



Building a Recommender System With Pandas
Last Updated on July 25, 2023 by Editorial Team
Author(s): Lawrence Alaso Krukrubo
Originally published on Towards AI.
Full Guide to Build a Recommender System U+007C Towards AI
Hello World, in just a few minutes, I’d show you some pretty effective ways to use Pandas for Data Science.
I assume you use Pandas actively and have basic knowledge of the structure and common methods employed on Pandas Series and Data frames.
So we’re going to explore some real-life data and build a Content-Based Movie Recommender System, using Pandas exclusively.
Table of Contents
- The Data:
- Definition of Recommender Systems:
- Reading The Data:
- Data Cleaning and Pre-processing:
- Content-Based Recommender System:
- Final Output:
- Pros and Cons:
- Summary:
Without further ado, let’s dive right in!
Let’s import Pandas into Colab.
# Dataframe manipulation library.
import pandas as pd
The Data:
We shall use a public data set for movie ratings from Grouplens.org. It’s a zipped file from which I have extracted two files for this exercise. The raw files are in Github as ratings.csv and movies.csv.
This data is a subset of a larger movie lens data set that was used to build a hybrid movie recommendation system, deploying both content and collaborative filtering.
movies.csv contains 9742 movies from 600 users, ratings.csv has 100836 movie ratings.
let’s explore this data as we build a Content-Based Recommender system.

Hey Lawrence! Hold on a second…What exactly is a Content Based Recommender system?
Oops! forgive me for moving so fast…
Definition of Recommender Systems:
Recommender Systems are a collection of algorithms used to recommend items to users based on information taken from the user. These systems can be commonly seen in online stores, movies databases and job finders.
For example, next time Netflix suggests a movie to you, that’s a recommender system algorithm in action.
A Content-based recommender system tries to recommend items to users, based on their profile. The user’s profile revolves around the user’s preferences and tastes, or based on the user ratings.

That said… Let’s keep moving.

Reading The Data:
First, we save the raw files from Github
movies_data = 'https://raw.githubusercontent.com/Lawrence-Krukrubo/Building-a-Content-Based-Movie-Recommender-System/master/movies.csv'
ratings_data = 'https://raw.githubusercontent.com/Lawrence-Krukrubo/Building-a-Content-Based-Movie-Recommender-System/master/ratings.csv'
Let’s set the option to limit max rows displayed at any given time to 20
# Setting max-row display option to 20 rows.
pd.set_option('max_rows', 20)
Next, we define an additional possible representation of missing values. These are often present in real-live data, but pandas do not find them all by default.
# Defining additional NaN identifiers.
missing_values = ['na','--','?','-','None','none','non']# Then we read the data into pandas data frames.
movies_df = pd.read_csv(movies_data, na_values=missing_values)
ratings_df = pd.read_csv(ratings_data, na_values=missing_values)
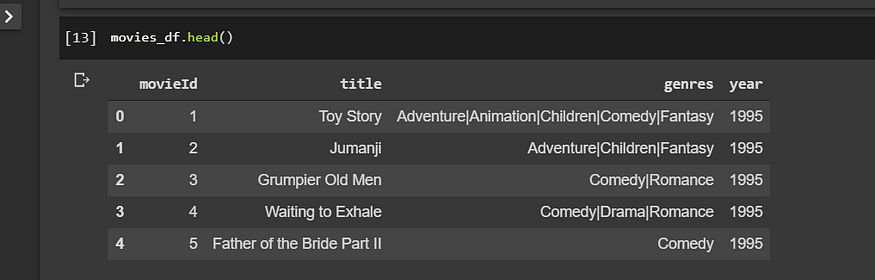
Let’s see the shapes and first few rows of each data frame
print('Movies_df Shape:',movies_df.shape)
movies_df.head()
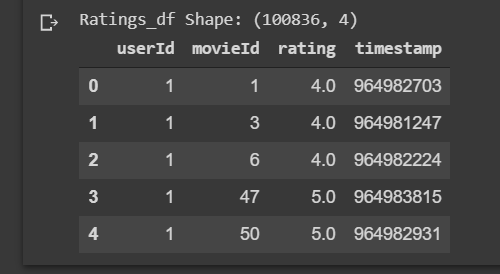
For ratings_df
For movies_df

