



Introduction
Last Updated on July 25, 2023 by Editorial Team
Author(s): Hitesh Hinduja
Originally published on Towards AI.
Testing in Machine Learning: A Comprehensive Guide with Examples from TensorFlow, PyTorch, Keras, scikit-learn, Hugging Face, and More-Part-1 of 3
Here we are with a new blog today. In this three-part series, we will learn about testing frameworks in ML, which is a rapidly developing area. In the first part of the blog, we will learn about why there is a need for testing frameworks, followed by unit testing techniques. We will cover most of the testing libraries/packages in various frameworks, starting from TensorFlow, PyCaret, DeepDiff, and many more. In the second part of the blog, we will cover gradient testing techniques using JAX, Theano, and many more. We will also cover some testing frameworks like Nose, and some more testing techniques like smoke tests, A/B testing, Canary roll-outs, Blue-green deployments, and many more in AI/ML. In the final and third parts of the blog, we will go through some interesting research papers that have been published in the field of testing in AI/ML, followed by some startups and the interesting work they have been doing in this space. So let’s get started!
Most teams today don’t have the opportunity to follow these best practices while deploying a model into production or during staging or model building. In this blog, I will share some of my experiences from the past, where the need for these frameworks/techniques/libraries was felt, and how they have evolved over time. So, let’s get started with a story!
Understanding Regression Testing through Experiences:
It was in the year 2018 when one of my team members, who was a skilled software developer, came to me with a genuine question. He asked, “Hitesh, I have one question which I need to know. We have so many testing frameworks today in software development, such as Test and behavior-driven developments, equivalence partitioning, boundary value analysis, code coverage, mocking and stubbing, and many more. Can you please help me understand the complete list of tests that we use today to test our software code/pipelines, etc.?” We went to one of the conference rooms and discussed a range of tests that we use today, including regression testing, performance testing, and many others. Then, my team member asked me, “If we consider regression testing, how do we enable that in AI/ML models?”
It was a good question that helped to relate software testing experiences with AI/ML testing experiences. In the end, I believe that a “successful product is not one that has fancy technologies, but one that meets the needs of its users and is tested successfully to ensure its reliability and effectiveness”.
Now, let me share an example I explained to him on how regression testing can be done in AI/ML scenarios. In 2018, I was working on an NLP use case which proved to be one of my toughest experiences to date. It involved not only having a tagged dataset with input paragraphs and output classes but also extracting a specific set of paragraphs and tagging them based on our experts’ classification. Let me fast forward a bit and come to the final dataset. I had approximately 1 million rows of data in the first cut with 4 classes, as it was a multiclass classification model. I asked my team to take just 50,000 rows of data through a stratified sample thought process, meaning to take equal distributions of their classes to start with and not a random sample. My approach has always been a “start simple” thought process, which means that back then, I used to start with basic n-gram ensembling, meta-dense features being feature-engineered, and running classical ML models on the dataset. Assuming all the cleaning was done as the first step, I used to always follow the above ones. Cleaning requires a lot of understanding and is not just about dropping stopwords, punctuation, etc. My team members would be known by now some blunders due to dropping themU+1F600. Once these traditional techniques/models were built, I used to get a good benchmark on how these probabilistic and rule-based techniques had performed. My next step was not to jump into deep learning-based approaches but rather to jump into RCA(Root Cause Analysis) of my outputs. I used to ask my team to create a simple Excel file of inputs and outputs of their complete dataset combined, train, val, and test, and come over to me once done. My whole team and I used to sit for hours to study the incorrectly classified samples and what were the types of those samples. The multiclass output was a probability of values adding up to 100%. I remember starting with an F1 score as low as 18% to close the final set of models with an F1 of ~85%. I could feel all my team members getting exhausted in doing those Excel analytics, but the RCA got us tons of issues. We used to study the incorrectly predicted classes and understand how close we were to predicting the actual class. If we are not predicting the actual class, are we even predicting the next best class (e.g., old being predicted as very old) that confuses the model, or are the predictions outrightly opposite (e.g., old being predicted as very new)? The RCA deserves a separate blog altogether. What I am trying to say here is the importance of improving the mistakes that the model makes and then checking the same set of models over that data to see which ones perform better. I would not call this exactly regression testing, but imagine our “RCA” observations as a test suite where we check how our model is performing on those test suites. If there are differences, we again investigate the root cause and re-run the models.
