



Impact of Optimizers in Image Classifiers
Last Updated on January 7, 2023 by Editorial Team
Last Updated on August 30, 2022 by Editorial Team
Author(s): Toluwani Aremu
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
INTRODUCTION
Ever wondered why a DNN fails to perform as high as expected when it comes to accuracy, especially when there are official or unofficial reports of experts and enthusiasts getting some top performance with the same network and on that same dataset you are using? I remember having hard times trying to wrap my head around the thought that my models just failed when it was expected to perform well. What causes this? In reality, there are lots of factors with varying levels of potential to impact the performance of your architecture. However, I’ll discuss just one in this article. This factor is “The choice of Optimization algorithm to use”.
What is an optimizer? An optimizer is a function or algorithm that is created and used for neural network attribute modification (i.e., weights, learning rates) for the purpose of speeding up convergence while minimizing loss and maximizing accuracy. DNNs use millions of billions of parameters, and you need the right weights to ensure that your DNN learns well from the given data while generalizing and adapting well for a good performance on unseen related data.
Different optimization algorithms have been built over the years, and some of these algorithms have advantages over others, as well as their cons. Therefore, it is imperative to know the basics of these algorithms, as well as understand the problem being worked on so that we can select the best optimizer to work with.
Furthermore, I noticed that a lot of researchers use the SGD-M (Stochastic Gradient Descent with Momentum) optimizer, but in the industry, Adam is favored more. In this article, I will give brief high-level descriptions of the most popular optimizers being used in the AI world. Actually, I had to do a number of experiments to see the difference between these optimizers and answer some questions I have about the use of these optimizers, as well as give clues on which optimizer is the best and when/how to use them based on my observations.
BASIC DESCRIPTION OF DIFFERENT OPTIMIZERS
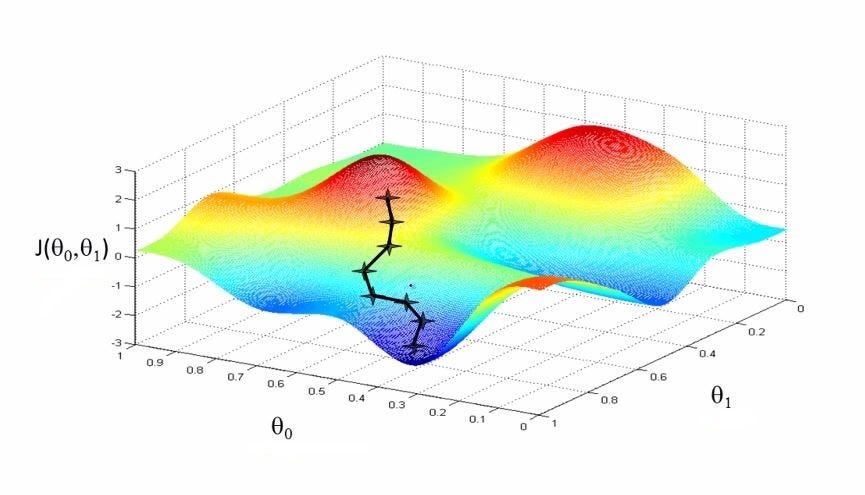
In this section, I will briefly discuss the Stochastic Gradient Descent with Momentum(SGDM), Adaptive Gradient Algorithm (ADAGRAD), Root Mean Squared Propagation (RMSProp), and the Adam optimizers.
SGDM: Since the Gradient Descent (GD) optimizer uses the whole training data to update the model’s weights, it becomes so computationally expensive when we have millions of data points. Due to this, the Stochastic Gradient Descent (SGD) was created to solve this problem by using each datapoint to update the weights. Still, this was computationally expensive for Neural Networks (NN)each datapoint used in the NN needed both forward and back propagations. Also, with SGD, we can’t increase the learning rate while it tries to reach the global minimum. This makes convergence very slow while utilizing the SGD. The SGDM was the solution to that, as it added a momentum term to the normal SGD, which improved the speed of convergence. For deeper explanations, click here.