Data Cleaning and Pre-processing:
movies_df data set:
Let’s remove the year from the title column and place it in its own column, using the handy extract function of pandas.
#Using regular expressions to find a year stored between parentheses
#We specify the parentheses so we don't conflict with movies that have years in their titles.movies_df['year'] = movies_df.title.str.extract('(\(\d\d\d\d\))',expand=False)#Removing the parentheses.
movies_df['year'] = movies_df.year.str.extract('(\d\d\d\d)',expand=False)# Note that expand=False simply means do not add this adjustment as an additional column to the data frame.#Removing the years from the 'title' column.
movies_df['title'] = movies_df.title.str.replace('(\(\d\d\d\d\))', '')#Applying the strip function to get rid of any ending white space characters that may have appeared, using lambda function.movies_df['title'] = movies_df['title'].apply(lambda x: x.strip())
Let’s look at the result!
Let’s split the values in the Genres column into a list of Genres for ease. Using Python’s split string function.
#Every genre is separated by a U+007C so we simply have to call the split function on U+007C.movies_df['genres'] = movies_df.genres.str.split('U+007C')
movies_df.head()

Let’s view a summary of the data,
movies_df.info()
>><class 'pandas.core.frame.DataFrame'>
RangeIndex: 9742 entries, 0 to 9741 Data columns (total 4 columns): movieId 9742 non-null int64 title 9742 non-null object genres 9742 non-null object year 9729 non-null object dtypes: int64(1), object(3) memory usage: 304.5+ KB
Let’s check for missing values
movies_df.isna().sum()
>>movieId 0
title 0
genres 0
year 13
dtype: int64
With just 13 missing values in the year column, let’s fill them with zeros(0) and convert the year column from object type to int.
# Filling year NaN values with zeros.
movies_df.year.fillna(0, inplace=True)# Converting columns year from obj to int16 and movieId from int64 to int32 to save memory.movies_df.year = movies_df.year.astype('int16')
movies_df.movieId = movies_df.movieId.astype('int32')
Let’s see a summary of the data types again.
# Checking the data types.
movies_df.dtypes
>>movieId int32
title object
genres object
year int16
dtype: object

Now, let’s One-Hot-Encode the list of genres. This encoding is needed for feeding categorical data. We store every different genre in columns that contain either 1 or 0. 1 shows that a movie has that genre and 0 shows that it doesn’t. Let’s also store this data frame in another variable, just in case we need the one without genres at some point.
# First let's make a copy of the movies_df.
movies_with_genres = movies_df.copy(deep=True)# Let's iterate through movies_df, then append the movie genres as columns of 1s or 0s.
# 1 if that column contains movies in the genre at the present index and 0 if not.x = []
for index, row in movies_df.iterrows():
x.append(index)
for genre in row['genres']:
movies_with_genres.at[index, genre] = 1# Confirm that every row has been iterated and acted upon.
print(len(x) == len(movies_df))movies_with_genres.head(3)

Let’s simply fill in the NaNs with zero, to show that a movie is not of that column’s genre.
#Filling in the NaN values with 0 to show that a movie doesn't have that column's genre.
movies_with_genres = movies_with_genres.fillna(0)
movies_with_genres.head(3)

ratings_df data set:
Let’s view the first 5 rows again.
# print out the shape and first five rows of ratings data.
print('Ratings_df shape:',ratings_df.shape) ratings_df.head()
Every row in the rating data frame has a user Id associated with at least one movie Id, a rating and timestamp showing when they reviewed it. We don’t need timestamp, so let’s drop it to save memory.
# Dropping the timestamp column
ratings_df.drop('timestamp', axis=1, inplace=True)# Confirming the drop
ratings_df.head(3)

Let’s confirm the right data types exist per column in the rating data set
# Let's confirm the right data types exist per column in ratings data_setratings_df.dtypes
>>
userId int64
movieId int64
rating float64
dtype: object# All data types are correct.
Let’s check for missing values,
# Let's check for missing valuesratings_df.isna().sum()
>>
userId 0
movieId 0
rating 0
dtype: int64# No missing values
Data-cleaning and pre-processing are done! Let’s start building…