Now, you all might have a question about what happens if we keep on improving, and the model generalizes on that data. That’s where we don’t just keep 50,000 samples constant here, but keep on adding samples to our data and slowly retrain the models scaling to a larger dataset. Also, we are not disturbing the output of the test set but rather collecting the test suites of where the model is struggling to understand/fails to predict due to reasons. For example, if you are running a sentiment analysis model with more than 8 sentiments in your data, imagine “anger” vs “hate”, how close the sentiments would be? In such predictions, even exclamations, emojis, and stopwords can turn out to be expensive for incorrect predictions, and so I would say one of your test suites would be to check how these 2 classes are performing for curated test suite of emojis, stopwords, and exclamations.
The advantage of this approach is that it is always easier to understand the behavior of your model on a limited dataset rather than blindly taking millions of rows, performing cleaning, feature engineering, and getting metrics. In conclusion, AI/ML models are complex, and testing them requires specialized frameworks and techniques that go beyond traditional software testing. Techniques like RCA and test suites can help improve the accuracy and reliability of AI/ML models. As we continue to develop and deploy AI/ML models in various applications, it is essential to have a thorough understanding of the testing frameworks and best practices to ensure the success of these models.
Now, let’s continue our discussion on the developments in the testing ecosystem for AI/ML. Let’s get started.
Unit Testing and Additional Testing Methods:
Let’s first understand the unit testing in a simple way
Unit testing in ML is like making sure your pizza toppings are spread evenly. Imagine you’re a pizzeria owner and you want to make sure each slice of pizza has the same amount of pepperoni, mushrooms, and cheese. So, you take a small sample slice, called a “unit slice,” and make sure it has the right balance of toppings. If the unit slice is perfect, you can be confident that the rest of the pizza is too.
In the same way, when you’re developing an ML model, you want to make sure each part of the code is working correctly. So, you take a small sample of data, called a “unit test,” and check that the model is producing the expected output. If the unit test passes, you can be confident that the rest of the model is working too.
And just like how you wouldn’t want a pizza with all the toppings on one side, you don’t want your ML model to be biased towards one type of data or prediction. Unit testing helps ensure that your model is working fairly and accurately for all scenarios.
To perform unit testing, there are several techniques/frameworks/libraries that we will see below. Let’s try to understand, with example cases, how these can be leveraged in ML models, data, and much more. We will also see some interesting startups in this space doing work on testing significantly.
Let’s take different problem statements and see how these test functions are defined. You can use these functions accordingly for your own problem statements.
TensorFlow’s tf.test.TestCase and tf.test.mock modules
In this example, we are using TensorFlow’s tf.test.TestCase and tf.test.mock modules to perform three different types of unit tests on the deep learning model: checking the model summary, checking the number of trainable weights, and checking that the training logs are printed correctly.

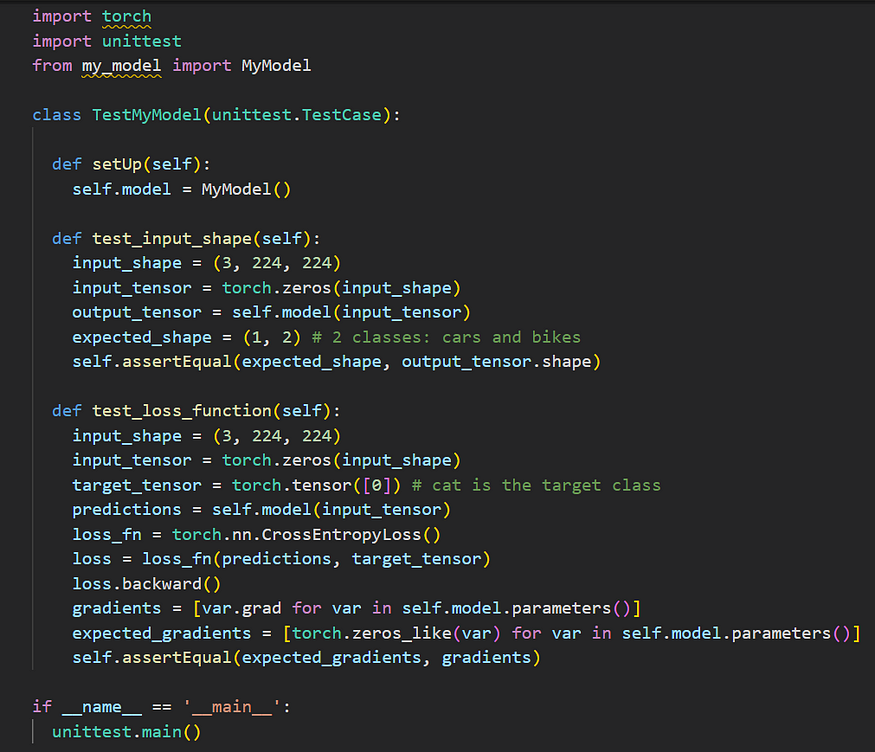
PyTorch’s unittest.TestCase module
In this example, we are testing the same CNN model (MyModel) using PyTorch’s unittest.TestCase module. We are performing the same two unit tests as in the previous example:
- test_input_shape: This test checks whether the output shape of the model matches the expected shape given a specific input shape.