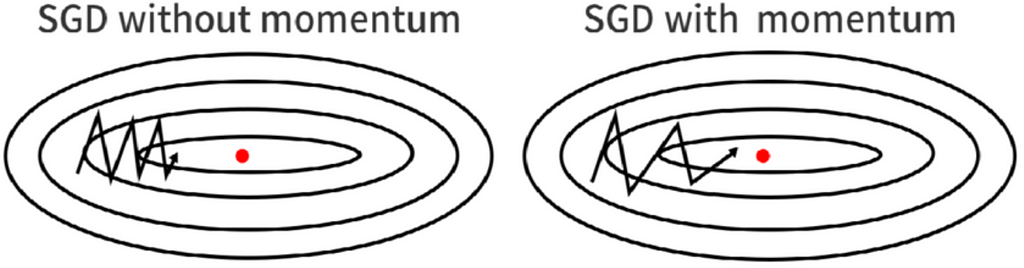
ADAGRAD: Adaptive Gradient Algorithm (Adagrad) is an algorithm for gradient-based optimization which tries to adapt the learning rate to the parameters. The learning rate fits the parameters component by component by incorporating insights from past observations. It makes minor updates to parameters associated with frequent features and major updates to those with features that aren’t occurring frequently. Adagrad also eliminates the need for tuning the learning rate manually as it automatically updates the learning rate based on the parameters. However, the learning rate shrinks fast, making the model think it is close to achieving convergence and stops somewhat short of the expected performance. To learn more, click here.
RMSProp: Proposed by Geoffrey Hinton (even though it remains unpublished), the RMSProp is an extension of the GD and the AdaGrad version of gradient descent that uses a decaying average of partial gradients in the adaptation of the step size for each parameter. It was discovered that the magnitude of gradients can be different for different parameters and could change during the training. Therefore, Adagrad's automatic choice of learning rate could be the nonoptimized choice. Hinton solved this by updating the learned weights using a moving average of the squared gradients. To learn more, click here.
Adam: This optimizer was proposed by Diederik Kingma and Jimmy Ba in 2015 and could arguably be regarded as the most popular optimizer ever created. It combines the advantages and benefits of SGDM and RMSProp in the sense that it uses momentum From SGDM and scaling from RMSProp. It is computationally efficient, unlike both GD and SGD, and requires only a little memory. It was designed to be used on problems with very noisy/sparse gradients. To learn more, click here or here.
EXPERIMENTS

Due to the size of my computing resource, I decided to focus on using LeNet and AlexNet on the CIFAR-10 dataset. The CIFAR-10 dataset consists of 50000 training images and 10000 test images. I trained these models for 50 epochs using the SGD, SGDM, Adagrad, RMSProp, and Adam optimizers. For the SGDM, I used a momentum of 0.9. The global learning rate for my first set of experiments was 0.001 (1e-3).
Note: I am not seeking very good results. I am instead trying to see the impact of each optimizer on the model’s performance.
I start by calling the important libraries:
Then, I loaded and transformed the CIFAR-10 dataset:
The LeNet and AlexNet models:
To get the full code, check out this repository (give it a star if you don’t mind).
The results are as follows.