Content-Based Recommender System:
Let’s implement a Content-Based or Item-Item recommendation system. We’d figure out what kind of movies a User would like, based on movies the user has seen and rated.
Let’s begin by creating an input user to recommend movies to. The user’s name will be Lawrence.
Notice: Feel free to add or remove movies from the list of dictionaries below! Just be sure to write it in with capital letters and if a movie starts with a “The”, like “The Avengers” then write it in like this: ‘Avengers, The’ .
If a movie you added isn’t here, then it might not be in the original
movies_df or it might be spelled differently, please check capitalization.
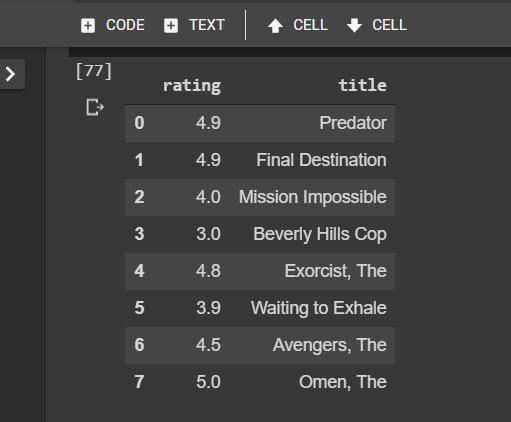
Step 1: Creating Lawrence’s Profile
# so on a scale of 0 to 5, with 0 min and 5 max, see Lawrence's movie ratings below.
Lawrence_movie_ratings = [
{'title':'Predator', 'rating':4.9},
{'title':'Final Destination', 'rating':4.9},
{'title':'Mission Impossible', 'rating':4},
{'title':"Beverly Hills Cop", 'rating':3},
{'title':'Exorcist, The', 'rating':4.8},
{'title':'Waiting to Exhale', 'rating':3.9},
{'title':'Avengers, The', 'rating':4.5},
{'title':'Omen, The', 'rating':5.0}
]
Lawrence_movie_ratings = pd.DataFrame(Lawrence_movie_ratings)
Lawrence_movie_ratings
Let’s add movie Id to Lawrence_movie_ratings by extracting the movie IDs from the movies_df data frame above.
# Extracting movie Ids from movies_df and updating lawrence_movie_ratings with movie Ids.Lawrence_movie_Id = movies_df[movies_df['title'].isin(Lawrence_movie_ratings['title'])]# Merging Lawrence movie Id and ratings into the lawrence_movie_ratings data frame.
# This action implicitly merges both data frames by the title column.Lawrence_movie_ratings = pd.merge(Lawrence_movie_Id, Lawrence_movie_ratings)# Display the merged and updated data frame.Lawrence_movie_ratings

