



Introduction
Last Updated on July 25, 2023 by Editorial Team
Author(s): Manish Nayak
Originally published on Towards AI.
An Introduction to Pix2Pix cGANs U+007C Towards AI
Pix2Pix Network, An Image-To-Image Translation Using Conditional GANs (cGANs)
Pix2Pix network is basically a Conditional GANs (cGAN) that learn the mapping from an input image to output an image. You can read about Conditional GANs in my previous post here and its application here and here. In this post, I will try to explain about Pix2Pix network.
Image-To-Image Translation is a process for translating one representation of an image into another representation.
The Generator’s Network
Generator network uses a U-Net-based architecture. U-Net’s architecture is similar to an Auto-Encoder network except for one difference. Both U-Net and Auto-Encoder network has two networks The Encoder and the Decoder.
U-Net’s Architecture Diagram
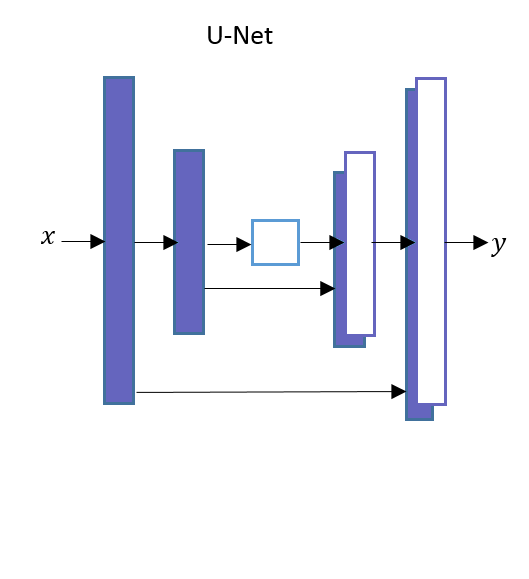
- U-Net’s network has skip connections between Encoder layers and Decoder layers.
- As shown in the picture the output of the first layer of Encoder is directly passed to the last layer of the Decoder and output of the second layer of Encoder is pass to the second last layer of the Decoder and so on.
- Let’s consider if there are total N layers in U-Net’s(including middle layer), Then there will be a skip connection from the kth layer in the Encoder network to the (N-k+1)th layer in the Decoder network. where 1 ≤ k ≤ N/2.
Auto-encoders Architecture Diagram
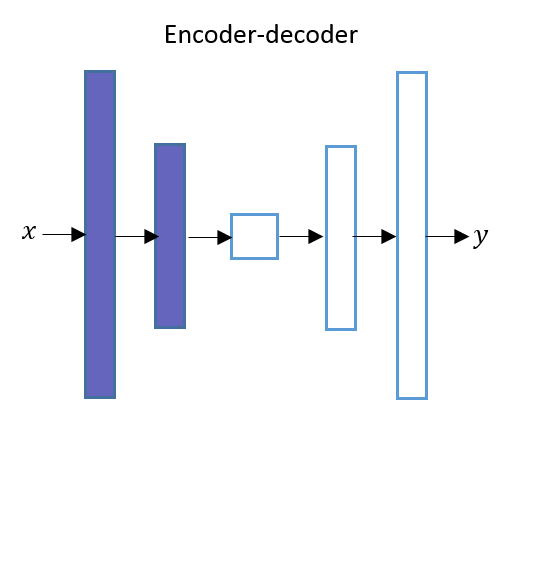
- As shown in the picture Auto-Encoder doesn’t have skip connections between Encoder layers and Decoder layers.
The Generator’s Architecture
- The Generator network is made up of these two networks.
- The Encoder network is a downsampler.
- The Decoder network is an upsampler.
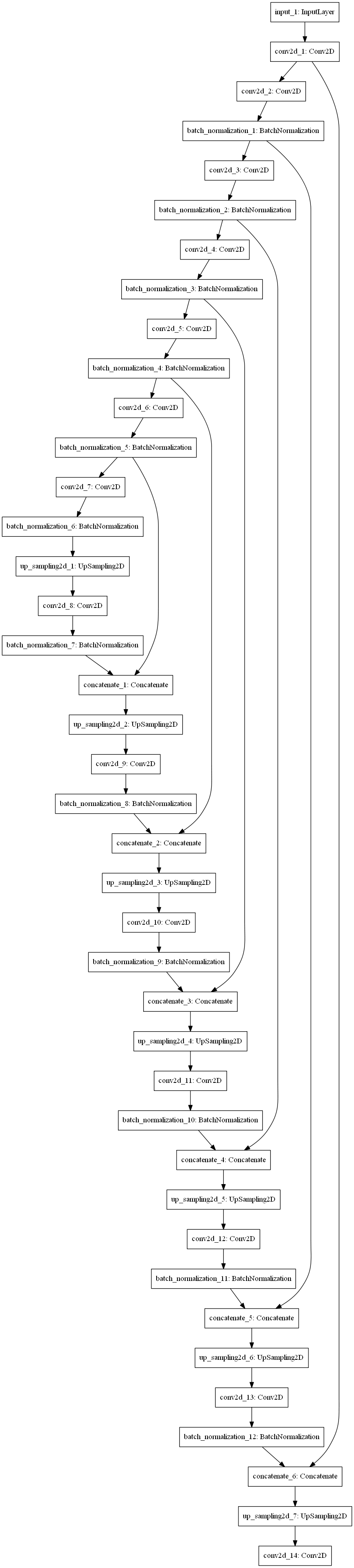
The Generator’s Encoder Architecture
- The Encoder network of the Generator network has seven convolutional blocks.
- Each convolutional block has a convolutional layer, followed a LeakyRelu activation function.
- Each convolutional block also has a batch normalization layer except the first convolutional layer.
The Generator’s Decoder Architecture
- The Decoder network of the Generator network has seven upsampling convolutional blocks.