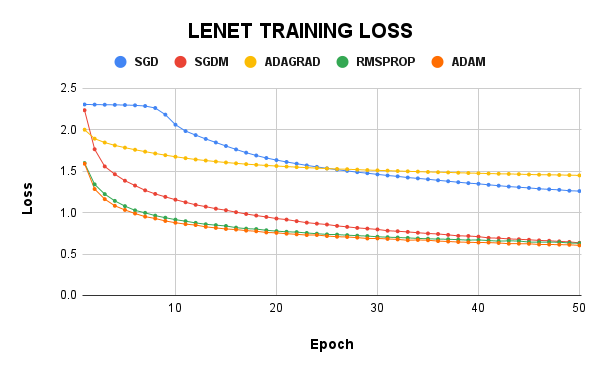
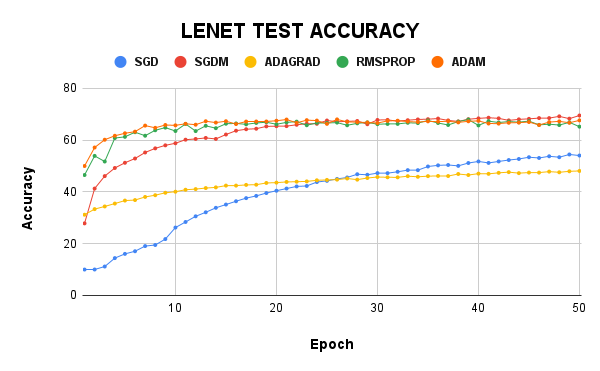
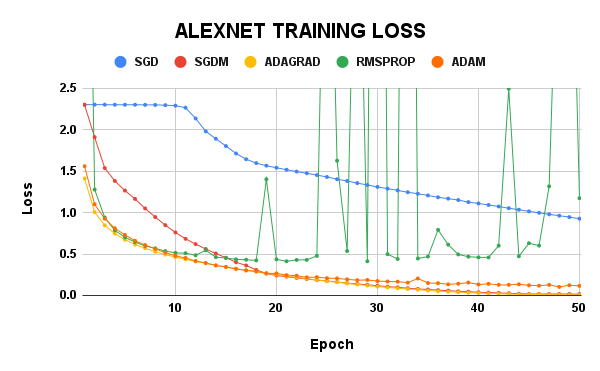
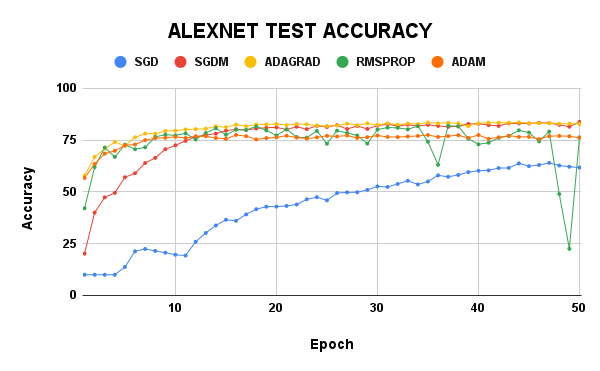
On the LeNet model, the test accuracy of SGDM was the highest at almost 70%, while its training loss was 0.635. Adam had the least training loss, but their test accuracy was just 67%. LeNet with Adagrad was woeful and had a 48% test accuracy which was way lesser than the SGD, which had 54.03%. RMSProp gave a test accuracy of 65% and a train loss of 0.630.
As for the AlexNet model, SGDM still had the best test accuracy of 83.75%, closely followed by Adagrad with 82.79%. However, the training loss of SGD was 0.016 while Adagrad had 0.005, which is so small and gave the model little room for improvement. The Adam result was surprisingly low, given how highly rated it is in the AI sector. RMSProp seemed not to have convergence confidence but had similar test accuracy with Adam.
From the LeNet results, one could have easily concluded that Adagrad is a bad optimizer, and from the AlexNet results, the RMSProp looked like an optimizer capable of helping the model overfit on the training data, but there is more to this than just making this early conclusion. More experiments have to be carried out to investigate this issue.
FURTHER EXPERIMENTS
Due to the results of RMSProp and Adam, while using the AlexNet model, another experiment was carried out, this time using a learning rate of 1e-5.