The final step for step 1, is to drop irrelevant columns
#Dropping information we don't need such as year and genres
Lawrence_movie_ratings = Lawrence_movie_ratings.drop(['genres','year'], 1)# Final profile for Lawrence
Lawrence_movie_ratings
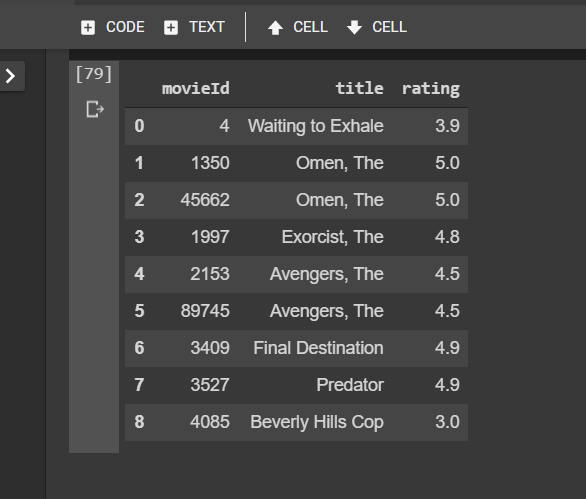
Step 2: Learning Lawrence’s Profile
let’s get the subset of movies that Lawrence has rated from movies_with_genres data frame containing genres with binary values. Let’s call this subset lawrence_genres_df.
# filter the selection by outputing movies that exist in both Lawrence_movie_ratings and movies_with_genres.Lawrence_genres_df = movies_with_genres[movies_with_genres.movieId.isin(Lawrence_movie_ratings.movieId)]Lawrence_genres_df
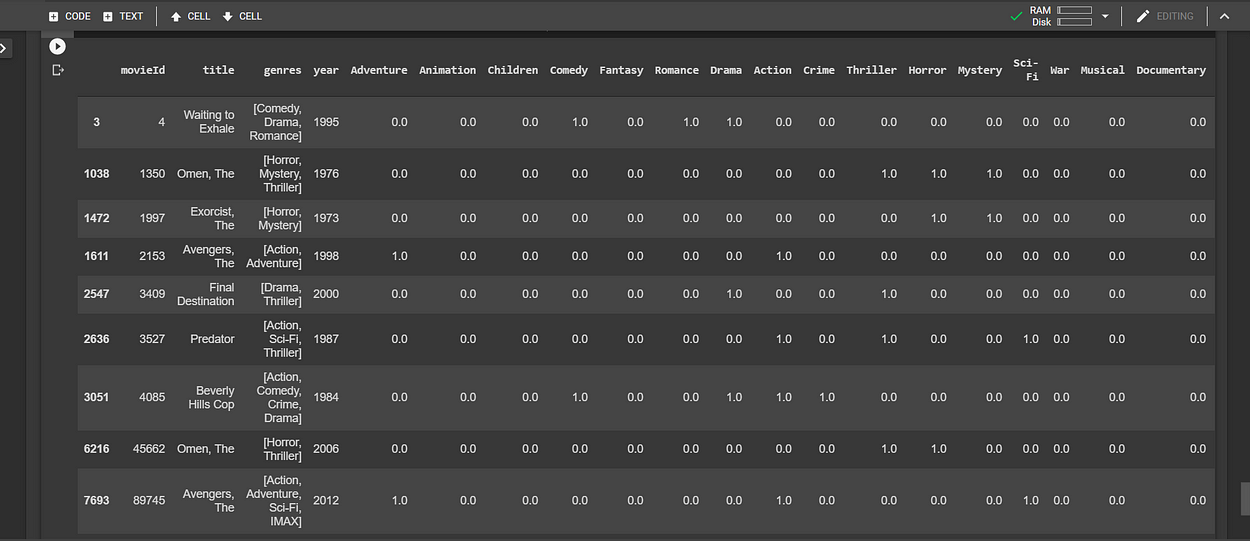
Let’s clean Lawrence_genres_df a bit, reset the index and remove columns we don’t need.
# First, let's reset index to default and drop the existing index.
Lawrence_genres_df.reset_index(drop=True, inplace=True)# Next, let's drop redundant columns
Lawrence_genres_df.drop(['movieId','title','genres','year'], axis=1, inplace=True)# Let's view changesLawrence_genres_df
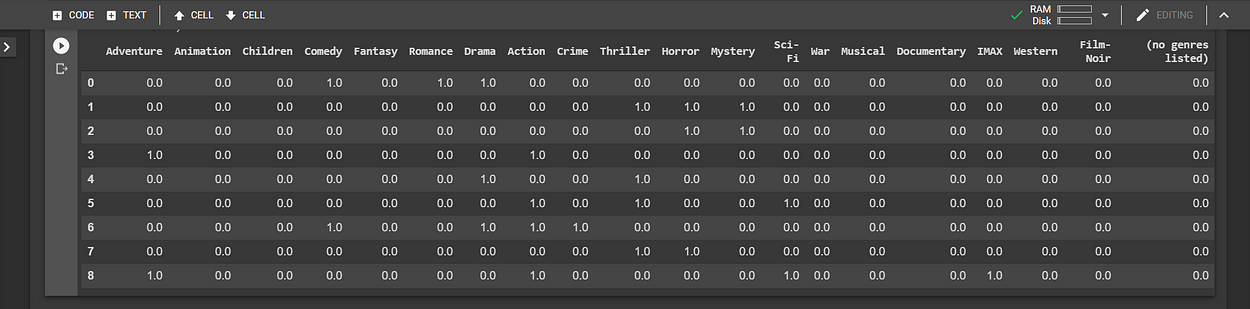
Step 3: Building Lawrence’s Profile
To do this, we’re going to turn each genre into weights, by multiplying the Transpose of Lawrence_genres_df table by Lawrence’s movie ratings. And then sum up the resulting table by column. This operation is actually a dot product between a matrix and a vector.
First, let’s confirm the shapes of the data frames we’ve recently defined.
# let's confirm the shapes of our data frames to guide us as we do matrix multiplication.print('Shape of Lawrence_movie_ratings is:',Lawrence_movie_ratings.shape)
print('Shape of Lawrence_genres_df is:',Lawrence_genres_df.shape)
>>
Shape of Lawrence_movie_ratings is: (9, 3) Shape of Lawrence_genres_df is: (9, 20)
Profile proper…
# Let's find the dot product of transpose of Lawrence_genres_df by Lawrence rating column.
Lawrence_profile = Lawrence_genres_df.T.dot(Lawrence_movie_ratings.rating)# Let's see the result
Lawrence_profile
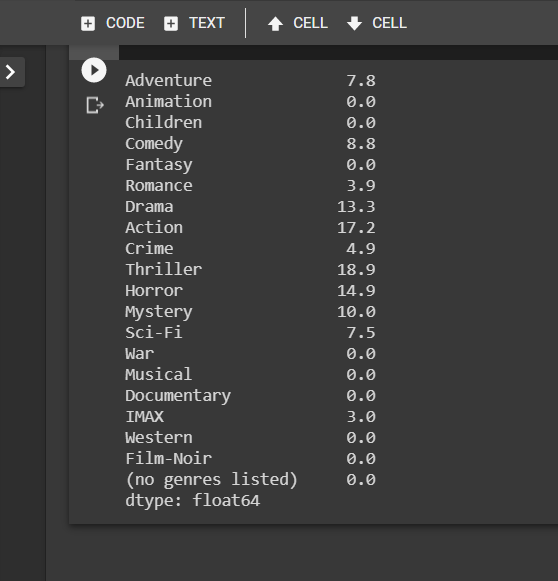
Just by Eye-balling his profile, it is clear that Lawrence loves ‘Thriller’, ‘Action’ and ‘Horror’ movies the most… apt as can be.
Final Output:

