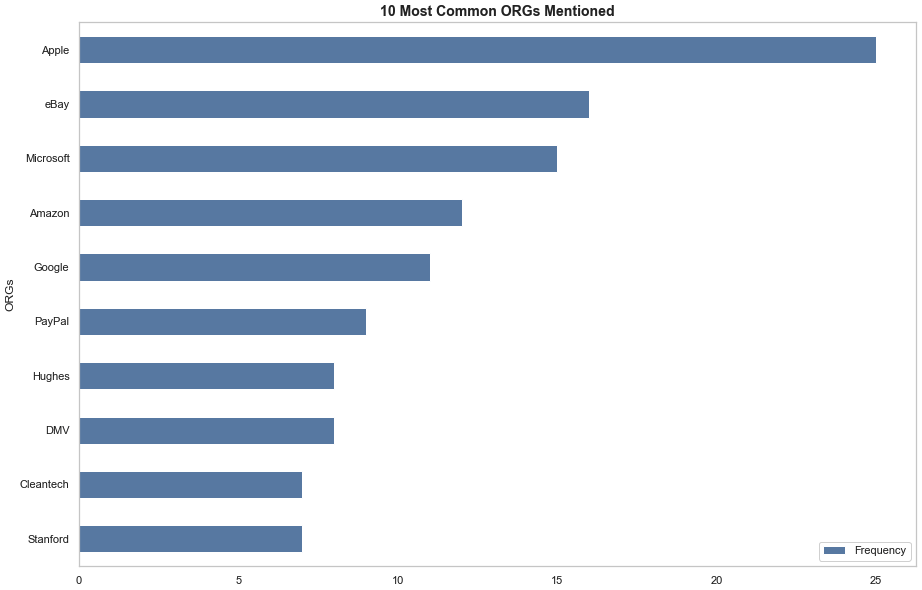
This part of the analysis was more to find out which companies and famous founders Thiel references in the book. By loading the en_core_web_sm library from Spacy and using the NLP function on a tokenized list of the corpus, I was able to use the Counter function to extract the most common organizations and people mentioned in the book (I checked to see if the document label was ‘ORG’ for organizations or ‘PERSON’ for people). Unsurprisingly, Thiel talks about Apple and Bill Gates as being the pillar of a successful company and founder. Reiterating his admiration for Apple, Thiel mentions Apple about the same number of times as he mentions PayPal (I assume that whenever eBay is mentioned in this document, Thiel is referring to PayPal’s initial niche market: an electronic payment method to be used on eBay. Adding the number of times eBay and PayPal are mentioned, you get 26, which is 1 more than the number of times Apple is mentioned).
Topic Modelling:
For Topic Modelling, I used pyLDAvis and LdaMulticore from the gensim library to find co-occurring keywords and discover hidden topics in the book. DataCamp provided an insightful and easy-to-use tutorial on finding the number of topics in a given document. After finding the optimum number of topics, I created a Latent Dirichlet Allocation (LDA) model and prepared a visual to see my results. Topic 1 perfectly illustrates the most impactful theme in the book. With references to ‘startup’, ‘entrepreneur’, and ‘monopoly’, this part of the analysis perfectly encapsulates Peter Thiel’s ideologies in Zero to One.
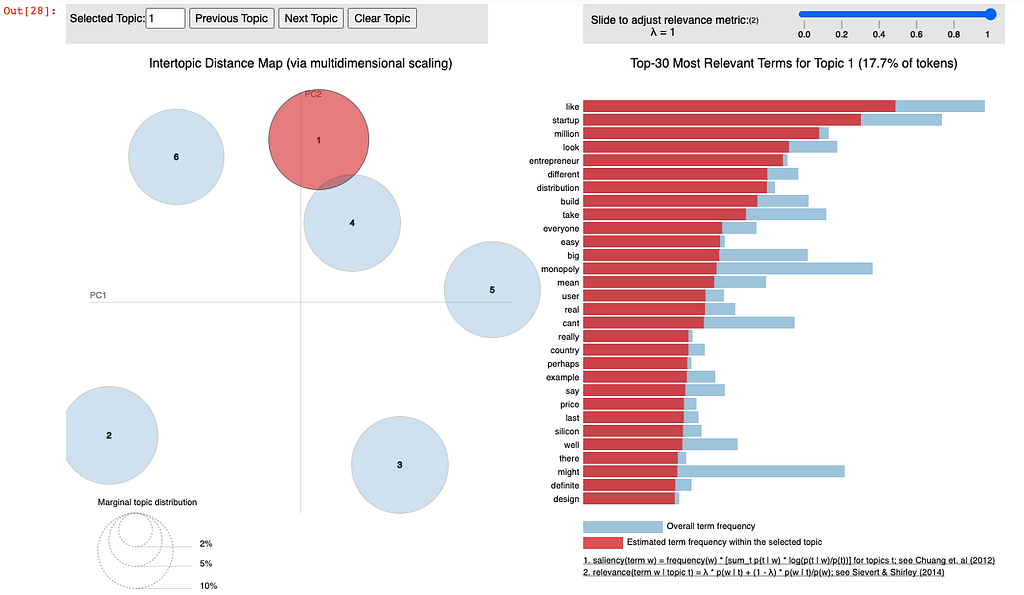
After reading the book, I found myself reflecting on distinct topics that I gathered from my own bias. The text analysis provided a useful insight into some of the key takeaways from Zero to One. Using data analysis techniques to explore the themes of the book gave me a more complete understanding of its many different ideas.
For those interested, you can find the code repository on my GitHub: Zero to One.
Data Exploration of Zero To One by Peter Thiel was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