- test_loss_function: This test checks whether the gradients of the model parameters with respect to the loss function are correct
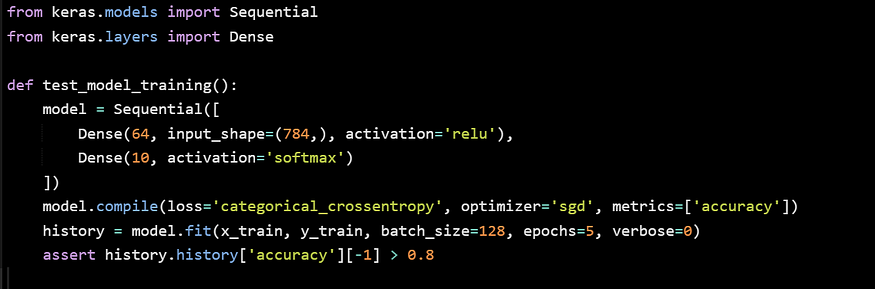
Keras Model.fit() method
In this example, we are using Keras’ Model.fit() method to train the deep learning model and then performing a unit test to check the accuracy of the model after training.
Similarly, we can use the below functions to unit test our modules. In the context of the length of the blog, I will explain each of these functions in a simple way and you can incorporate these in a similar context as above.
sci-kit-learn’s assert_allclose() function
assert_allclose() is a function in the scikit-learn library that checks if two arrays or data frames are equal, within a tolerance.
The function takes two inputs: the first is the expected output or the “true” values, and the second is the actual output or the “predicted” values. The function then compares these two inputs element-wise and checks whether the absolute difference between them is less than a specified tolerance level.
If the difference is greater than the specified tolerance level, then assert_allclose() raises an assertion error, which indicates that the test has failed.
Overall, assert_allclose() is a helpful tool for testing the accuracy of machine learning models, as it can quickly highlight when the model is not producing results within an acceptable margin of error.
MLflow’s mlflow.pytest_plugin module:
MLflow’s pytest plugin is a unit testing technique used in machine learning. It allows you to test your ML models, training code, and preprocessing code in a reproducible and automated way. The plugin provides a set of pytest fixtures that you can use to set up your tests, such as loading data and models, and it also provides a set of assertions that you can use to test your models’ accuracy and behavior. By using the MLflow pytest plugin, you can ensure that your ML models are performing as expected and catch regressions early on.
DeepDiff’s DeepDiff class
DeepDiff is a Python package that provides a convenient way to compare complex Python objects such as dictionaries, lists, sets, and tuples. The DeepDiff class is particularly useful in unit testing in ML as it allows developers to quickly identify differences between expected and actual model outputs.
For example, suppose you have a trained ML model that is expected to output a dictionary with specific keys and values. With the DeepDiff class, you can compare the expected and actual output dictionaries and easily identify any differences between them.
The DeepDiff class provides various comparison methods, such as ‘assert_diff’ and ‘assert_same_structure’, that can be used to perform different types of comparisons between objects. It also provides helpful methods such as ‘to_dict’ and ‘from_dict’ to convert objects to and from dictionaries for comparison.
Using the DeepDiff class in unit testing in ML can help developers quickly catch errors and ensure that their models are performing as expected.
Yellowbrick’s VisualAssert class
Yellowbrick is a Python library for machine learning visualization.
The VisualAssert class allows users to create visualizations of model predictions and actual values, which can be compared side by side to ensure that they are consistent. This can be useful for detecting errors in machine learning models that are not immediately apparent from numerical output alone.