Step 4: Deploying The Content-Based Recommender System.
Now, we have the weights for all his preferences. This is known as the User Profile. We can now recommend movies that match Lawrence’s profile.
Let’s start by editing the original movies_with_genres data frame that contains all movies and their genre columns.
# let's set the index to the movieId.
movies_with_genres = movies_with_genres.set_index(movies_with_genres.movieId)# let's view the head.
movies_with_genres.head()

Let’s delete irrelevant columns from the movies_with_genres data frame that contains all 9742 movies and distinctive columns of genres.
# Deleting four unnecessary columns.
movies_with_genres.drop(['movieId','title','genres','year'], axis=1, inplace=True)# Viewing changes.
movies_with_genres.head()

With Lawrence’s profile and the complete list of movies and their genres in hand, we’re going to define a recommendation table. Made up of the weighted average of every movie based on his profile and recommend the top twenty movies that match his preference…
This is more or less the dot product of movies_with_genres data frame by Lawrence_profile, divided by the sum of Lawrence_profile.
# Multiply the genres by the weights and then take the weighted average.
recommendation_table_df = (movies_with_genres.dot(Lawrence_profile)) / Lawrence_profile.sum()
Let’s sort the recommendation_table_df in descending order.
# Let's sort values from great to small
recommendation_table_df.sort_values(ascending=False, inplace=True)#Just a peek at the values
recommendation_table_df.head()