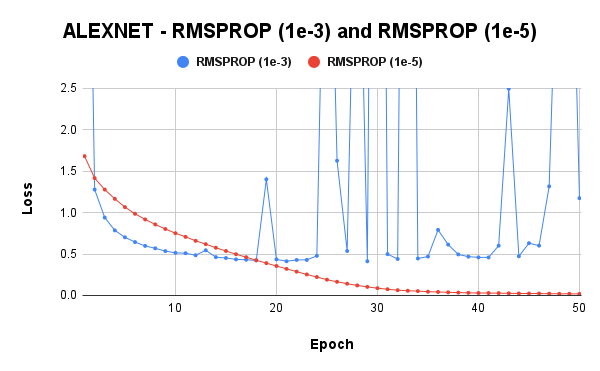
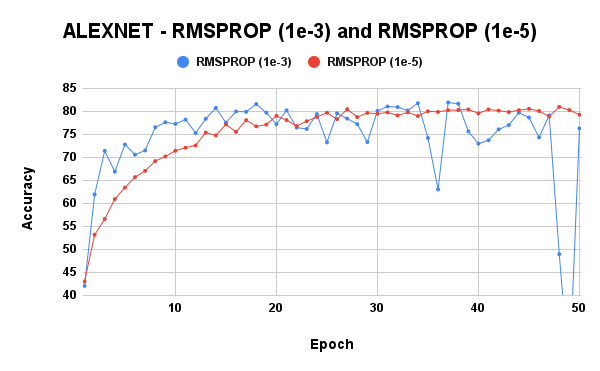
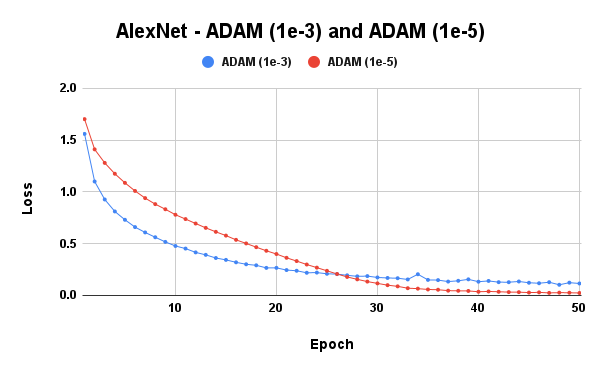
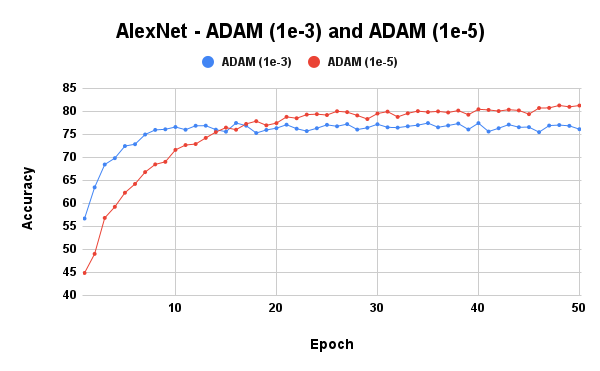
Now, this is more like it. A lower learning rate stabilized the RMSProp optimizer and improved Adam’s performance. We could easily conclude and say it is better to use lower learning rates for optimizers that employ scaling. However, we need to be sure that this isn’t general, so I tried using a lower learning rate with SGDM, and that gave me very poor results. Hence, lower learning rates are better suited for scaling optimizers.
Still, we don’t have enough experiments to make other observations, so in the next section, I will discuss the current observations from the currently short experiments on each optimizer.
DISCUSSIONS AND CONCLUSION
SGD: Not Recommended! While it is sure to converge, it normally takes time to learn. What the SGDM or Adam could learn in 50 epochs, the SGD will learn in about 500 epochs. However, there is a good chance that you can get some decent results when you start with a big learning rate (i.e., 1e-1). You can also use it if you have enough time to wait for convergence; else, stay away.
SGDM: Recommended! This optimizer has given the best results in the experiments. However, it might not work well if the starting learning rate is low. Otherwise, it converges fast and also helps the model’s generalizability. It is totally recommended!
Adagrad: Recommended! From the experiments, it could be said that this optimizer is the worst to use, especially when you are using a small model like LeNet on complex datasets. However, in deeper networks, it could give good results, but optimal performance isn’t guaranteed.
RMSProp: Recommended! This optimizer has also given a very good performance. When used with a lower learning rate, it could give better performances. Asides from the performance, its converging speed is high, and we can see the reason why it is being used sometimes in production sectors (industry).
Adam: Recommended! According to some experts, Adam learns all patterns, including the noise in the train set, and therefore it is fast to converge. However, in the experiments above, we can see that it doesn’t converge as well as the SGDM, but it converges and learns fast. Also, I could bet that its performance on bigger datasets (which would, of course, contain more noise) will be better than the other optimizers discussed above.
With this practical look into the popular optimizers in use today, I hope you have gotten some insights and intuition about why optimizers are needed and how these optimizers affect model performance. If you have suggestions and feedback, please leave a comment or connect with me on LinkedIn. Thank you.
To learn about these optimizers, as well as other optimizers not touched on in this article, please use this link.
To access the codes used here, repository.
Impact of Optimizers in Image Classifiers was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