For example, if a model is trained to predict the prices of houses based on various features such as location, size, and a number of bedrooms, a visual assertion using the VisualAssert class could display a scatter plot of predicted prices versus actual prices. If there is a systematic deviation from the 45-degree line (i.e., predicted prices are consistently higher or lower than actual prices), this could indicate a problem with the model that needs to be addressed.
Overall, the VisualAssert class provides an additional layer of validation to machine learning models and can help catch errors that might not be caught through traditional unit testing methods.
Hugging Face’s pytest plugin:
Hugging Face’s pytest plugin is a tool for testing machine-learning models built using the Hugging Face Transformers library. The plugin allows developers to easily write tests for their models and evaluate their performance on various metrics.
With the pytest plugin, developers can define test cases that create model instances, input data, and expected output. The plugin then runs the model on the input data and checks that the output matches the expected output. The plugin also provides various assertion helpers to make it easier to write tests for specific tasks such as text classification, language modeling, and sequence-to-sequence tasks.
Overall, the Hugging Face pytest plugin can help developers ensure that their models are functioning correctly and producing the expected output, which is an important part of unit testing in machine learning.

In this example, we first import the pytest module and the pipeline function from the Hugging Face’s transformers library. Then, we define a simple text classification task pipeline using the pre-trained distilbert-base-uncased-finetuned-sst-2-english model.
Next, we define a test case using the @pytest.mark.parametrize decorator. This test case takes in two inputs — a text sample and the expected label for that sample. For each set of inputs specified in the decorator, the test case runs inference using the pipeline and checks if the predicted label matches the expected label using the assert statement.
Finally, we run the test case using the pytest command in the terminal. The Hugging Face’s pytest plugin automatically discovers the test cases and provides useful output, including any failures or errors.
TensorFlow Probability’s tfp.test_util.assert_near() function
The tfp.test_util.assert_near() function in TensorFlow Probability is used in unit testing to compare two tensors and assert that they are nearly equal (within a certain tolerance). This is useful in testing statistical models, where the output may not be exact due to randomness.
The function takes in two tensors and an optional tolerance level, and checks if they are element-wise nearly equal. If the tensors are not nearly equal, an AssertionError is raised.
Mxnet’s mx.test_utils.assert_almost_equal() function
Similar to the other framework functions.
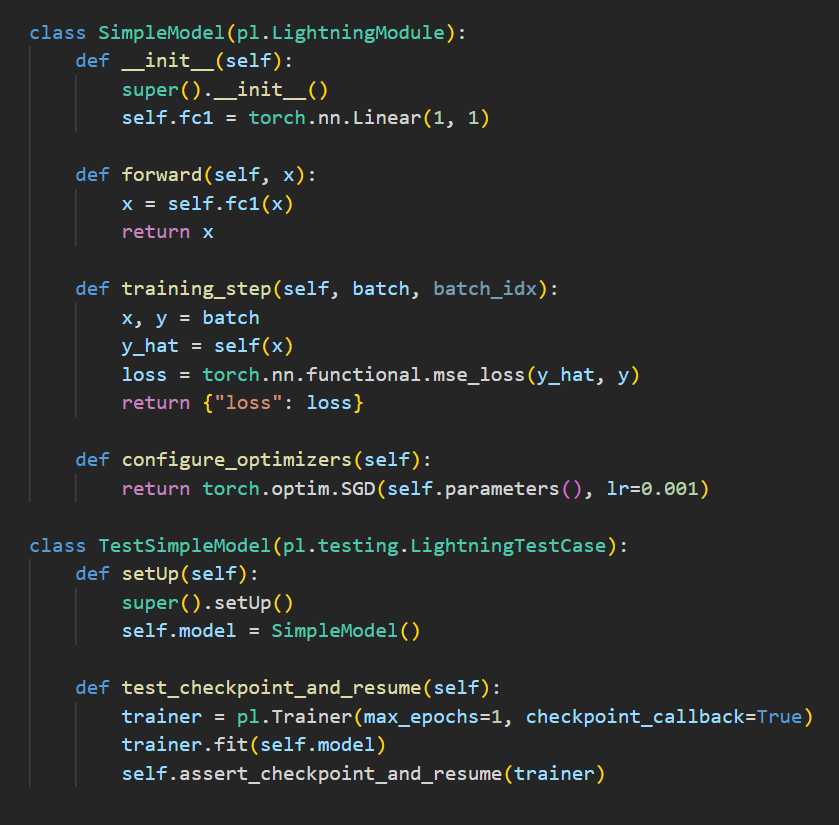
PyTorch Lightning’s LightningTestCase class
LightningTestCase is a class in the PyTorch Lightning library that extends the unittest.TestCase class and provides some additional functionalities for testing PyTorch Lightning models. This class helps in writing test cases for PyTorch Lightning models in a more efficient and easy way.