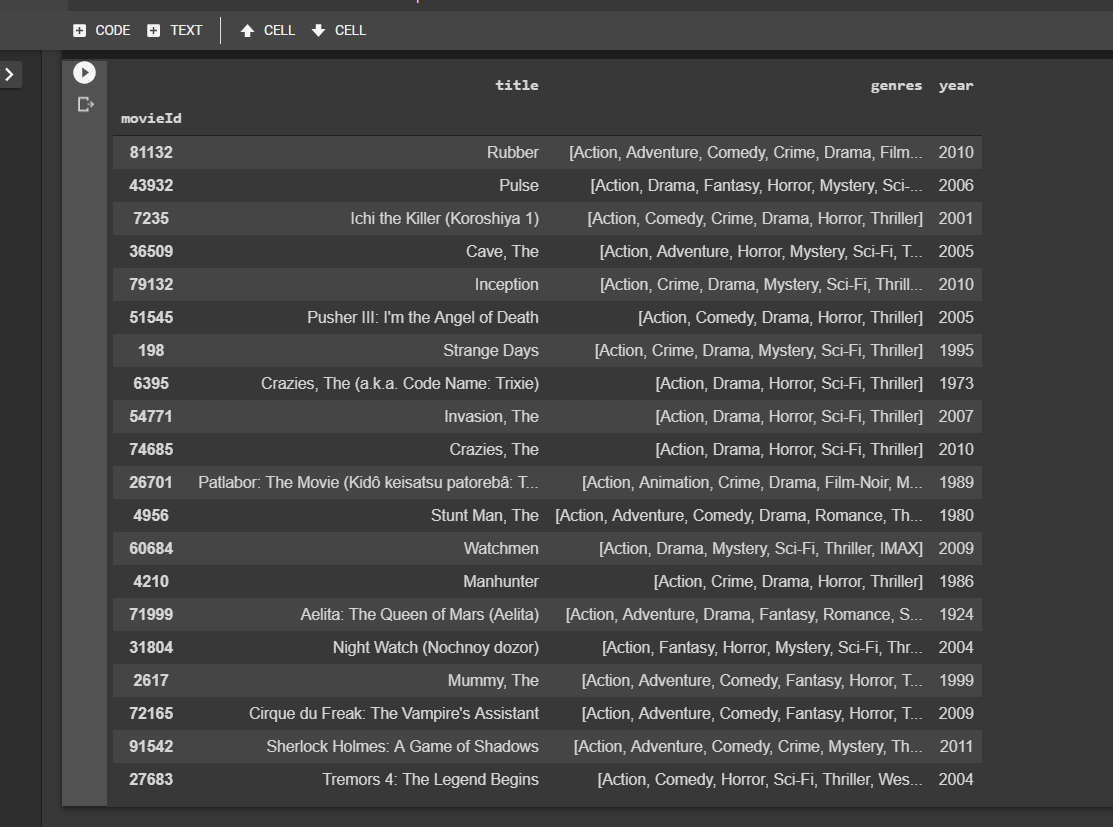
Now here’s the recommendation table below! Complete with movie details and genres for the top 20 movies in descending order of preference that match Lawrence’s profile.
# first we make a copy of the original movies_df
copy = movies_df.copy(deep=True)# Then we set its index to movieId
copy = copy.set_index('movieId', drop=True)# Next we enlist the top 20 recommended movieIds we defined above
top_20_index = recommendation_table_df.index[:20].tolist()# finally we slice these indices from the copied movies df and save in a variable
recommended_movies = copy.loc[top_20_index, :]# Now we can display the top 20 movies in descending order of preference
recommended_movies
Pros and Cons:
Pros
- Learns user’s preferences
- Highly personalized for the user
Cons
- Doesn’t take into account what others think of the item, so low-quality item recommendations might happen
- Extracting data is not always intuitive
- Determining what characteristics of the item the user dislikes or likes is not always obvious
- No new genre of movies will ever get recommended to the user, except the user rates or indicates his/her preference for that genre.
Summary:
Thanks for patiently going through this article. I hope you’ve learned a thing or two… Learning is best by doing, feel free to go through the notebook here in Github, and post comments or observations below.
For further study, check out free courses from IBM cognitiveclass.ai
Cheers!
About Me:
Lawrence is a Data Specialist at Tech Layer, passionate about fair and explainable AI and Data Science. I hold both the Data Science Professional and Advanced Data Science Professional certifications from IBM. I have conducted several projects using ML and DL libraries, I love to code up my functions as much as possible even when existing libraries abound. Finally, I never stop learning and experimenting and yes, I hold several Data Science and AI certifications and I have written several highly recommended articles.
Feel free to find me on:-
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