- Each upsampling convolutional block has an upsampling layer, followed by a convolutional layer, a batch normalization layer and a ReLU activation function.
There are six skip-connections in a Generator network. The concatenation happens along the channel axis.
- The output from the 1st Encoder block is concatenated to the 6th Decoder block.
- The output from the 2nd Encoder block is concatenated to the 5th Decoder block.
- The output from the 3rd Encoder block is concatenated to the 4th Decoder block.
- The output from the 4th Encoder block is concatenated to the 3th Decoder block.
- The output from the 5th Encoder block is concatenated to the 2nd Decoder block.
- The output from the 6th Encoder block is concatenated to the 1st Decoder block.
Discriminator’s Architecture
Discriminator network uses of PatchGAN architecture. The PatchGAN network contains five convolutional blocks.

GAN’s Architecture

Pix2Pix Network’s Training
Pix2Pix is a conditional GANs. The loss function for the conditional GANs can be written as below.

We have to minimize the loss between the reconstructed image and the original image. To make the images less blurry we can either use L1 or L2 regularization.
- L1 regularization is the sum of the absolute error for each data point.
- L2 regularization is the sum of the squared loss for each data point.
- The L1 regularization loss function can be shown for a single image as bellow.

Where y is the original image and G(x, z) is the image generated by the Generator network. The L1 loss is calculated by the sum of all the absolute differences between all pixel values of the original image and all pixel values of the generated image.
The final loss function for Pix2Pix is as given below.
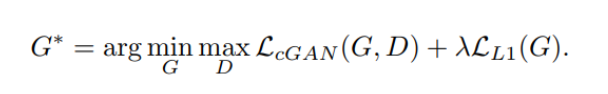
Accompanied jupyter notebook for this post can be found on Github.
Conclusion
Pix2Pix cGANs can be used to convert black & white images to colorful images, sketches to photographs, day images to night images, and satellite images to map images.
I hope this article helped you get started building your own Pix2Pix CGANs. I think it will at least provides a good explanation and understanding about Pix2Pix CGANs.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