The LightningTestCase class provides some helper functions for testing various aspects of a PyTorch Lightning model. For example, it provides a run_model_test function that tests whether a model can run properly without any errors, and another function assert_checkpoint_and_resume to test whether a model can be saved and resumed properly.
In this example, we define a simple linear regression model (SimpleModel) and then create a test case (TestSimpleModel) that inherits from LightningTestCase. We define a single test method test_checkpoint_and_resume, which trains the model for one epoch and then uses the assert_checkpoint_and_resume method to test that the model can be checkpointed and resumed without error.
PyCaret’s assert_model_performance() function
Similar to other functions that allows us to compare model performance by setting thresholds.
Allennlp’s test_case.AllennlpTestCase class:
Similar to other classes that allows us to define test cases.
TorchIO’s assert_allclose() function:
Similar to other assert functions of other libraries.
Skorch’s NeuralNetClassifier class:
This is not exactly the testing library but more of a wrapper class. Skorch is a Python library that allows you to use PyTorch models with scikit-learn. The NeuralNetClassifier class is a scikit-learn compatible wrapper for PyTorch neural networks.
When you create a NeuralNetClassifier object, you define the architecture of your neural network using PyTorch. You can also specify hyperparameters such as the learning rate, number of epochs, and batch size.
Once you’ve defined your model, you can use the NeuralNetClassifier object to fit the model to your training data and make predictions on new data. The fit method trains the neural network using the specified hyperparameters, and the predict method uses the trained model to make predictions on new data.
Overall, the NeuralNetClassifier class allows you to use the power of PyTorch to build and train neural networks, while still having the convenience and compatibility of scikit-learn.
DVC
DVC (Data Version Control) is an open-source library that helps you manage and version your machine learning models and data. It provides a simple and efficient way to track changes to your code, data, and experiments, and to collaborate with your team members.
One of the key features of DVC is its ability to version large datasets without storing them in Git, which can quickly become bloated and slow. Instead, DVC uses Git to track the changes to your data and metadata, while storing the actual data in a remote storage service like Amazon S3 or Google Cloud Storage.
DVC also provides tools for reproducible machine learning experiments, which is crucial for testing and validating your models. With DVC, you can create a pipeline that defines the data processing, model training, and evaluation steps, and run it on different machines or environments with the same results. This makes it easy to test different configurations and hyperparameters and to compare the performance of different models.
Overall, DVC can help you streamline your machine-learning workflow, reduce errors and inconsistencies, and improve the quality and reliability of your models.
There are few more from TensorFlow Extended (TFX) framework. Feel free to explore that.
So that’s it from part-1 of this blog. In conclusion, testing is an important aspect of Machine Learning and is crucial for the success of any ML project. The use of testing frameworks, unit testing, regression testing techniques, and other testing methods helps ensure that the model is working as intended, and that changes made to the codebase do not result in unexpected behavior or performance issues.
Furthermore, by leveraging testing frameworks and techniques, data scientists and machine learning engineers can catch and address issues early in the development cycle, leading to more robust and reliable ML models. With the growing importance of AI/ML in various industries, it’s essential to focus on testing and ensure that ML models are working as intended, providing accurate and reliable results.
(Note : In the second part of the blog, we will cover gradient testing techniques using JAX, Theano, and many more. We will also cover some testing frameworks like Nose, and some more testing techniques like smoke tests, A/B testing, Canary roll-outs, Blue-green deployments, and many more in AI/ML, here we will be doing good hands-on in Azure cloud. In the final and third part of the blog, we will go through some interesting research papers that have been published in the field of testing in AI/ML, followed by some startups and the interesting work they have been doing in this space, stay tuned!)
Just before I go, on a lighter note, I asked this question to our very own Azure Open AI ChatGPT, why do machine learning engineers/data scientists avoid testing? and it says U+1F602
Because it always gives them “false positives” and “true negatives”!
Signing off,
Hitesh Hinduja
Hitesh Hinduja U+007C LinkedIn
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


